原文链接: http://hortonworks.com/kb/get-started-setting-up-ambari/
Ambari is 100% open source and included in HDP, greatly simplifying installation and initial configuration of Hadoop clusters. In this article we’ll be running through some installation steps to get started with Ambari. Most of the steps here are covered in the main HDP documentation here.
Ambari 是一款100%开源的,包含于HDP平台,使得安装和初始化hadoop集群配置的项目。这篇文章我们将介绍Ambari的安装步骤。这里的大部分内容都包含在HDP的文档中。
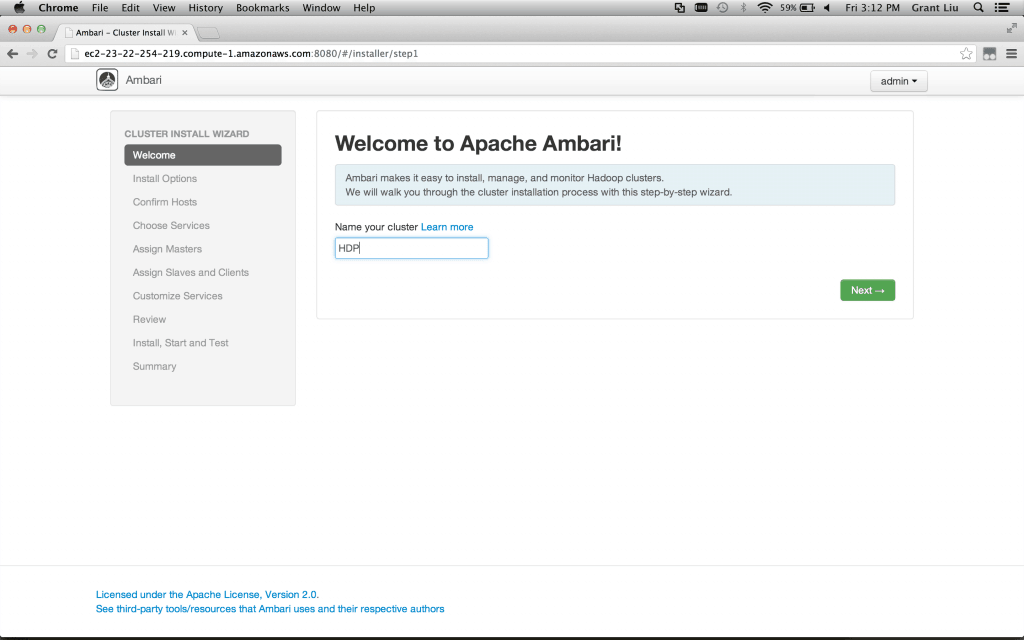
The first order of business is getting Ambari Server itself installed. There are different approaches to this, but for the purposes of this short tour, we’ll assume Ambari is already installed on its own dedicated node somewhere or on one of the nodes on the (future) cluster itself. Instructions can be found under the installation steps linked above. Once Ambari Server is running, the hard work is actually done. Ambari simplifies cluster install and initial configuration with a wizard interface, taking care of it with but a few clicks and decisions from the end user. Hit http://:8080 and log in with admin/admin. Upon logging in, we are greeted with a user-friendly, wizard interface. Welcome to Apache Ambari! Name that cluster and let’s get going.
第一步安装Ambari服务端,我们简单的讲,我们假设Ambari服务端已经成功的安装在专有的节点上,这个节点是集群的一部分。安装方法在上面提到的连接里面。当Ambari服务端运行的时候,负责的工作已经开始了。Ambari提供一个友好的交互入口来简化集群的安装和配置,轻松的操作即可完成配置,具体是,登陆你的节点 http://ip:8080/ 然后使用 admin/admin 登陆系统。登陆后给集群起个名字。
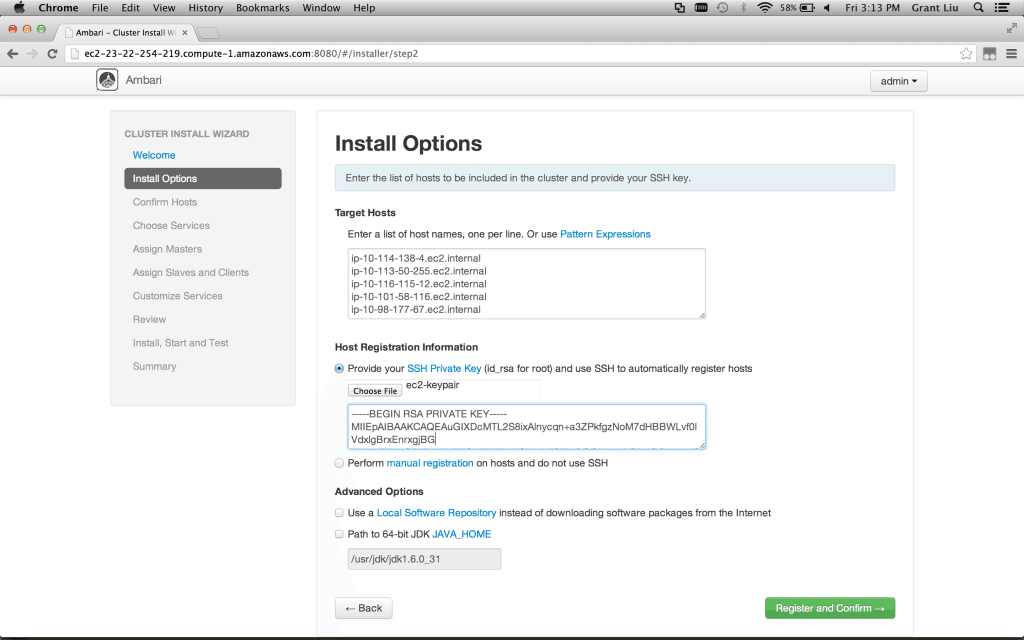
Now we can target hosts for installation with a full listing of host names or regular expressions (in situations when there are many nodes with similar names):
现在我们来配置机器列表(可以使用正则来匹配类似机器名的节点)
The next step is node registration, with Ambari doing all of the heavy lifting for us. An interface to track progress and drill down into log files is made available:
接下来是注册节点,Ambari帮我们做了,提供一个接口可以查看执行进程,
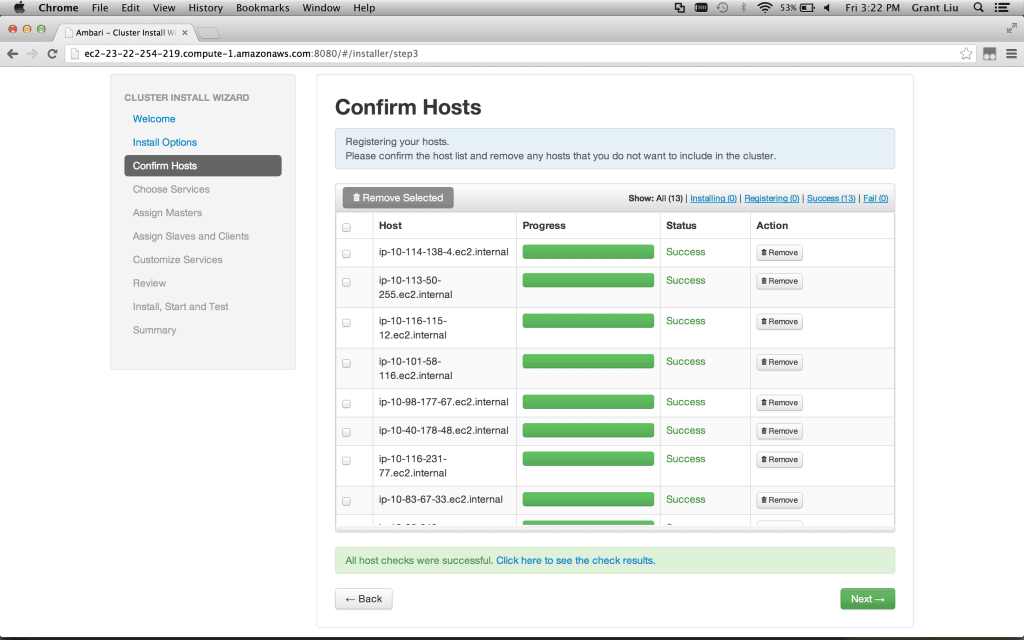
Upon registration completion, a detailed view of host checks run and options to re-run are also available:
当注册完成后,检测当前的机器状态
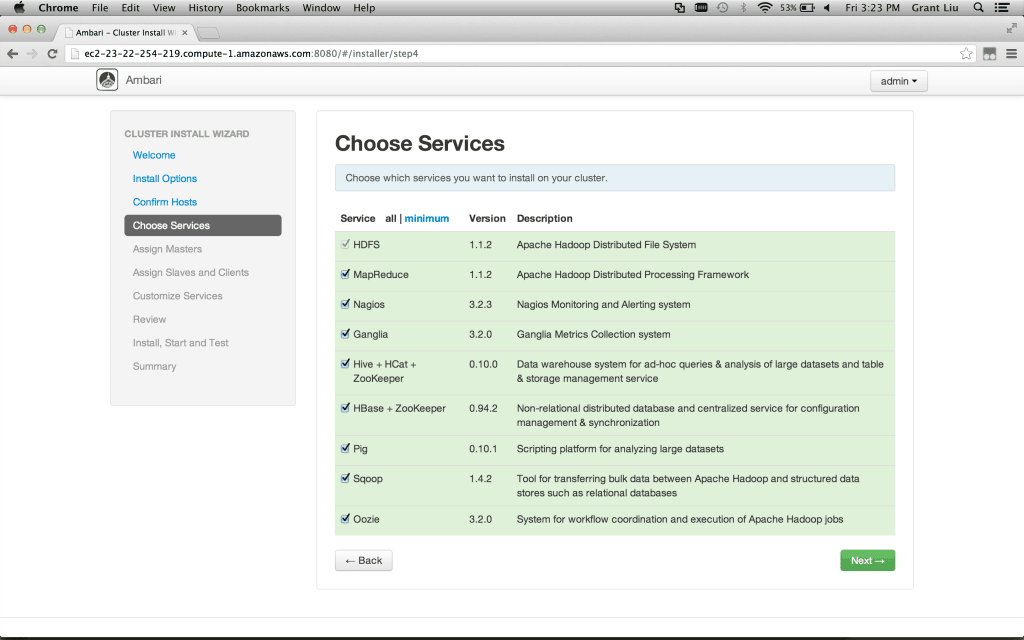
Next, we select which high level components we want for the cluster. Dependency checks are all built in, so no worries about knowing which services are pre-requisites for others:
接下来,我们选择我们需要安装的模块,内置了依赖检查
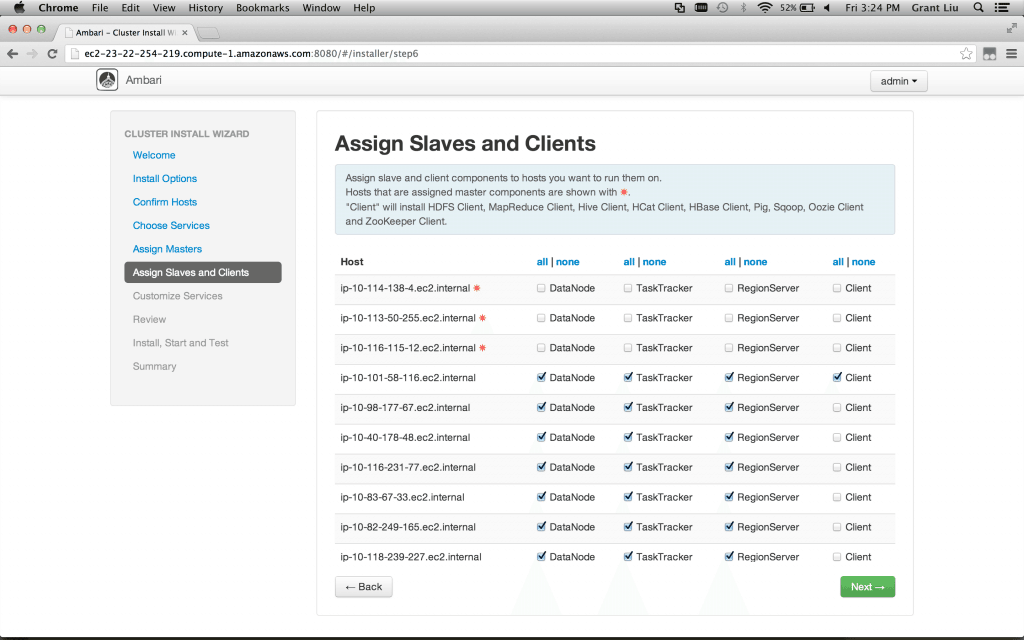
After service selection, node-specific service assignments are as simple as checking boxes:
接下来服务选择,方便定制
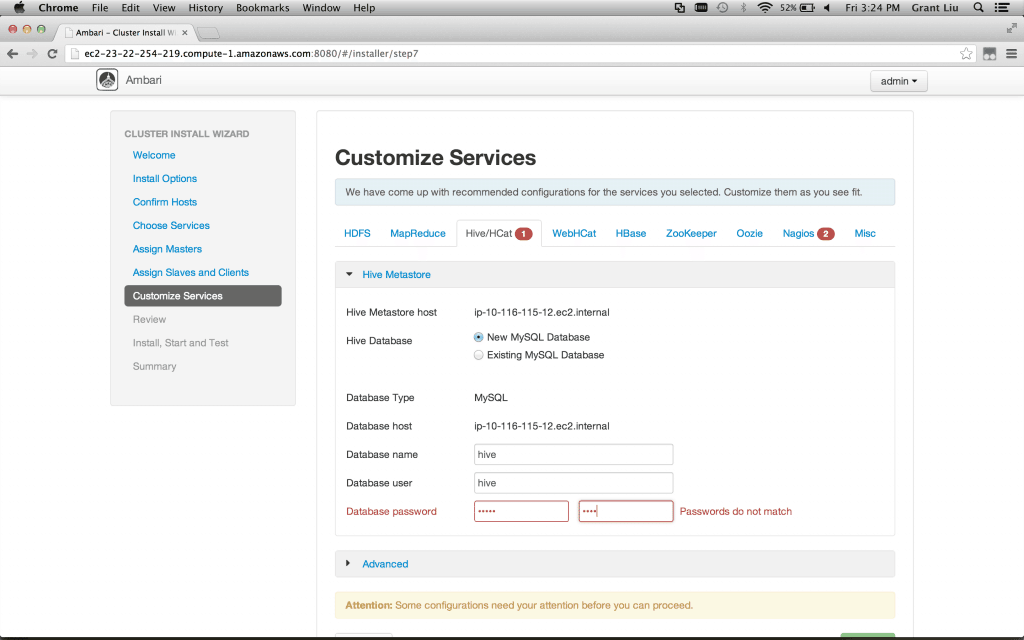
This is where some minor typing may be required. Ambari allows simple configuration of the cluster via an easy to use interface, calling out required fields when necessary:
这里只需要一些简单的输入.当你需要安装服务的时候,Ambari支持在页面上进行便捷的配置.
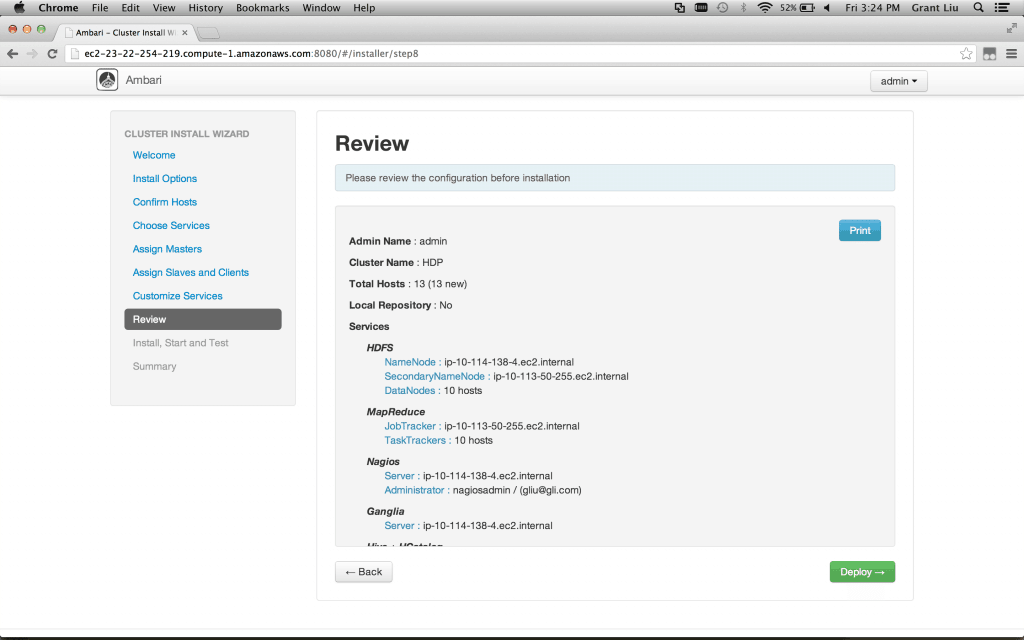
Once configuration has been completed, a review pane is displayed. This is a good point to pause and check for anything that requires adjustment. The Ambari wizard makes that simple. Things look fabulous here, though, so onwards!
当配置完成后,预览将会被隐藏. 这是暂停并开始检测依赖.Ambari引导使得这个显得很简单.虽然刚刚起步,但是看上去很赞.
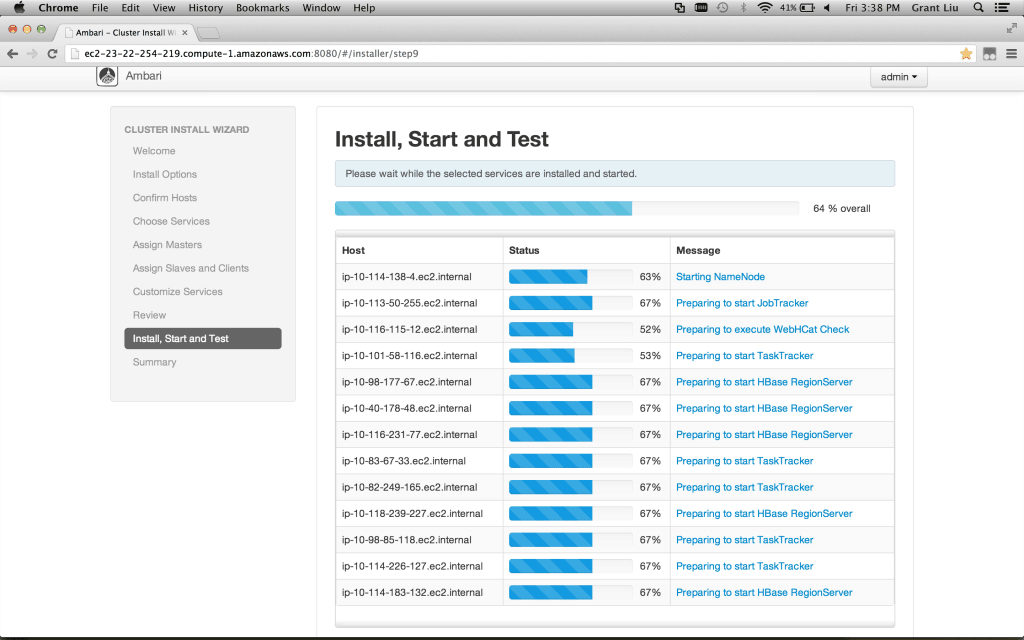
Ambari will now execute the actual installation and necessary smoke tests on all nodes in the cluster. Sit back and relax, Ambari will perform the heavy lifting yet again:
Ambari现在开始支持在集群的所有节点的真实环境下的安装和一些必要的冒烟测试. 坐着放松吓,让Ambari开始做这些繁重的琐事.
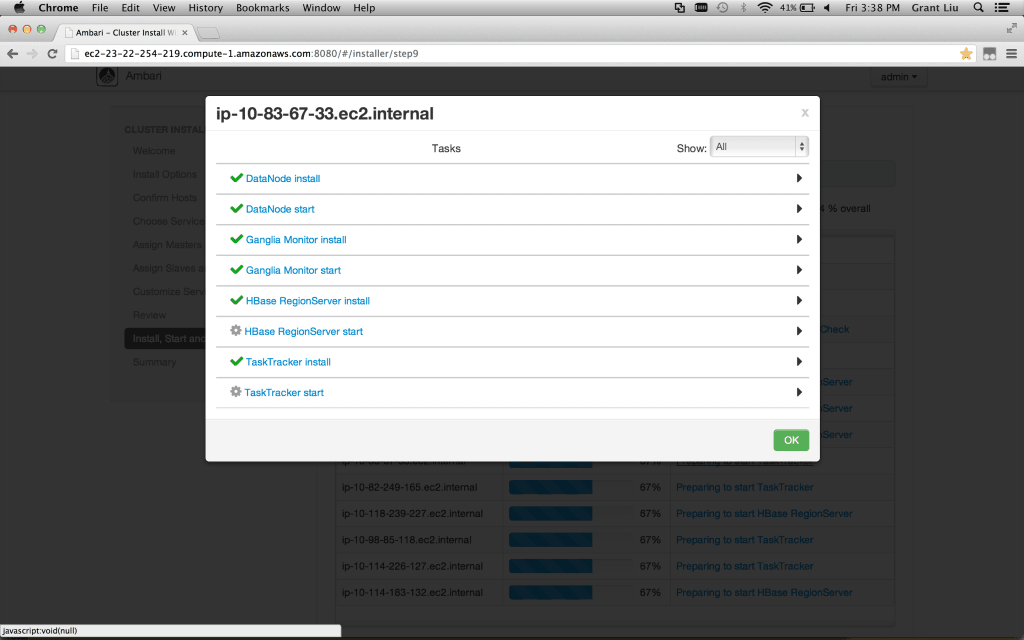
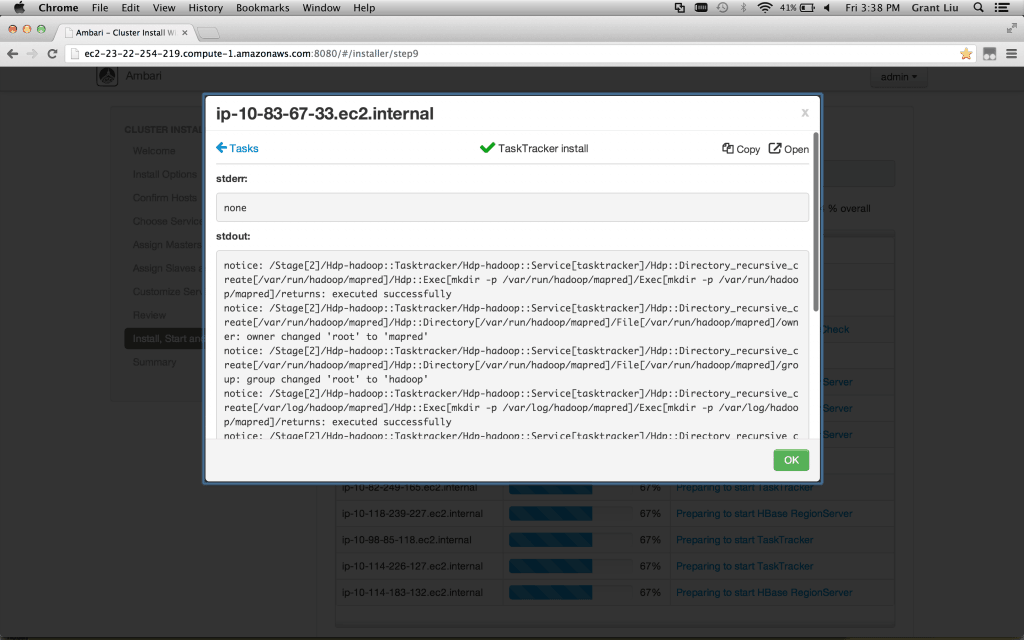
If you are itching to get involved, detailed drill-downs are available to monitor progress:
如果你想在检查下,可以讲这些过程在监控进程中查看到.
Ambari tracks all progress and activities for you, dynamically updating the interface:
Ambari收集所有进程和活动数据,并动态的更新到页面上:
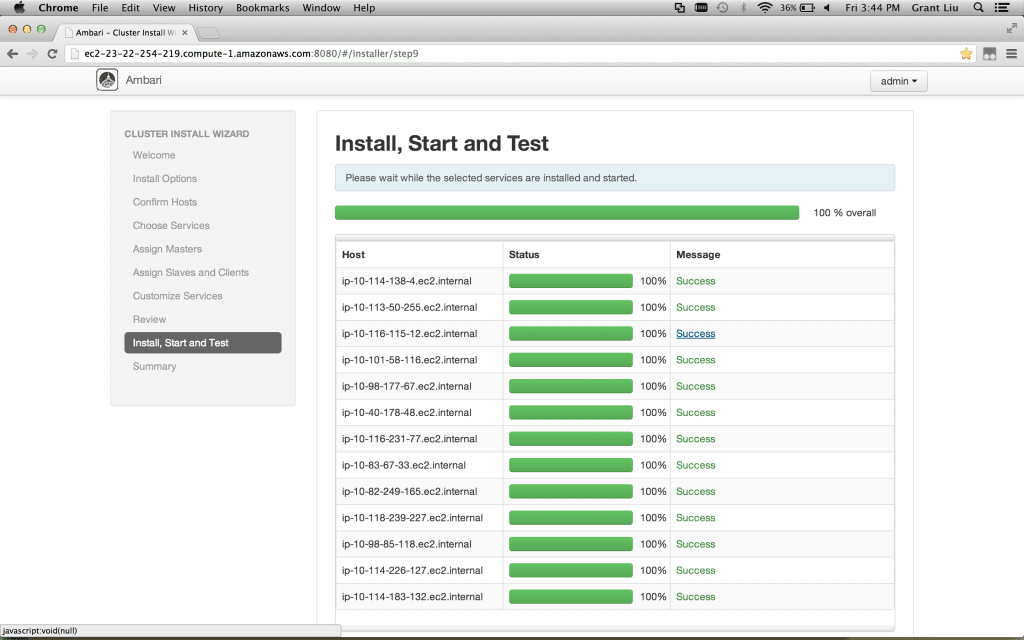
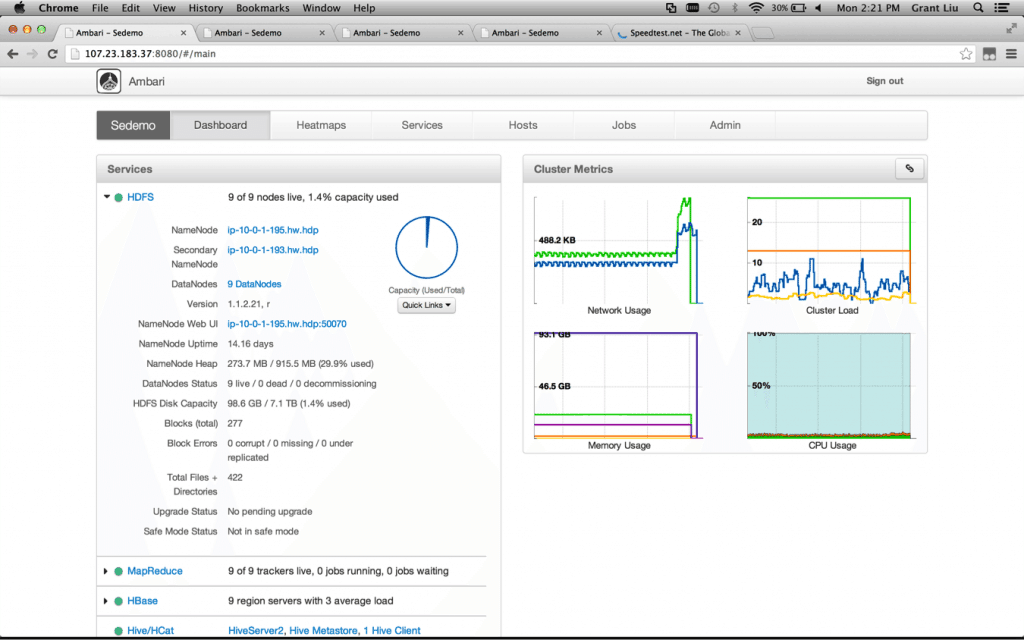
And just like that, we have our Hortonworks Data Platform Cluster up and running, ready for that high priority POC:
如下看到的,你已经讲HDP跑起来了,准备开始干活...
Go forth and prosper, my friends. May the (big) data be with you.
让我们开始和大数据共舞吧!
 QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2015-7-11 10:58:53
发表于 2015-7-11 10:58:53

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡