作者:文兄
链接:https://zhuanlan.zhihu.com/p/25013834
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
初衷
这篇文章主要从工程角度来总结在实际运用机器学习进行预测时,我们可以用哪些tips来提高最终的预测效果,主要分为Data Cleaning,Features Engineering, Models Training三个部分,可以帮助大家在实际的工作中取得更好的预测效果或是在kaggle的比赛里取得更好的成绩和排位。
Data Cleaning
1. 移除多余的duplicate features(相同或极为相似的features)
2. 移除constant features(只有一个value的feature)
#R里面可以使用unique()函数判断,如果返回值为1,则意味着为constant features
3. 移除方差过小的features(方差过小意味着提供信息很有限)
#R中可以使用caret包里的nearZeroVar()函数
#Python里可以使用sklearn包里的VarianceThreshold()函数
4. 缺失值处理:将missing value重新编为一类。
#比如原本-1代表negative,1代表positive,那么missing value就可以全部标记为0
#对于多分类的features做法也类似二分类的做法
#对于numeric values,可以用很大或很小的值代表missing value比如-99999.
5. 填补缺失值
可以用mean,median或者most frequent value进行填补
#R用Hmisc包中的impute()函数
#Python用sklearn中的Imputer()函数
6. 高级的缺失值填补方法
利用其他column的features来填补这个column的缺失值(比如做回归)
#R里面可以用mice包,有很多方法可供选择
注意:不是任何时候填补缺失值都会对最后的模型预测效果带来正的效果,必须进行一定的检验。
Features Engineering
1. Data Transformation
a. Scaling and Standardization
#标准化,R用scale(), Python用StandardScaler()
#注意:Tree based模型无需做标准化
b. Responses Transformation
#当responses展现skewed distribution时候用,使得residual接近normal distribution
#可以用log(x),log(x+1),sqrt(x)等
2. Features Encoding
#把categorical features变成numeric feature
#Label encoding:Python 用 LabelEncoder()和OneHotEncoder(), R用dummyVars()
3. Features Extraction
#主要是针对文本分析
4. Features Selection
a. 方法很多:
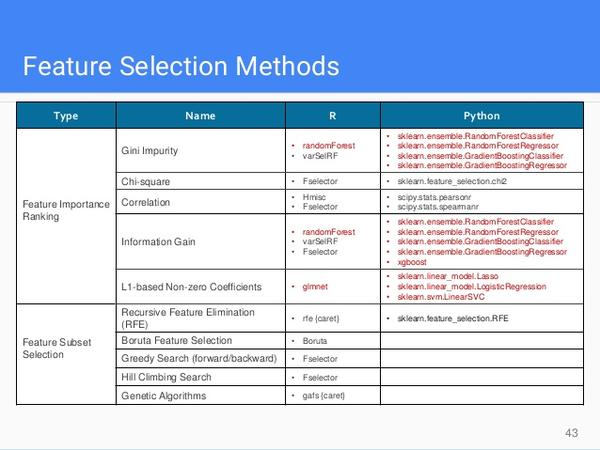 注:其中randomForest以及xgboost里的方法可以判断features的Importance
b. 此外,PCA等方法可以生成指定数量的新features(映射)
c. 擅对features进行visualization或correlation的分析。

Models Trainning
1. Mostly Used ML Models
尝试多一些的模型,比如下面这些:
2. 利用Grid Search进行hyper参数的选择
3. 利用Cross-Validation衡量训练效果
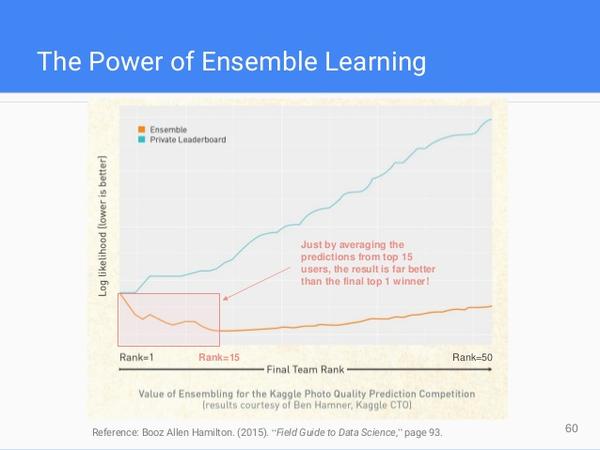
4. Ensemble Learning Methods
必读下面这个文档:Kaggle Ensembling Guide
文章原地址:https://zhuanlan.zhihu.com/p/25013834 |  QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2017-6-21 19:04:47
发表于 2017-6-21 19:04:47

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡