|
|
来源: Cheeky4n6Monkey
原文跳转: http://cheeky4n6monkey.blogspot.tw/2013/02/creating-perl-script-to-retrieve.html
Creating a Perl script to retrieve Android SMS

This script/post was inspired by Mari DeGrazia after she had to manually parse hundreds of Android SMS messages. Without her prior research and the principles she discusses in her post, there's little chance I would have attempted this script. Thanks for sharing Mari!
This post continues on from where Mari's post ended. We'll look further at an example Android SMS SQLite schema and then use it to explain how our SMS extraction script (sms-grep.pl) works. We will also walk you through how to use our script and what kind of output you can expect.
Introduction
Android stores SMS records in the "sms" table of /data/data/com.android.providers.telephony/databases/mmssms.db. SQLite can also store backups of "sms" table data in the /data/data/com.android.providers.telephony/databases/mmssms.db-journal file (in case it needs to undo a transaction). Journal files are a potential forensic gold mine because they may contain previously deleted data which is no longer visible in the current database.
As far as I'm aware, there is currently no freely available way to easily view/print the sms contents of mmssms.db-journal files.
And while you can query the mmssms.db database directly via SQLite, this will not return any older (deleted) sms entries from database pages which have been since been re-purposed.
Our sms-grep.pl script (available here) seems to work well with mmssms.db and mmssms.db-journal files and also with unallocated space (although file size limited/hardware dependent).
Additionally, our script will interpret date fields and print them in a human readable format so no more hours spent manually checking/converting timestamps!
Our script is also configurable - so you should be able to use it to look at multiple Android SMS SQLite schemas without having to modify the underlying code.
But before we dive into the script - it's probably a good idea to learn about how SQLite stores data ...
The SQLite Basics
The SQLite database file format is described in detail in Richard Drinkwater's blog posts here and here.
There's also some extra information at the official SQLite webpage.
OK, now for the lazy monkeys who couldn't be bothered reading those links ...
The basic summary is that all SQLite databases have a main header section, followed by a bunch of fixed size storage pages.
There are several different types of page but each page is the same size as declared in the header.
One type of page is the "table B-Tree" type which has a 0xD byte flag marker. This type of page is used to store field data from the whole database (ie data from all of the tables) in units called "cells". Consequently, this page type will be used to store "sms" table data and because the page format is common to both mmssms.db and mmssms.db-journal files - our carving job is potentially much simpler.
Pages can also be deleted/re-allocated for another type of page so we must also be vigilant about non-"table B-tree" pages having free space which contains old "table B-tree" cell data. Think of it like file slack except for a database.
A 0xD type (ie "table B-tree") page will look like:
 | | Generic Layout of a 0xD page |
We can see the 0xD byte is followed by:
- 2 bytes containing the 1st free cell offset (0 if full)
- 2 bytes containing the number of used data cells in page
- 2 bytes containing the 1st used cell offset
- 1 byte fragmentation marker
Then depending on the number of used data cells, there will be a series of 2 byte offsets which point to each used data cell (see the green section in the pic). The cell pointer list starts with the closest data cell first and ends with the "1st used offset" data cell. Each used data cell should correspond to a row entry in a table of the database (eg an "sms" row entry).
Following those cell pointers (green), will be any free/unallocated space (blue) followed by the actual data cells (purple). The blue area is where we might see older previously deleted "table B-tree" data.
Breaking it down further, the general form of a data cell (from the purple section) looks like:
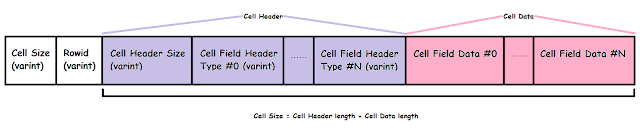 | | Generic Layout of a Cell |
We can see there's a:
- Cell Size (which is the size of the cell header section + cell data section)
- Rowid (ie Primary Key of the row)
- Cell Header section (compromised of a "Cell Header Size" field + a bunch of fields used to describe each type/size of field data)
- Cell Data section (compromised of a bunch of fields containing the actual data)
You might have noticed an unfamiliar term called a "varint".
Varints are type of encoded data and are used to save space. They can be 1 to 9 bytes and require a bit of decoding.
Basically, you read the most significant byte (data is stored big endian) and if it's most significant bit is set to 1, it means there's another byte to follow/include. Then there's a bunch of droppping most significant bits and concatenating the leftovers into a single binary value.
Richard Drinkwater's got a better explanation (with example) here.
Later for our script, we will need to write a function to read these varints but for now, just know that a varint can store anywhere from 1-9 bytes (usually 1-2 bytes though) and it requires some decoding to arrive at the "original value".
So for our Android SMS scenario, a typical used "sms" data cell might look like:
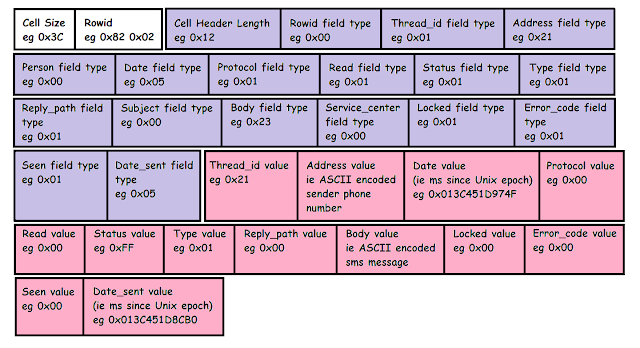 | | Android SMS Cell Example |
You'll notice that there's a "Cell Header" section highlighted in purple and a "Cell Data" section highlighted in pink.
Think of the Cell Header section as a template that tells us how many bytes to expect for each field in the Cell Data section. The Cell Data section does not use varints to store data.
From the sms-cell-example pic, we can see that most of the Cell Header field types are 0x01 - which means those fields use one byte of data in the subsequent cell data section (pink).
The official SQLite documentation refers to these cell header field type values as "Serial Type Codes" and there's a comprehensive definition table about halfway down the page here.
For our sms example, we can see from the purple section that the sms "Read" and "Type" fields will use 1 byte each to store their data in the Cell Data (pink) section. Looking at the pink section confirms this - the "Read" field value is 0 (0 for unread, 1 for read) and the "Type" field is 1 (1 for received, 2 for sent).
As a rule, if the value of the cell header field type (purple section) is between 0x0 and 0x4, the corresponding data field (pink) will use that many bytes (eg 0x1 means 1 byte data field, 0x4 means 4 bytes)
If the value of a cell header field (purple section) is 0x5 (eg "Date" & "Date_sent" fields), it will take 6 bytes in the cell data (pink) section. The "Date" and "Date_sent" data fields are 6 byte Big Endian values which (for Android) contain the number of milliseconds since the Unix epoch (1 Jan 1970).
There's a special case for handling strings. Firstly, the cell header field type value must be odd and greater than or equal to 13. Then to calculate the number of bytes required in the data section we use this:
Number of bytes in string = (cell header field type value - 13)/2.
So in our sms-cell-example pic, the corresponding string size for the "Address" field is (0x21 - 0xD) / 0x2 = (33 - 13) / 2 = 10 bytes. I haven't actually shown a value for the "Address" in the pink section so just use your imagination!
Similarly, we can see that the "Body" field will take (0x23 - D) / 0x2 = (35 - 13) / 2 = 11 bytes.
Note: For long sms, the varint containing the "body" header field type has been observed to require 2 bytes.
You might also have noticed that not all of the cell header fields declared in the cell header section (purple) have a matching entry in the cell data section (pink). This is because if a cell header field is marked as NULL (ie 0x00), it does not get recorded in the cell data section (eg the purple "Rowid" header field's 0x00 value means there won't be a corresponding data field in the pink section).
So if we want to retrieve data, we can't go strictly off the schema - we have to pay attention to the cell header section so we can interpret the cell data fields correctly.
So how do/did we know what cell data field was what?
It turns out that SQLite ensures that the order of cell header fields in the cell header (purple section) is the same order as the database schema field order. Consequently, the cell data section (pink) will also appear in schema order (notwithstanding any missing null fields).
We can get the schema of a database file using the sqlite3 command line exe like this:
sansforensics@SIFT-Workstation:~$ sqlite3 mmssms.db
SQLite version 3.7.11 2012-03-20 11:35:50
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
sqlite> .headers on
sqlite> pragma table_info(sms);
cid|name|type|notnull|dflt_value|pk
0|_id|INTEGER|0||1
1|thread_id|INTEGER|0||0
2|address|TEXT|0||0
3|person|INTEGER|0||0
4|date|INTEGER|0||0
5|protocol|INTEGER|0||0
6|read|INTEGER|0|0|0
7|status|INTEGER|0|-1|0
8|type|INTEGER|0||0
9|reply_path_present|INTEGER|0||0
10|subject|TEXT|0||0
11|body|TEXT|0||0
12|service_center|TEXT|0||0
13|locked|INTEGER|0|0|0
14|error_code|INTEGER|0|0|0
15|seen|INTEGER|0|0|0
16|date_sent|INTEGER|0|0|0
sqlite>
So we can see that the "sms" table consists of 17 fields with the first being the "_id" (ie rowid) primary key and the last being the "date_sent" field. In practice, the "_id" is typically unused/set to NULL as it is just duplicating the Cell's Rowid varint (from the white section). Some fields are declared as INTEGERS and others TEXT. Notice how the "date" and "date_sent" are declared as INTEGERS? These represent ms since UTC.
At this stage, I'm not 100% certain on every field's meaning. We know the "address" field is used to store phone numbers and the "body" field stores the sms text string. From Mari's research we also know that "read" is 1 for a read sms, 0 otherwise and "type" indicates sent (2) or recieved sms (1). That should suffice for now.
So that's the basics of the data structures we will be looking at. In the next section, we'll share some thoughts on the script. Oh goody!
The Script
At first I thought we could find each 0xD page and iterate through the data cells that way but this would miss any old sms messages contained in pages which have since been re-purposed by SQLite. That method would also miss any corrupted/partial pages containing sms in unallocated space.
So to find the sms messages, we are going to have to come up with a way of detecting/printing individual sms data cells.
The strategy we ended up using was based on the "address" field (ie the phone number).
1. We read in our schema and print flags from a configuration file.
2. We create one big string from the nominated input file.
Perl has a handy function called "index" that lets you find out if a given string is contained in a larger string. We use this "index" function to find all phone number matches and their respective file offsets.
3. For each match's file offset, we then work backwards and try to find the cell header size field (ie the start of cell header).
Looking at the sms-cell-example pic, we can see that the "Address" cell value (in pink section) is 18 varint fields AFTER the cell header length/size field (in purple section). The number of varint fields should be constant for a given schema.
4. Now that we've determined the cell header size file offset, we can read in the header field type varints (ie find out how many bytes each field requires/uses in the cell data section) and also read in/store the actual data.
5. We then repeat steps 3 and 4 until we have processed all our search hits.
6. We can then sort the data in chronological order before printing to screen/file.
The main sanity check of this process is checking the cell header size value range. Remember, the cell header size value should tell us the number of bytes required for the entire cell header (including itself). So for our example schema above, this value should be:
- above the 18 byte minimum (ie number of schema fields plus the size of the cell header length = 17 + 1) and
- below a certain threshold (18+5 at this time).
Most "sms" cell header sizes should be 18 bytes (most of the fields are one byte flags) but for longer "body" fields or large "thread_id" field values, multi-byte varints have been observed which would obviously increase number of bytes required for that cell header. Allowing for an extra 5 bytes seemed like a good start for now.
For more information on how the script works (eg see how painful it is to read a multi-byte varint!) you can read the comments in the code. I dare you ;)
Making it Schema Configurable
As Mari has noted, not every Android phone will have the same schema. So instead of having a different script for each schema, we'll be utilising a configuration text file. Think of the configuration file as a kind of plugin for the script. Each phone schema will have it's own configuration file. This file will tell the script:
- what the schema fields are and more importantly, their order,
- which fields are DATES or STRINGS or INTEGERS or mark the PHONE number and
- whether we want to print this field's values
We use the PHONE type marker so the script can work out how many cell header field types it has to skip to get back to the cell header size. This should be declared exactly once (eg "address:PHONE:1").
For possible future needs, we have also declared a "c4n6mtype=android" field. This is in case we need to read an iPhone schema sometime in the future (iPhones use seconds since UTC for their DATE fields).
Here's an example of a configuration file (also provided from my GoogleCode Download page as "sms-grep-sample-config.txt"):
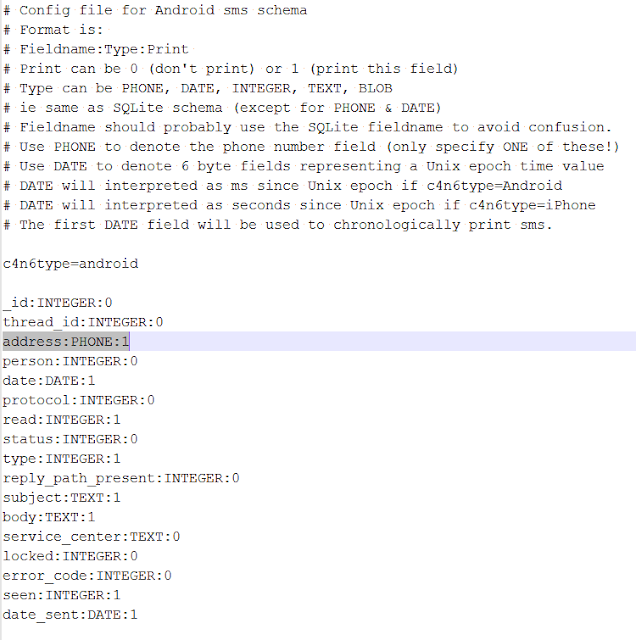 | | Sample Android configuration file |
Notice that it's very similar to the schema we got earlier from sqlite3?
The most significant differences are:
- "address" field (which is now listed as a PHONE type)
- "date" field (which is now listed as a DATE type)
- "date_sent" field (which is now listed as a DATE type)
- the configuration file uses ":" as a field separator (sqlite3 uses "|")
- the print flags (1 prints the field value, 0 does not print)
The script will ignore any blank lines and lines starting with "#".
Running the Script
The first step would be to determine the schema. The easiest way to do this is to use the sqlite3 client with the mmssms.db as previously shown. Admittedly, this requires access to a database file so if your don't have a sample to work with, your out of luck.
Next it's time to create the configuration file - making sure to mark the PHONE field and any DATE fields. Also remember to specify which fields you wish to print.
Once that is done, we can run the script using something like:
perl sms-grep.pl -c config.txt -f mmssms.db -s "5555551234" -s "(555) 555-1234" -o output.tsv
Note: Users can specify multiple phone numbers/formats to search for using -s arguments. At least one -s argument is required.
If no -o argument is specified, the results will be printed to the screen in Tab separated columns - which can get messy with lots of messages. Alternatively, an output Tab separated file (TSV) can be generated (eg using -o output.tsv).
Any extracted hits will be printed in chronological order based upon the first DATE type schema field declared in the configuration file (eg "date" field for our example configuration file). You will probably see multiple entries for the same SMS which was stored at different file offsets. The date sorting makes this situation easier to detect/filter.
Here's a fictional TSV output example based on the previously shown config file:
 | | Fictional sample TSV output from sms-grep.pl |
The arrows in the pic are used by Notepad++ to indicate TABs. We can see that only the print fields marked with a 1 in the configuration file (ie address, date, read, type, subject, body, seen, date_sent) are printed along with the file offset in hex.
Note: If you run the script on a partially complete cell (eg the cell header is truncated by the end of file so there's no corresponding cell data), the script will print out "TRUNCATED" for any strings and -999 for any integer fields. If you see these values, further manual parsing/inspection is recommended.
Testing
Limited testing of the script has been performed with:
- 2 separate Android schemas
- Unallocated space (as retrieved by Cellebrite and exported into a new 600 MB file using X-Ways/WinHex)
- A Raw Cellebrite .bin file (1 GB size)
Note: The script failed to run with a 16 GB .bin file - we suspect this is due to a RAM deficiency in our test PC.
As I don't have an Android phone, I've relied pretty heavily on Mari for testing. We've tested it using ActiveState Perl v5.16 on 64 bit Windows 7 PCs. It should also work on *nix distributions with Perl. I have run it succesfully on SIFT v2.14.
Additionally, an outputted TSV file has also been successfully imported into MS Excel for subsequent analysis.
Validation tips:
grep -oba TERM FILE
Can be used in Linux/SIFT to print the list of search hit file offsets (in decimal).
For example: grep -oba "5555551234" mmssms.db
Additionally, WinHex can be used to search for phone number strings and will also list the location of any hits in a clickable index table. The analyst can then easily compare/check the output of sms-grep.pl.
What it will do
Find sms records to/from given phone numbers with valid formatted cell headers. This includes from both the SQLite database files (ie mmssms.db) and backup journal files (ie mmssms.db-journal). It should also find any existing sms records (with valid headers) that appear in pages which have been since re-allocated by SQLite for new data. Finally, it should also be able to find SMS from unallocated space (assuming the size isn't larger than your hardware can handle).
What it doesn't do very well
If the cell header is corrupted/missing, the script will not detect sms data.
The script does some range checking on the cell header size and prints a warning message if required. However, it is possible to get a false positive (eg phone number string is found and theres a valid cell header size value at the expected cell header size field). This error should be obvious from the output (eg "body" field has nonsensical values). The analyst is encouraged to view any such errors in a Hex viewer to confirm the misinterpreted data.
Unallocated space has proved troublesome due to size limitations. The code reads the input file into one big string for searching purposes, so running out of memory is a possibility when running on large input data such as unallocated. However, if you break up the unallocated space into smaller chunks (eg 1 GB), the script should work OK. I have also used WinHex to copy SMS data out from unallocated and paste it into a separate smaller file. This smaller file was then parsed correctly by our script.
The big string approach seemed like the quickest/easiest way at the time. I was targeting the actual database files/database journals rather than unallocated. So consider unallocated a freebie ;)
We have seen some SQLite sms records from an iPhone 4S which does NOT include the phone numbers. There may be another field we can use instead of phone numbers (perhaps we can use a phone book id?). This requires further investigation/testing.
Final words
As always, you should validate any results you get from your tools (including this one!).
This script was originally created for the purposes of saving time (ie reduce the amount time spent manual parsing sms entries). However, along the way we also learnt more about how SQLite stores data and how we can actually retrieve data that even SQLite doesn't know it still has (eg re-purposed pages).
The past few weeks have flown by. I originally thought we were creating a one-off script for Android but due to the amount of different schemas available, we ended up with something more configurable. This flexibility should also make it easier to adapt this script for future SQLite carving use (provided we know the schema). It doesn't have to be limited to phones!
However, this scripting method relies on providing a search term and knowing what schema field that term will occur in. There's no "magic number" that marks each data cell, so if you don't know/cannot provide that keyword and schema, you are out of luck.
I would be interested to hear any comments/suggestions. It can probably be improved upon but at some point you have to stop tinkering so others can use it and hopefully suggest improvements. If you do have problems with it please let me know. Just a heads up - for serious issues, I probably won't be able to help you unless you supply some test data and the schema.
To any SANS Instructors reading, any chance we can get a shoutout for this in SANS FOR 563? Monkey needs to build some street cred ... ;) |
|
 QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2015-12-26 09:56:53
发表于 2015-12-26 09:56:53
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡