实现
最初用了Big Data Europe的docker-spark-hadoop-workbench,但是docker 服务运行后在spark-notebook中运行代码会出现经典异常:
java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD
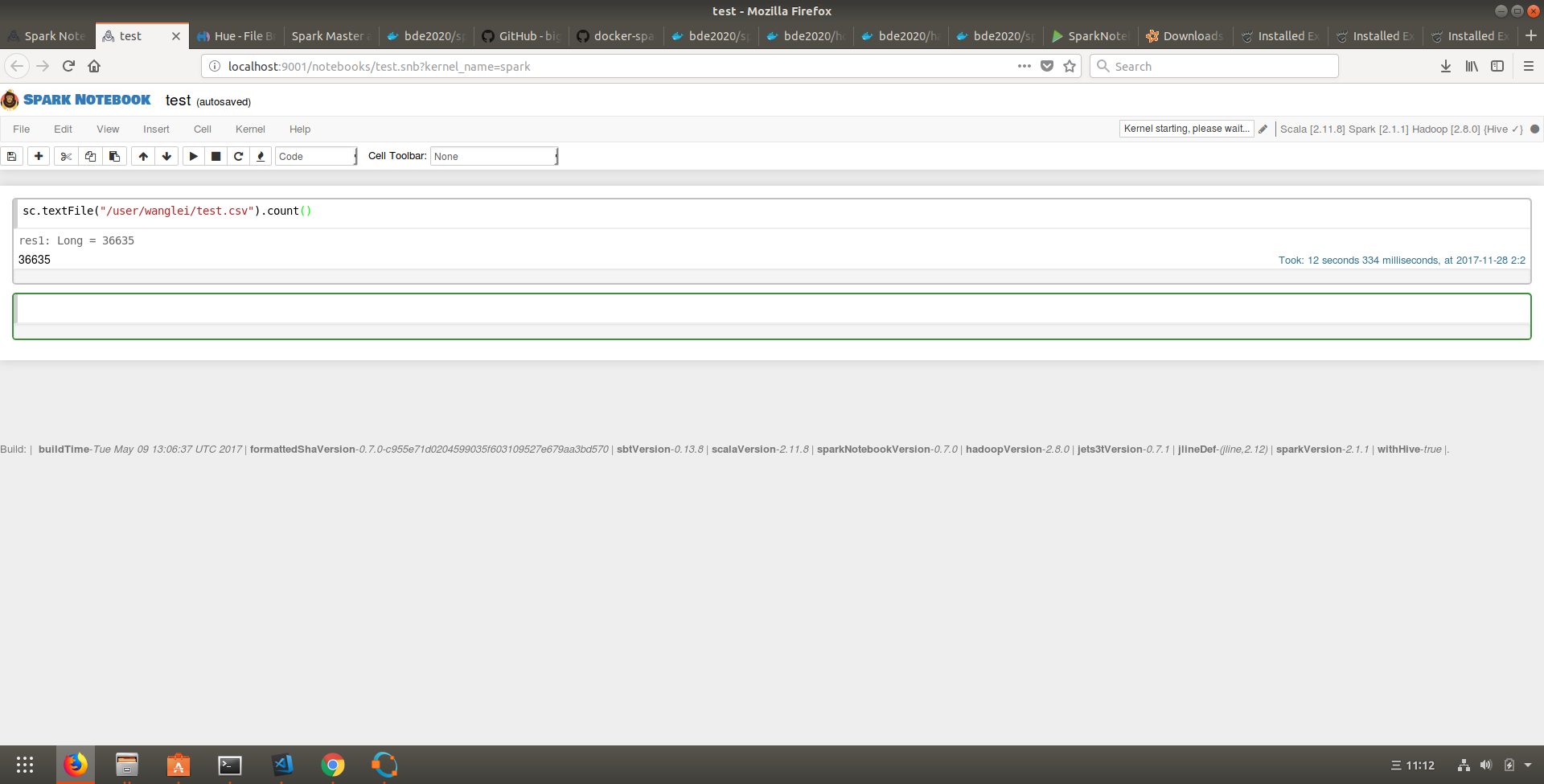
View Code 发现是因为spark-notebook和spark集群使用的spark版本不一致. 于是fork了Big Data Europe的repo,在此基础上做了一些修改,基于spark2.11-hadoop2.7实现了一个可用的workbench. 运行docker服务
 QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2017-12-17 16:31:10
发表于 2017-12-17 16:31:10





 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡