|
|
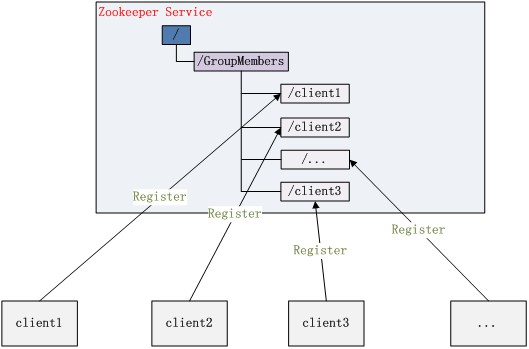
集群管理结构图
清单 3. Leader Election 关键代码
void findLeader() throws InterruptedException {
byte[] leader = null;
try {
leader = zk.getData(root + "/leader", true, null);
} catch (Exception e) {
logger.error(e);
}
if (leader != null) {
following();
} else {
String newLeader = null;
try {
byte[] localhost = InetAddress.getLocalHost().getAddress();
newLeader = zk.create(root + "/leader", localhost,
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
logger.error(e);
}
if (newLeader != null) {
leading();
} else {
mutex.wait();
}
}
}
|
共享锁(Locks)
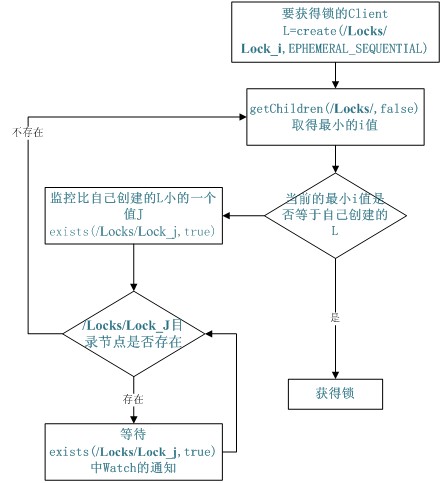
共享锁在同一个进程中很容易实现,但是在跨进程或者在不同 Server 之间就不好实现了。Zookeeper 却很容易实现这个功能,实现方式也是需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
Zookeeper 实现 Locks 的流程图
同步锁的实现代码如下,完整的代码请看源代码:
清单 4. 同步锁的关键代码
void getLock() throws KeeperException, InterruptedException{
List<String> list = zk.getChildren(root, false);
String[] nodes = list.toArray(new String[list.size()]);
Arrays.sort(nodes);
if(myZnode.equals(root+"/"+nodes[0])){
doAction();
}
else{
waitForLock(nodes[0]);
}
}
void waitForLock(String lower) throws InterruptedException, KeeperException {
Stat stat = zk.exists(root + "/" + lower,true);
if(stat != null){
mutex.wait();
}
else{
getLock();
}
}
|
队列管理
Zookeeper 可以处理两种类型的队列:
- 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
同步队列用 Zookeeper 实现的实现思路如下:
创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。
用下面的流程图更容易理解:
同步队列流程图

同步队列的关键代码如下,完整的代码请看附件:
清单 5. 同步队列
void addQueue() throws KeeperException, InterruptedException{
zk.exists(root + "/start",true);
zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
synchronized (mutex) {
List<String> list = zk.getChildren(root, false);
if (list.size() < size) {
mutex.wait();
} else {
zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
}
}
|
当队列没满是进入 wait(),然后会一直等待 Watch 的通知,Watch 的代码如下:
public void process(WatchedEvent event) {
if(event.getPath().equals(root + "/start") &&
event.getType() == Event.EventType.NodeCreated){
System.out.println("得到通知");
super.process(event);
doAction();
}
}
|
FIFO 队列用 Zookeeper 实现思路如下:
实现的思路也非常简单,就是在特定的目录下创建 SEQUENTIAL 类型的子目录 /queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过 getChildren( ) 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证 FIFO。
下面是生产者和消费者这种队列形式的示例代码,完整的代码请看附件:
清单 6. 生产者代码
boolean produce(int i) throws KeeperException, InterruptedException{
ByteBuffer b = ByteBuffer.allocate(4);
byte[] value;
b.putInt(i);
value = b.array();
zk.create(root + "/element", value, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL);
return true;
}
|
清单 7. 消费者代码
int consume() throws KeeperException, InterruptedException{
int retvalue = -1;
Stat stat = null;
while (true) {
synchronized (mutex) {
List<String> list = zk.getChildren(root, true);
if (list.size() == 0) {
mutex.wait();
} else {
Integer min = new Integer(list.get(0).substring(7));
for(String s : list){
Integer tempValue = new Integer(s.substring(7));
if(tempValue < min) min = tempValue;
}
byte[] b = zk.getData(root + "/element" + min,false, stat);
zk.delete(root + "/element" + min, 0);
ByteBuffer buffer = ByteBuffer.wrap(b);
retvalue = buffer.getInt();
return retvalue;
}
}
}
}
|
总结
Zookeeper 作为 Hadoop 项目中的一个子项目,是 Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理 Hadoop 集群中的 NameNode,还有 Hbase 中 Master Election、Server 之间状态同步等。 |
|
|
 QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2017-4-19 11:09:19
发表于 2017-4-19 11:09:19
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡