一、损失函数
Loss Function
损失函数可以看做 误差部分(loss term) + 正则化部分(regularization term)
1.1 Loss Term
- Gold Standard (ideal case)
- Hinge (SVM, soft margin)
- Log (logistic regression, cross entropy error)
- Squared loss (linear regression)
- Exponential loss (Boosting)
Gold Standard 又被称为0-1 loss, 记录分类错误的次数
Hinge Loss http://en.wikipedia.org/wiki/Hinge_loss
For an intended output t = ±1 and a classifier score y, the hinge loss of the prediction y is defined as
Note that y should be the "raw" output of the classifier's decision function, not the predicted class label. E.g., in linear SVMs,
It can be seen that when t and y have the same sign (meaning y predicts the right class) and
, the hinge loss
, but when they have opposite sign,
increases linearly with y (one-sided error).
来自 <http://en.wikipedia.org/wiki/Hinge_loss>
Plot of hinge loss (blue) vs. zero-one loss (misclassification, green:y < 0) for t = 1 and variable y. Note that the hinge loss penalizes predictions y < 1, corresponding to the notion of a margin in a support vector machine.
来自 <http://en.wikipedia.org/wiki/Hinge_loss>
在Pegasos: Primal Estimated sub-GrAdient SOlver for SVM论文中
这里把第一部分看成正规化部分,第二部分看成误差部分,注意对比ng关于svm的课件
不考虑规则化
考虑规则化
Log Loss
Ng的课件1,先是讲 linear regression 然后引出最小二乘误差,之后概率角度高斯分布解释最小误差。
然后讲逻辑回归,使用MLE来引出优化目标是使得所见到的训练数据出现概率最大
最大化下面的log似然函数
而这个恰恰就是最小化cross entropy!
http://en.wikipedia.org/wiki/Cross_entropy
http://www.cnblogs.com/rocketfan/p/3350450.html 信息论,交叉熵与KL divergence关系
Cross entropy can be used to define loss function in machine learning and optimization. The true probability
is the true label, and the given distribution
is the predicted value of the current model.
More specifically, let us consider logistic regression, which (in its most basic guise) deals with classifying a given set of data points into two possible classes generically labelled
and
. The logistic regression model thus predicts an output
, given an input vector
. The probability is modeled using thelogistic function
. Namely, the probability of finding the output
is given by
where the vector of weights
is learned through some appropriate algorithm such as gradient descent. Similarly, the conjugate probability of finding the output
is simply given by
The true (observed) probabilities can be expressed similarly as
and
.
Having set up our notation,
and
, we can use cross entropy to get a measure for similarity between
and
:
The typical loss function that one uses in logistic regression is computed by taking the average of all cross-entropies in the sample. For specifically, suppose we have
samples with each sample labeled by
. The loss function is then given by:
where
, with
the logistic function as before.
The logistic loss is sometimes called cross-entropy loss. It's also known as log loss (In this case, the binary label is often denoted by {-1,+1}).[1]
来自 <http://en.wikipedia.org/wiki/Cross_entropy>
因此和ng从MLE角度给出的结论是完全一致的! 差别是最外面的一个负号
也就是逻辑回归的优化目标函数是 交叉熵
修正 14.8这个公式 课件里面应该写错了一点 第一个+ 应该是-,这样对应loss 优化目标是越小越好,MLE对应越大也好。
squared loss
exponential loss
指数误差通常用在boosting中,指数误差始终> 0,但是确保越接近正确的结果误差越小,反之越大。
1.2 正则化部分
监督机器学习问题无非就是“minimizeyour error while regularizing your parameters”,也就是在规则化参数的同时最小化误差。最小化误差是为了让我们的模型拟合我们的训练数据,而规则化参数是防止我们的模型过分拟合我们的训练数据。多么简约的哲学啊!因为参数太多,会导致我们的模型复杂度上升,容易过拟合,也就是我们的训练误差会很小。但训练误差小并不是我们的最终目标,我们的目标是希望模型的测试误差小,也就是能准确的预测新的样本。所以,我们需要保证模型“简单”的基础上最小化训练误差,这样得到的参数才具有好的泛化性能(也就是测试误差也小),而模型“简单”就是通过规则函数来实现的。另外,规则项的使用还可以约束我们的模型的特性。这样就可以将人对这个模型的先验知识融入到模型的学习当中,强行地让学习到的模型具有人想要的特性,例如稀疏、低秩、平滑等等。要知道,有时候人的先验是非常重要的。前人的经验会让你少走很多弯路,这就是为什么我们平时学习最好找个大牛带带的原因。一句点拨可以为我们拨开眼前乌云,还我们一片晴空万里,醍醐灌顶。对机器学习也是一样,如果被我们人稍微点拨一下,它肯定能更快的学习相应的任务。只是由于人和机器的交流目前还没有那么直接的方法,目前这个媒介只能由规则项来担当了。
还有几种角度来看待规则化的。规则化符合奥卡姆剃刀(Occam's razor)原理。这名字好霸气,razor!不过它的思想很平易近人:在所有可能选择的模型中,我们应该选择能够很好地解释已知数据并且十分简单的模型。从贝叶斯估计的角度来看,规则化项对应于模型的先验概率。民间还有个说法就是,规则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项(regularizer)或惩罚项(penalty term)。
一般来说,监督学习可以看做最小化下面的目标函数:
其中,第一项L(yi,f(xi;w)) 衡量我们的模型(分类或者回归)对第i个样本的预测值f(xi;w)和真实的标签yi之前的误差。因为我们的模型是要拟合我们的训练样本的嘛,所以我们要求这一项最小,也就是要求我们的模型尽量的拟合我们的训练数据。但正如上面说言,我们不仅要保证训练误差最小,我们更希望我们的模型测试误差小,所以我们需要加上第二项,也就是对参数w的规则化函数Ω(w)去约束我们的模型尽量的简单。
OK,到这里,如果你在机器学习浴血奋战多年,你会发现,哎哟哟,机器学习的大部分带参模型都和这个不但形似,而且神似。是的,其实大部分无非就是变换这两项而已。对于第一项Loss函数,如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是exp-Loss,那就是牛逼的 Boosting了;如果是log-Loss,那就是Logistic Regression了;还有等等。不同的loss函数,具有不同的拟合特性,这个也得就具体问题具体分析的。但这里,我们先不究loss函数的问题,我们把目光转向“规则项Ω(w)”。
规则化函数Ω(w)也有很多种选择,一般是模型复杂度的单调递增函数,模型越复杂,规则化值就越大。比如,规则化项可以是模型参数向量的范数。然而,不同的选择对参数w的约束不同,取得的效果也不同,但我们在论文中常见的都聚集在:零范数、一范数、二范数、迹范数、Frobenius范数和核范数等等。这么多范数,到底它们表达啥意思?具有啥能力?什么时候才能用?什么时候需要用呢?不急不急,下面我们挑几个常见的娓娓道来。
一、L0范数与L1范数
L0范数是指向量中非0的元素的个数。如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0。这太直观了,太露骨了吧,换句话说,让参数W是稀疏的。OK,看到了“稀疏”二字,大家都应该从当下风风火火的“压缩感知”和“稀疏编码”中醒悟过来,原来用的漫山遍野的“稀疏”就是通过这玩意来实现的。但你又开始怀疑了,是这样吗?看到的papers世界中,稀疏不是都通过L1范数来实现吗?脑海里是不是到处都是||W||1影子呀!几乎是抬头不见低头见。没错,这就是这节的题目把L0和L1放在一起的原因,因为他们有着某种不寻常的关系。那我们再来看看L1范数是什么?它为什么可以实现稀疏?为什么大家都用L1范数去实现稀疏,而不是L0范数呢?
L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。现在我们来分析下这个价值一个亿的问题:为什么L1范数会使权值稀疏?有人可能会这样给你回答“它是L0范数的最优凸近似”。实际上,还存在一个更美的回答:任何的规则化算子,如果他在Wi=0的地方不可微,并且可以分解为一个“求和”的形式,那么这个规则化算子就可以实现稀疏。这说是这么说,W的L1范数是绝对值,|w|在w=0处是不可微,但这还是不够直观。这里因为我们需要和L2范数进行对比分析。所以关于L1范数的直观理解,请待会看看第二节。
对了,上面还有一个问题:既然L0可以实现稀疏,为什么不用L0,而要用L1呢?个人理解一是因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。所以大家才把目光和万千宠爱转于L1范数。
OK,来个一句话总结:L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用。
好,到这里,我们大概知道了L1可以实现稀疏,但我们会想呀,为什么要稀疏?让我们的参数稀疏有什么好处呢?这里扯两点:
1)特征选择(Feature Selection):
大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,xi的大部分元素(也就是特征)都是和最终的输出yi没有关系或者不提供任何信息的,在最小化目标函数的时候考虑xi这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的信息反而会被考虑,从而干扰了对正确yi的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。
2)可解释性(Interpretability):
另一个青睐于稀疏的理由是,模型更容易解释。例如患某种病的概率是y,然后我们收集到的数据x是1000维的,也就是我们需要寻找这1000种因素到底是怎么影响患上这种病的概率的。假设我们这个是个回归模型:y=w1*x1+w2*x2+…+w1000*x1000+b(当然了,为了让y限定在[0,1]的范围,一般还得加个Logistic函数)。通过学习,如果最后学习到的w*就只有很少的非零元素,例如只有5个非零的wi,那么我们就有理由相信,这些对应的特征在患病分析上面提供的信息是巨大的,决策性的。也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。但如果1000个wi都非0,医生面对这1000种因素,累觉不爱。
二、L2范数
除了L1范数,还有一种更受宠幸的规则化范数是L2范数: ||W||2。它也不逊于L1范数,它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。这用的很多吧,因为它的强大功效是改善机器学习里面一个非常重要的问题:过拟合。至于过拟合是什么,上面也解释了,就是模型训练时候的误差很小,但在测试的时候误差很大,也就是我们的模型复杂到可以拟合到我们的所有训练样本了,但在实际预测新的样本的时候,糟糕的一塌糊涂。通俗的讲就是应试能力很强,实际应用能力很差。擅长背诵知识,却不懂得灵活利用知识。例如下图所示(来自Ng的course):
上面的图是线性回归,下面的图是Logistic回归,也可以说是分类的情况。从左到右分别是欠拟合(underfitting,也称High-bias)、合适的拟合和过拟合(overfitting,也称High variance)三种情况。可以看到,如果模型复杂(可以拟合任意的复杂函数),它可以让我们的模型拟合所有的数据点,也就是基本上没有误差。对于回归来说,就是我们的函数曲线通过了所有的数据点,如上图右。对分类来说,就是我们的函数曲线要把所有的数据点都分类正确,如下图右。这两种情况很明显过拟合了。
OK,那现在到我们非常关键的问题了,为什么L2范数可以防止过拟合?回答这个问题之前,我们得先看看L2范数是个什么东西。
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。为什么越小的参数说明模型越简单?我也不懂,我的理解是:限制了参数很小,实际上就限制了多项式某些分量的影响很小(看上面线性回归的模型的那个拟合的图),这样就相当于减少参数个数。其实我也不太懂,希望大家可以指点下。
这里也一句话总结下:通过L2范数,我们可以实现了对模型空间的限制,从而在一定程度上避免了过拟合。
L2范数的好处是什么呢?这里也扯上两点:
1)学习理论的角度:
从学习理论的角度来说,L2范数可以防止过拟合,提升模型的泛化能力。
2)优化计算的角度:
从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题。哎,等等,这condition number是啥?我先google一下哈。
这里我们也故作高雅的来聊聊优化问题。优化有两大难题,一是:局部最小值,二是:ill-condition病态问题。前者俺就不说了,大家都懂吧,我们要找的是全局最小值,如果局部最小值太多,那我们的优化算法就很容易陷入局部最小而不能自拔,这很明显不是观众愿意看到的剧情。那下面我们来聊聊ill-condition。ill-condition对应的是well-condition。那他们分别代表什么?假设我们有个方程组AX=b,我们需要求解X。如果A或者b稍微的改变,会使得X的解发生很大的改变,那么这个方程组系统就是ill-condition的,反之就是well-condition的。我们具体举个例子吧:
咱们先看左边的那个。第一行假设是我们的AX=b,第二行我们稍微改变下b,得到的x和没改变前的差别很大,看到吧。第三行我们稍微改变下系数矩阵A,可以看到结果的变化也很大。换句话来说,这个系统的解对系数矩阵A或者b太敏感了。又因为一般我们的系数矩阵A和b是从实验数据里面估计得到的,所以它是存在误差的,如果我们的系统对这个误差是可以容忍的就还好,但系统对这个误差太敏感了,以至于我们的解的误差更大,那这个解就太不靠谱了。所以这个方程组系统就是ill-conditioned病态的,不正常的,不稳定的,有问题的,哈哈。这清楚了吧。右边那个就叫well-condition的系统了。
还是再啰嗦一下吧,对于一个ill-condition的系统,我的输入稍微改变下,输出就发生很大的改变,这不好啊,这表明我们的系统不能实用啊。你想想看,例如对于一个回归问题y=f(x),我们是用训练样本x去训练模型f,使得y尽量输出我们期待的值,例如0。那假如我们遇到一个样本x’,这个样本和训练样本x差别很小,面对他,系统本应该输出和上面的y差不多的值的,例如0.00001,最后却给我输出了一个0.9999,这很明显不对呀。就好像,你很熟悉的一个人脸上长了个青春痘,你就不认识他了,那你大脑就太差劲了,哈哈。所以如果一个系统是ill-conditioned病态的,我们就会对它的结果产生怀疑。那到底要相信它多少呢?我们得找个标准来衡量吧,因为有些系统的病没那么重,它的结果还是可以相信的,不能一刀切吧。终于回来了,上面的condition number就是拿来衡量ill-condition系统的可信度的。condition number衡量的是输入发生微小变化的时候,输出会发生多大的变化。也就是系统对微小变化的敏感度。condition number值小的就是well-conditioned的,大的就是ill-conditioned的。
如果方阵A是非奇异的,那么A的conditionnumber定义为:
也就是矩阵A的norm乘以它的逆的norm。所以具体的值是多少,就要看你选择的norm是什么了。如果方阵A是奇异的,那么A的condition number就是正无穷大了。实际上,每一个可逆方阵都存在一个condition number。但如果要计算它,我们需要先知道这个方阵的norm(范数)和Machine Epsilon(机器的精度)。为什么要范数?范数就相当于衡量一个矩阵的大小,我们知道矩阵是没有大小的,当上面不是要衡量一个矩阵A或者向量b变化的时候,我们的解x变化的大小吗?所以肯定得要有一个东西来度量矩阵和向量的大小吧?对了,他就是范数,表示矩阵大小或者向量长度。OK,经过比较简单的证明,对于AX=b,我们可以得到以下的结论:
也就是我们的解x的相对变化和A或者b的相对变化是有像上面那样的关系的,其中k(A)的值就相当于倍率,看到了吗?相当于x变化的界。
对condition number来个一句话总结:conditionnumber是一个矩阵(或者它所描述的线性系统)的稳定性或者敏感度的度量,如果一个矩阵的condition number在1附近,那么它就是well-conditioned的,如果远大于1,那么它就是ill-conditioned的,如果一个系统是ill-conditioned的,它的输出结果就不要太相信了。
好了,对这么一个东西,已经说了好多了。对了,我们为什么聊到这个的了?回到第一句话:从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题。因为目标函数如果是二次的,对于线性回归来说,那实际上是有解析解的,求导并令导数等于零即可得到最优解为:
然而,如果当我们的样本X的数目比每个样本的维度还要小的时候,矩阵XTX将会不是满秩的,也就是XTX会变得不可逆,所以w*就没办法直接计算出来了。或者更确切地说,将会有无穷多个解(因为我们方程组的个数小于未知数的个数)。也就是说,我们的数据不足以确定一个解,如果我们从所有可行解里随机选一个的话,很可能并不是真正好的解,总而言之,我们过拟合了。
但如果加上L2规则项,就变成了下面这种情况,就可以直接求逆了:
这里面,专业点的描述是:要得到这个解,我们通常并不直接求矩阵的逆,而是通过解线性方程组的方式(例如高斯消元法)来计算。考虑没有规则项的时候,也就是λ=0的情况,如果矩阵XTX的 condition number 很大的话,解线性方程组就会在数值上相当不稳定,而这个规则项的引入则可以改善condition number。
另外,如果使用迭代优化的算法,condition number 太大仍然会导致问题:它会拖慢迭代的收敛速度,而规则项从优化的角度来看,实际上是将目标函数变成λ-strongly convex(λ强凸)的了。哎哟哟,这里又出现个λ强凸,啥叫λ强凸呢?
当f满足:
时,我们称f为λ-stronglyconvex函数,其中参数λ>0。当λ=0时退回到普通convex 函数的定义。
在直观的说明强凸之前,我们先看看普通的凸是怎样的。假设我们让f在x的地方做一阶泰勒近似(一阶泰勒展开忘了吗?f(x)=f(a)+f'(a)(x-a)+o(||x-a||).):
直观来讲,convex 性质是指函数曲线位于该点处的切线,也就是线性近似之上,而 strongly convex 则进一步要求位于该处的一个二次函数上方,也就是说要求函数不要太“平坦”而是可以保证有一定的“向上弯曲”的趋势。专业点说,就是convex 可以保证函数在任意一点都处于它的一阶泰勒函数之上,而strongly convex可以保证函数在任意一点都存在一个非常漂亮的二次下界quadratic lower bound。当然这是一个很强的假设,但是同时也是非常重要的假设。可能还不好理解,那我们画个图来形象的理解下。
大家一看到上面这个图就全明白了吧。不用我啰嗦了吧。还是啰嗦一下吧。我们取我们的最优解w*的地方。如果我们的函数f(w),见左图,也就是红色那个函数,都会位于蓝色虚线的那根二次函数之上,这样就算wt和w*离的比较近的时候,f(wt)和f(w*)的值差别还是挺大的,也就是会保证在我们的最优解w*附近的时候,还存在较大的梯度值,这样我们才可以在比较少的迭代次数内达到w*。但对于右图,红色的函数f(w)只约束在一个线性的蓝色虚线之上,假设是如右图的很不幸的情况(非常平坦),那在wt还离我们的最优点w*很远的时候,我们的近似梯度(f(wt)-f(w*))/(wt-w*)就已经非常小了,在wt处的近似梯度∂f/∂w就更小了,这样通过梯度下降wt+1=wt-α*(∂f/∂w),我们得到的结果就是w的变化非常缓慢,像蜗牛一样,非常缓慢的向我们的最优点w*爬动,那在有限的迭代时间内,它离我们的最优点还是很远。
所以仅仅靠convex 性质并不能保证在梯度下降和有限的迭代次数的情况下得到的点w会是一个比较好的全局最小点w*的近似点(插个话,有地方说,实际上让迭代在接近最优的地方停止,也是一种规则化或者提高泛化性能的方法)。正如上面分析的那样,如果f(w)在全局最小点w*周围是非常平坦的情况的话,我们有可能会找到一个很远的点。但如果我们有“强凸”的话,就能对情况做一些控制,我们就可以得到一个更好的近似解。至于有多好嘛,这里面有一个bound,这个 bound 的好坏也要取决于strongly convex性质中的常数α的大小。看到这里,不知道大家学聪明了没有。如果要获得strongly convex怎么做?最简单的就是往里面加入一项(α/2)*||w||2。
呃,讲个strongly convex花了那么多的篇幅。实际上,在梯度下降中,目标函数收敛速率的上界实际上是和矩阵XTX的 condition number有关,XTX的 condition number 越小,上界就越小,也就是收敛速度会越快。
这一个优化说了那么多的东西。还是来个一句话总结吧:L2范数不但可以防止过拟合,还可以让我们的优化求解变得稳定和快速。
好了,这里兑现上面的承诺,来直观的聊聊L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?我看到的有两种几何上直观的解析:
1)下降速度:
我们知道,L1和L2都是规则化的方式,我们将权值参数以L1或者L2的方式放到代价函数里面去。然后模型就会尝试去最小化这些权值参数。而这个最小化就像一个下坡的过程,L1和L2的差别就在于这个“坡”不同,如下图:L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近,L1的下降速度比L2的下降速度要快。所以会非常快得降到0。不过我觉得这里解释的不太中肯,当然了也不知道是不是自己理解的问题。
L1在江湖上人称Lasso,L2人称Ridge。不过这两个名字还挺让人迷糊的,看上面的图片,Lasso的图看起来就像ridge,而ridge的图看起来就像lasso。
2)模型空间的限制:
实际上,对于L1和L2规则化的代价函数来说,我们可以写成以下形式:
也就是说,我们将模型空间限制在w的一个L1-ball 中。为了便于可视化,我们考虑两维的情况,在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解:
可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交。注意到在角的位置就会产生稀疏性,例如图中的相交点就有w1=0,而更高维的时候(想象一下三维的L1-ball 是什么样的?)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性。
相比之下,L2-ball 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。这就从直观上来解释了为什么L1-regularization 能产生稀疏性,而L2-regularization 不行的原因了。
因此,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
而Lp正则则是更加宽泛的存在,L1、L2都来源与Lp正则,式子如下:
其他几阶的正则化比较少用,且增大计算量,切不符合防止过拟合的思想。就不再介绍。
三、核范数
核范数||W||*是指矩阵奇异值的和,英文称呼叫Nuclear Norm。这个相对于上面火热的L1和L2来说,可能大家就会陌生点。那它是干嘛用的呢?霸气登场:约束Low-Rank(低秩)。OK,OK,那我们得知道Low-Rank是啥?用来干啥的?
我们先来回忆下线性代数里面“秩”到底是啥?举个简单的例子吧:
对上面的线性方程组,第一个方程和第二个方程有不同的解,而第2个方程和第3个方程的解完全相同。从这个意义上说,第3个方程是“多余”的,因为它没有带来任何的信息量,把它去掉,所得的方程组与原来的方程组同解。为了从方程组中去掉多余的方程,自然就导出了“矩阵的秩”这一概念。
还记得我们怎么手工求矩阵的秩吗?为了求矩阵A的秩,我们是通过矩阵初等变换把A化为阶梯型矩阵,若该阶梯型矩阵有r个非零行,那A的秩rank(A)就等于r。从物理意义上讲,矩阵的秩度量的就是矩阵的行列之间的相关性。如果矩阵的各行或列是线性无关的,矩阵就是满秩的,也就是秩等于行数。回到上面线性方程组来说吧,因为线性方程组可以用矩阵描述嘛。秩就表示了有多少个有用的方程了。上面的方程组有3个方程,实际上只有2个是有用的,一个是多余的,所以对应的矩阵的秩就是2了。
OK。既然秩可以度量相关性,而矩阵的相关性实际上有带有了矩阵的结构信息。如果矩阵之间各行的相关性很强,那么就表示这个矩阵实际可以投影到更低维的线性子空间,也就是用几个向量就可以完全表达了,它就是低秩的。所以我们总结的一点就是:如果矩阵表达的是结构性信息,例如图像、用户-推荐表等等,那么这个矩阵各行之间存在这一定的相关性,那这个矩阵一般就是低秩的。
如果X是一个m行n列的数值矩阵,rank(X)是X的秩,假如rank (X)远小于m和n,则我们称X是低秩矩阵。低秩矩阵每行或每列都可以用其他的行或列线性表出,可见它包含大量的冗余信息。利用这种冗余信息,可以对缺失数据进行恢复,也可以对数据进行特征提取。
好了,低秩有了,那约束低秩只是约束rank(w)呀,和我们这节的核范数有什么关系呢?他们的关系和L0与L1的关系一样。因为rank()是非凸的,在优化问题里面很难求解,那么就需要寻找它的凸近似来近似它了。对,你没猜错,rank(w)的凸近似就是核范数||W||*。
好了,到这里,我也没什么好说的了,因为我也是稍微翻看了下这个东西,所以也还没有深入去看它。但我发现了这玩意还有很多很有意思的应用,下面我们举几个典型的吧。
1)矩阵填充(Matrix Completion):
我们首先说说矩阵填充用在哪。一个主流的应用是在推荐系统里面。我们知道,推荐系统有一种方法是通过分析用户的历史记录来给用户推荐的。例如我们在看一部电影的时候,如果喜欢看,就会给它打个分,例如3颗星。然后系统,例如Netflix等知名网站就会分析这些数据,看看到底每部影片的题材到底是怎样的?针对每个人,喜欢怎样的电影,然后会给对应的用户推荐相似题材的电影。但有一个问题是:我们的网站上面有非常多的用户,也有非常多的影片,不是所有的用户都看过说有的电影,不是所有看过某电影的用户都会给它评分。假设我们用一个“用户-影片”的矩阵来描述这些记录,例如下图,可以看到,会有很多空白的地方。如果这些空白的地方存在,我们是很难对这个矩阵进行分析的,所以在分析之前,一般需要先对其进行补全。也叫矩阵填充。
那到底怎么填呢?如何才能无中生有呢?每个空白的地方的信息是否蕴含在其他已有的信息之上了呢?如果有,怎么提取出来呢?Yeah,这就是低秩生效的地方了。这叫低秩矩阵重构问题,它可以用如下的模型表述:已知数据是一个给定的m*n矩阵A,如果其中一些元素因为某种原因丢失了,我们能否根据其他行和列的元素,将这些元素恢复?当然,如果没有其他的参考条件,想要确定这些数据很困难。但如果我们已知A的秩rank(A)<<m且rank(A)<<n,那么我们可以通过矩阵各行(列)之间的线性相关将丢失的元素求出。你会问,这种假定我们要恢复的矩阵是低秩的,合理吗?实际上是十分合理的,比如一个用户对某电影评分是其他用户对这部电影评分的线性组合。所以,通过低秩重构就可以预测用户对其未评价过的视频的喜好程度。从而对矩阵进行填充。
2)鲁棒PCA:
主成分分析,这种方法可以有效的找出数据中最“主要"的元素和结构,去除噪音和冗余,将原有的复杂数据降维,揭示隐藏在复杂数据背后的简单结构。我们知道,最简单的主成分分析方法就是PCA了。从线性代数的角度看,PCA的目标就是使用另一组基去重新描述得到的数据空间。希望在这组新的基下,能尽量揭示原有的数据间的关系。这个维度即最重要的“主元"。PCA的目标就是找到这样的“主元”,最大程度的去除冗余和噪音的干扰。
鲁棒主成分分析(Robust PCA)考虑的是这样一个问题:一般我们的数据矩阵X会包含结构信息,也包含噪声。那么我们可以将这个矩阵分解为两个矩阵相加,一个是低秩的(由于内部有一定的结构信息,造成各行或列间是线性相关的),另一个是稀疏的(由于含有噪声,而噪声是稀疏的),则鲁棒主成分分析可以写成以下的优化问题:
与经典PCA问题一样,鲁棒PCA本质上也是寻找数据在低维空间上的最佳投影问题。对于低秩数据观测矩阵X,假如X受到随机(稀疏)噪声的影响,则X的低秩性就会破坏,使X变成满秩的。所以我们就需要将X分解成包含其真实结构的低秩矩阵和稀疏噪声矩阵之和。找到了低秩矩阵,实际上就找到了数据的本质低维空间。那有了PCA,为什么还有这个Robust PCA呢?Robust在哪?因为PCA假设我们的数据的噪声是高斯的,对于大的噪声或者严重的离群点,PCA会被它影响,导致无法正常工作。而Robust PCA则不存在这个假设。它只是假设它的噪声是稀疏的,而不管噪声的强弱如何。
由于rank和L0范数在优化上存在非凸和非光滑特性,所以我们一般将它转换成求解以下一个松弛的凸优化问题:
说个应用吧。考虑同一副人脸的多幅图像,如果将每一副人脸图像看成是一个行向量,并将这些向量组成一个矩阵的话,那么可以肯定,理论上,这个矩阵应当是低秩的。但是,由于在实际操作中,每幅图像会受到一定程度的影响,例如遮挡,噪声,光照变化,平移等。这些干扰因素的作用可以看做是一个噪声矩阵的作用。所以我们可以把我们的同一个人脸的多个不同情况下的图片各自拉长一列,然后摆成一个矩阵,对这个矩阵进行低秩和稀疏的分解,就可以得到干净的人脸图像(低秩矩阵)和噪声的矩阵了(稀疏矩阵),例如光照,遮挡等等。至于这个的用途,你懂得。
3)背景建模:
背景建模的最简单情形是从固定摄相机拍摄的视频中分离背景和前景。我们将视频图像序列的每一帧图像像素值拉成一个列向量,那么多个帧也就是多个列向量就组成了一个观测矩阵。由于背景比较稳定,图像序列帧与帧之间具有极大的相似性,所以仅由背景像素组成的矩阵具有低秩特性;同时由于前景是移动的物体,占据像素比例较低,故前景像素组成的矩阵具有稀疏特性。视频观测矩阵就是这两种特性矩阵的叠加,因此,可以说视频背景建模实现的过程就是低秩矩阵恢复的过程。
4)变换不变低秩纹理(TILT):
以上章节所介绍的针对图像的低秩逼近算法,仅仅考虑图像样本之间像素的相似性,却没有考虑到图像作为二维的像素集合,其本身所具有的规律性。事实上,对于未加旋转的图像,由于图像的对称性与自相似性,我们可以将其看做是一个带噪声的低秩矩阵。当图像由端正发生旋转时,图像的对称性和规律性就会被破坏,也就是说各行像素间的线性相关性被破坏,因此矩阵的秩就会增加。
低秩纹理映射算法(TransformInvariant Low-rank Textures,TILT)是一种用低秩性与噪声的稀疏性进行低秩纹理恢复的算法。它的思想是通过几何变换τ把D所代表的图像区域校正成正则的区域,如具有横平竖直、对称等特性,这些特性可以通过低秩性来进行刻画。
低秩的应用非常多,大家有兴趣的可以去找些资料深入了解下。
四、规则化参数的选择
现在我们回过头来看看我们的目标函数:
里面除了loss和规则项两块外,还有一个参数λ。它也有个霸气的名字,叫hyper-parameters(超参)。你不要看它势单力薄的,它非常重要。它的取值很大时候会决定我们的模型的性能,事关模型生死。它主要是平衡loss和规则项这两项的,λ越大,就表示规则项要比模型训练误差更重要,也就是相比于要模型拟合我们的数据,我们更希望我们的模型能满足我们约束的Ω(w)的特性。反之亦然。举个极端情况,例如λ=0时,就没有后面那一项,代价函数的最小化全部取决于第一项,也就是集全力使得输出和期待输出差别最小,那什么时候差别最小啊,当然是我们的函数或者曲线可以经过所有的点了,这时候误差就接近0,也就是过拟合了。它可以复杂的代表或者记忆所有这些样本,但对于一个新来的样本泛化能力就不行了。毕竟新的样本会和训练样本有差别的嘛。
那我们真正需要什么呢?我们希望我们的模型既可以拟合我们的数据,又具有我们约束它的特性。只有它们两者的完美结合,才能让我们的模型在我们的任务上发挥强大的性能。所以如何讨好它,是非常重要。在这点上,大家可能深有体会。还记得你复现了很多论文,然后复现出来的代码跑出来的准确率没有论文说的那么高,甚至还差之万里。这时候,你就会怀疑,到底是论文的问题,还是你实现的问题?实际上,除了这两个问题,我们还需要深入思考另一个问题:论文提出的模型是否具有hyper-parameters?论文给出了它们的实验取值了吗?经验取值还是经过交叉验证的取值?这个问题是逃不掉的,因为几乎任何一个问题或者模型都会具有hyper-parameters,只是有时候它是隐藏着的,你看不到而已,但一旦你发现了,证明你俩有缘,那请试着去修改下它吧,有可能有“奇迹”发生哦。
OK,回到问题本身。我们选择参数λ的目标是什么?我们希望模型的训练误差和泛化能力都很强。这时候,你有可能还反映过来,这不是说我们的泛化性能是我们的参数λ的函数吗?那我们为什么按优化那一套,选择能最大化泛化性能的λ呢?Oh,sorry to tell you that,因为泛化性能并不是λ的简单的函数!它具有很多的局部最大值!而且它的搜索空间很大。所以大家确定参数的时候,一是尝试很多的经验值,这和那些在这个领域摸爬打滚的大师是没得比的。当然了,对于某些模型,大师们也整理了些调参经验给我们。例如Hinton大哥的那篇A Practical Guide to Training RestrictedBoltzmann Machines等等。还有一种方法是通过分析我们的模型来选择。怎么做呢?就是在训练之前,我们大概计算下这时候的loss项的值是多少?Ω(w)的值是多少?然后针对他们的比例来确定我们的λ,这种启发式的方法会缩小我们的搜索空间。另外一种最常见的方法就是交叉验证Cross validation了。先把我们的训练数据库分成几份,然后取一部分做训练集,一部分做测试集,然后选择不同的λ用这个训练集来训练N个模型,然后用这个测试集来测试我们的模型,取N模型里面的测试误差最小对应的λ来作为我们最终的λ。如果我们的模型一次训练时间就很长了,那么很明显在有限的时间内,我们只能测试非常少的λ。例如假设我们的模型需要训练1天,这在深度学习里面是家常便饭了,然后我们有一个星期,那我们只能测试7个不同的λ。这就让你遇到最好的λ那是上辈子积下来的福气了。那有什么方法呢?两种:一是尽量测试7个比较靠谱的λ,或者说λ的搜索空间我们尽量广点,所以一般对λ的搜索空间的选择一般就是2的多少次方了,从-10到10啊什么的。但这种方法还是不大靠谱,最好的方法还是尽量让我们的模型训练的时间减少。例如假设我们优化了我们的模型训练,使得我们的训练时间减少到2个小时。那么一个星期我们就可以对模型训练7*24/2=84次,也就是说,我们可以在84个λ里面寻找最好的λ。这让你遇见最好的λ的概率就大多了吧。这就是为什么我们要选择优化也就是收敛速度快的算法,为什么要用GPU、多核、集群等来进行模型训练、为什么具有强大计算机资源的工业界能做很多学术界也做不了的事情(当然了,大数据也是一个原因)的原因了。
努力做个“调参”高手吧!祝愿大家都能“调得一手好参”!
二、优化算法
我们每个人都会在我们的生活或者工作中遇到各种各样的最优化问题,比如每个企业和个人都要考虑的一个问题“在一定成本下,如何使利润最大化”等。最优化方法是一种数学方法,它是研究在给定约束之下如何寻求某些因素(的量),以使某一(或某些)指标达到最优的一些学科的总称。随着学习的深入,博主越来越发现最优化方法的重要性,学习和工作中遇到的大多问题都可以建模成一种最优化模型进行求解,比如我们现在学习的机器学习算法,大部分的机器学习算法的本质都是建立优化模型,通过最优化方法对目标函数(或损失函数)进行优化,从而训练出最好的模型。常见的最优化方法有梯度下降法、牛顿法和拟牛顿法、共轭梯度法等等。
1. 梯度下降法(Gradient Descent)
梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。梯度下降法的搜索迭代示意图如下图所示:
牛顿法的缺点:
(1)靠近极小值时收敛速度减慢,如下图所示;
(2)直线搜索时可能会产生一些问题;
(3)可能会“之字形”地下降。
从上图可以看出,梯度下降法在接近最优解的区域收敛速度明显变慢,利用梯度下降法求解需要很多次的迭代。
在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
比如对一个线性回归(Linear Logistics)模型,假设下面的h(x)是要拟合的函数,J(theta)为损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(theta)就出来了。其中m是训练集的样本个数,n是特征的个数。
1)批量梯度下降法(Batch Gradient Descent,BGD)
(1)将J(theta)对theta求偏导,得到每个theta对应的的梯度:
(2)由于是要最小化风险函数,所以按每个参数theta的梯度负方向,来更新每个theta:
(3)从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度会相当的慢。所以,这就引入了另外一种方法——随机梯度下降。
对于批量梯度下降法,样本个数m,x为n维向量,一次迭代需要把m个样本全部带入计算,迭代一次计算量为m*n2。
2)随机梯度下降(Random Gradient Descent,RGD)
(1)上面的风险函数可以写成如下这种形式,损失函数对应的是训练集中每个样本的粒度,而上面批量梯度下降对应的是所有的训练样本:
(2)每个样本的损失函数,对theta求偏导得到对应梯度,来更新theta:
(3)随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
随机梯度下降每次迭代只使用一个样本,迭代一次计算量为n2,当样本个数m很大的时候,随机梯度下降迭代一次的速度要远高于批量梯度下降方法。两者的关系可以这样理解:随机梯度下降方法以损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了总体的优化效率的提升。增加的迭代次数远远小于样本的数量。
对批量梯度下降法和随机梯度下降法的总结:
批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小,但是对于大规模样本问题效率低下。
随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。
小批量梯度下降---最小化子集样本的损失函数,加入随机性,性能介于上面两者之间。
2. 牛顿法和拟牛顿法(Newton's method & Quasi-Newton Methods)
1)牛顿法(Newton's method)
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。
具体步骤:
首先,选择一个接近函数 f (x)零点的 x0,计算相应的 f (x0) 和切线斜率f ' (x0)(这里f ' 表示函数 f 的导数)。然后我们计算穿过点(x0, f (x0)) 并且斜率为f '(x0)的直线和 x 轴的交点的x坐标,也就是求如下方程的解:
我们将新求得的点的 x 坐标命名为x1,通常x1会比x0更接近方程f (x) = 0的解。因此我们现在可以利用x1开始下一轮迭代。迭代公式可化简为如下所示:
已经证明,如果f ' 是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值x0位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果f ' (x)不为0, 那么牛顿法将具有平方收敛的性能. 粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。下图为一个牛顿法执行过程的例子。
由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。牛顿法的搜索路径(二维情况)如下图所示:
牛顿法搜索动态示例图:
关于牛顿法和梯度下降法的效率对比:
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
注:红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
2)拟牛顿法(Quasi-Newton Methods)
拟牛顿法是求解非线性优化问题最有效的方法之一,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。Davidon设计的这种算法在当时看来是非线性优化领域最具创造性的发明之一。不久R. Fletcher和M. J. D. Powell证实了这种新的算法远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
具体步骤:
拟牛顿法的基本思想如下。首先构造目标函数在当前迭代xk的二次模型:

这里Bk是一个对称正定矩阵,于是我们取这个二次模型的最优解作为搜索方向,并且得到新的迭代点:

其中我们要求步长ak
满足Wolfe条件。这样的迭代与牛顿法类似,区别就在于用近似的Hesse矩阵Bk
代替真实的Hesse矩阵。所以拟牛顿法最关键的地方就是每一步迭代中矩阵Bk
的更新。现在假设得到一个新的迭代xk+1,并得到一个新的二次模型:

我们尽可能地利用上一步的信息来选取Bk。具体地,我们要求

从而得到

这个公式被称为割线方程。常用的拟牛顿法有DFP算法和BFGS算法。
3. 共轭梯度法(Conjugate Gradient)
共轭梯度法是介于最速下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
具体的实现步骤请参加wiki百科共轭梯度法。
下图为共轭梯度法和梯度下降法搜索最优解的路径对比示意图:
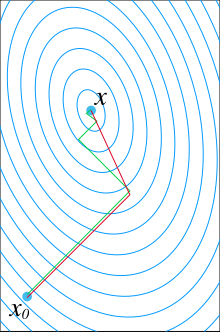
注:绿色为梯度下降法,红色代表共轭梯度法。
4、进化算法
启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等等。还有一种特殊的优化算法被称之多目标优化算法,它主要针对同时优化多个目标(两个及两个以上)的优化问题,这方面比较经典的算法有NSGAII算法、MOEA/D算法以及人工免疫算法等。
详细请见http://www.cnblogs.com/maybe2030/p/4665837.html
5、拉格朗日乘数法
详情见http://www.cnblogs.com/maybe2030/p/4946256.html
三、模型
机器学习中,模型的选择相对比较少,一般分为生成式模型和判断式模型,生成式模型用联合概率或者函数来表示,判别式模型一般用条件概率。当然也有很多其他分类方法,这里不再赘述,其作用并不大。
机器学习算法太多了,分类、回归、聚类、推荐、图像识别领域等等,要想找到一个合适算法真的不容易,所以在实际应用中,我们一般都是采用启发式学习方式来实验。通常最开始我们都会选择大家普遍认同的算法,诸如SVM,GBDT,Adaboost,现在深度学习很火热,神经网络也是一个不错的选择。假如你在乎精度(accuracy)的话,最好的方法就是通过交叉验证(cross-validation)对各个算法一个个地进行测试,进行比较,然后调整参数确保每个算法达到最优解,最后选择最好的一个。但是如果你只是在寻找一个“足够好”的算法来解决你的问题,或者这里有些技巧可以参考,下面来分析下各个算法的优缺点,基于算法的优缺点,更易于我们去选择它。
偏差&方差
在统计学中,一个模型好坏,是根据偏差和方差来衡量的,所以我们先来普及一下偏差(bias)和方差(variance):
- 偏差:描述的是预测值(估计值)的期望E’与真实值Y之间的差距。偏差越大,越偏离真实数据。
- 方差:描述的是预测值P的变化范围,离散程度,是预测值的方差,也就是离其期望值E的距离。方差越大,数据的分布越分散。
模型的真实误差是两者之和,如公式:
通常情况下,如果是小训练集,高偏差/低方差的分类器(例如,朴素贝叶斯NB)要比低偏差/高方差大分类的优势大(例如,KNN),因为后者会发生过拟合(overfiting)。然而,随着你训练集的增长,模型对于原数据的预测能力就越好,偏差就会降低,此时低偏差/高方差的分类器就会渐渐的表现其优势(因为它们有较低的渐近误差),而高偏差分类器这时已经不足以提供准确的模型了。
当然,你也可以认为这是生成模型(如NB)与判别模型(如KNN)的一个区别。
为什么说朴素贝叶斯是高偏差低方差?
以下内容引自知乎:
首先,假设你知道训练集和测试集的关系。简单来讲是我们要在训练集上学习一个模型,然后拿到测试集去用,效果好不好要根据测试集的错误率来衡量。但很多时候,我们只能假设测试集和训练集的是符合同一个数据分布的,但却拿不到真正的测试数据。这时候怎么在只看到训练错误率的情况下,去衡量测试错误率呢?
由于训练样本很少(至少不足够多),所以通过训练集得到的模型,总不是真正正确的。(就算在训练集上正确率100%,也不能说明它刻画了真实的数据分布,要知道刻画真实的数据分布才是我们的目的,而不是只刻画训练集的有限的数据点)。而且,实际中,训练样本往往还有一定的噪音误差,所以如果太追求在训练集上的完美而采用一个很复杂的模型,会使得模型把训练集里面的误差都当成了真实的数据分布特征,从而得到错误的数据分布估计。这样的话,到了真正的测试集上就错的一塌糊涂了(这种现象叫过拟合)。但是也不能用太简单的模型,否则在数据分布比较复杂的时候,模型就不足以刻画数据分布了(体现为连在训练集上的错误率都很高,这种现象较欠拟合)。过拟合表明采用的模型比真实的数据分布更复杂,而欠拟合表示采用的模型比真实的数据分布要简单。
在统计学习框架下,大家刻画模型复杂度的时候,有这么个观点,认为Error = Bias Variance。这里的Error大概可以理解为模型的预测错误率,是有两部分组成的,一部分是由于模型太简单而带来的估计不准确的部分(Bias),另一部分是由于模型太复杂而带来的更大的变化空间和不确定性(Variance)。
所以,这样就容易分析朴素贝叶斯了。它简单的假设了各个数据之间是无关的,是一个被严重简化了的模型。所以,对于这样一个简单模型,大部分场合都会Bias部分大于Variance部分,也就是说高偏差而低方差。
在实际中,为了让Error尽量小,我们在选择模型的时候需要平衡Bias和Variance所占的比例,也就是平衡over-fitting和under-fitting。
偏差、方差、模型复杂度三者之间的关系使用下图表示会更容易理解:
当模型复杂度上升的时候,偏差会逐渐变小,而方差会逐渐变大。
常见算法优缺点
1. 朴素贝叶斯
朴素贝叶斯属于生成式模型(关于生成模型和判别式模型,主要还是在于是否需要求联合分布),比较简单,你只需做一堆计数即可。如果注有条件独立性假设(一个比较严格的条件),朴素贝叶斯分类器的收敛速度将快于判别模型,比如逻辑回归,所以你只需要较少的训练数据即可。即使NB条件独立假设不成立,NB分类器在实践中仍然表现的很出色。它的主要缺点是它不能学习特征间的相互作用,用mRMR中R来讲,就是特征冗余。引用一个比较经典的例子,比如,虽然你喜欢Brad Pitt和Tom Cruise的电影,但是它不能学习出你不喜欢他们在一起演的电影。
优点:
- 朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。
- 对小规模的数据表现很好,能个处理多分类任务,适合增量式训练;
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
缺点:
- 需要计算先验概率;
- 分类决策存在错误率;
- 对输入数据的表达形式很敏感。
2. Logistic Regression(逻辑回归)
逻辑回归属于判别式模型,同时伴有很多模型正则化的方法(L0, L1,L2,etc),而且你不必像在用朴素贝叶斯那样担心你的特征是否相关。与决策树、SVM相比,你还会得到一个不错的概率解释,你甚至可以轻松地利用新数据来更新模型(使用在线梯度下降算法-online gradient descent)。如果你需要一个概率架构(比如,简单地调节分类阈值,指明不确定性,或者是要获得置信区间),或者你希望以后将更多的训练数据快速整合到模型中去,那么使用它吧。
Sigmoid函数:表达式为公式.
优点:
- 实现简单,广泛的应用于工业问题上;
- 分类时计算量非常小,速度很快,存储资源低;
- 便利的观测样本概率分数;
- 对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题;
缺点:
- 当特征空间很大时,逻辑回归的性能不是很好;
- 容易欠拟合,一般准确度不太高
- 不能很好地处理大量多类特征或变量;
- 只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
- 对于非线性特征,需要进行转换;
3. 线性回归
线性回归是用于回归的,它不像Logistic回归那样用于分类,其基本思想是用梯度下降法对最小二乘法形式的误差函数进行优化,当然也可以用normal equation直接求得参数的解,结果为:
而在LWLR(局部加权线性回归)中,参数的计算表达式为:
由此可见LWLR与LR不同,LWLR是一个非参数模型,因为每次进行回归计算都要遍历训练样本至少一次。
优点: 实现简单,计算简单;
缺点: 不能拟合非线性数据.
4. 最近邻算法——KNN
KNN即最近邻算法,其主要过程为:
1. 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);
2. 对上面所有的距离值进行排序(升序);
3. 选前k个最小距离的样本;
4. 根据这k个样本的标签进行投票,得到最后的分类类别;
如何选择一个最佳的K值,这取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响,但会使类别之间的界限变得模糊。一个较好的K值可通过各种启发式技术来获取,比如,交叉验证。另外噪声和非相关性特征向量的存在会使K近邻算法的准确性减小。近邻算法具有较强的一致性结果,随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些好的K值,K近邻保证错误率不会超过贝叶斯理论误差率。
KNN算法的优点
- 理论成熟,思想简单,既可以用来做分类也可以用来做回归;
- 可用于非线性分类;
- 训练时间复杂度为O(n);
- 对数据没有假设,准确度高,对outlier不敏感;
缺点
- 计算量大(体现在距离计算上);
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)效果差;
- 需要大量内存;
5. 决策树
决策树的一大优势就是易于解释。它可以毫无压力地处理特征间的交互关系并且是非参数化的,因此你不必担心异常值或者数据是否线性可分(举个例子,决策树能轻松处理好类别A在某个特征维度x的末端,类别B在中间,然后类别A又出现在特征维度x前端的情况)。它的缺点之一就是不支持在线学习,于是在新样本到来后,决策树需要全部重建。另一个缺点就是容易出现过拟合,但这也就是诸如随机森林RF(或提升树boosted tree)之类的集成方法的切入点。另外,随机森林经常是很多分类问题的赢家(通常比支持向量机好上那么一丁点),它训练快速并且可调,同时你无须担心要像支持向量机那样调一大堆参数,所以在以前都一直很受欢迎。
决策树中很重要的一点就是选择一个属性进行分枝,因此要注意一下信息增益的计算公式,并深入理解它。
信息熵的计算公式如下:
其中的n代表有n个分类类别(比如假设是二类问题,那么n=2)。分别计算这2类样本在总样本中出现的概率p1和p2,这样就可以计算出未选中属性分枝前的信息熵。
现在选中一个属性$x_i$用来进行分枝,此时分枝规则是:如果$x_i=v$的话,将样本分到树的一个分支;如果不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别,分别计算这2个分支的熵H1和H2,计算出分枝后的总信息熵H’ =p1 H1 p2 H2,则此时的信息增益ΔH = H – H’。以信息增益为原则,把所有的属性都测试一边,选择一个使增益最大的属性作为本次分枝属性。
决策树自身的优点
- 计算简单,易于理解,可解释性强;
- 比较适合处理有缺失属性的样本;
- 能够处理不相关的特征;
- 在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
缺点
- 容易发生过拟合(随机森林可以很大程度上减少过拟合);
- 忽略了数据之间的相关性;
- 对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征(只要是使用了信息增益,都有这个缺点,如RF)。
5.1 Adaboosting
Adaboost是一种加和模型,每个模型都是基于上一次模型的错误率来建立的,过分关注分错的样本,而对正确分类的样本减少关注度,逐次迭代之后,可以得到一个相对较好的模型。该算法是一种典型的boosting算法,其加和理论的优势可以使用Hoeffding不等式得以解释。有兴趣的同学可以阅读下笔者后面写的这篇文章Adaboost – 新的角度理解权值更新策略.下面总结下它的优缺点。
优点
- Adaboost是一种有很高精度的分类器。
- 可以使用各种方法构建子分类器,Adaboost算法提供的是框架。
- 当使用简单分类器时,计算出的结果是可以理解的,并且弱分类器的构造极其简单。
- 简单,不用做特征筛选。
- 不易发生overfitting。
关于随机森林和GBDT等组合算法,参考这篇文章:机器学习-组合算法总结
缺点:对outlier比较敏感
6. SVM支持向量机
支持向量机,一个经久不衰的算法,高准确率,为避免过拟合提供了很好的理论保证,而且就算数据在原特征空间线性不可分,只要给个合适的核函数,它就能运行得很好。在动辄超高维的文本分类问题中特别受欢迎。可惜内存消耗大,难以解释,运行和调参也有些烦人,而随机森林却刚好避开了这些缺点,比较实用。
优点
- 可以解决高维问题,即大型特征空间;
- 能够处理非线性特征的相互作用;
- 无需依赖整个数据;
- 可以提高泛化能力;
缺点
- 当观测样本很多时,效率并不是很高;
- 对非线性问题没有通用解决方案,有时候很难找到一个合适的核函数;
- 对缺失数据敏感;
对于核的选择也是有技巧的(libsvm中自带了四种核函数:线性核、多项式核、RBF以及sigmoid核):
- 第一,如果样本数量小于特征数,那么就没必要选择非线性核,简单的使用线性核就可以了;
- 第二,如果样本数量大于特征数目,这时可以使用非线性核,将样本映射到更高维度,一般可以得到更好的结果;
- 第三,如果样本数目和特征数目相等,该情况可以使用非线性核,原理和第二种一样。
对于第一种情况,也可以先对数据进行降维,然后使用非线性核,这也是一种方法。
7. 人工神经网络的优缺点
人工神经网络的优点:
- 分类的准确度高;
- 并行分布处理能力强,分布存储及学习能力强,
- 对噪声神经有较强的鲁棒性和容错能力,能充分逼近复杂的非线性关系;
- 具备联想记忆的功能。
人工神经网络的缺点:
- 神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值;
- 不能观察之间的学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度;
- 学习时间过长,甚至可能达不到学习的目的。
8. K-Means聚类
之前笔者写过一篇关于K-Means聚类的文章,参见机器学习算法-K-means聚类。关于K-Means的推导,里面可是有大学问的,蕴含着强大的EM思想。
优点
- 算法简单,容易实现 ;
- 对处理大数据集,该算法是相对可伸缩的和高效率的,因为它的复杂度大约是O(nkt),其中n是所有对象的数目,k是簇的数目,t是迭代的次数。通常k<<n。这个算法通常局部收敛。
- 算法尝试找出使平方误差函数值最小的k个划分。当簇是密集的、球状或团状的,且簇与簇之间区别明显时,聚类效果较好。
缺点
- 对数据类型要求较高,适合数值型数据;
- 可能收敛到局部最小值,在大规模数据上收敛较慢
- K值比较难以选取;
- 对初值的簇心值敏感,对于不同的初始值,可能会导致不同的聚类结果;
- 不适合于发现非凸面形状的簇,或者大小差别很大的簇。
- 对于”噪声”和孤立点数据敏感,少量的该类数据能够对平均值产生极大影响。
算法选择参考
之前笔者翻译过一些国外的文章,其中有一篇文章中给出了一个简单的算法选择技巧:
- 首当其冲应该选择的就是逻辑回归,如果它的效果不怎么样,那么可以将它的结果作为基准来参考,在基础上与其他算法进行比较;
- 然后试试决策树(随机森林)看看是否可以大幅度提升你的模型性能。即便最后你并没有把它当做为最终模型,你也可以使用随机森林来移除噪声变量,做特征选择;
- 如果特征的数量和观测样本特别多,那么当资源和时间充足时(这个前提很重要),使用SVM不失为一种选择。
通常情况下:【GBDT>=SVM>=RF>=Adaboost>=Other…】,现在深度学习很热门,很多领域都用到,它是以神经网络为基础的,目前笔者自己也在学习,只是理论知识不扎实,理解的不够深入,这里就不做介绍了,希望以后可以写一片抛砖引玉的文章。
算法固然重要,但好的数据却要优于好的算法,设计优良特征是大有裨益的。假如你有一个超大数据集,那么无论你使用哪种算法可能对分类性能都没太大影响(此时就可以根据速度和易用性来进行抉择)。
总结的常见机器学习算法(主要是一些常规分类器)大概流程和主要思想。实际上在面试过程中,懂这些算法的基本思想和大概流程是远远不够的,那些面试官往往问的都是一些公司内部业务中的课题,往往要求你不仅要懂得这些算法的理论过程,而且要非常熟悉怎样使用它,什么场合用它,算法的优缺点,以及调参经验等等。说白了,就是既要会点理论,也要会点应用,既要有点深度,也要有点广度,否则运气不好的话很容易就被刷掉,因为每个面试官爱好不同。下面给出一点总结。
朴素贝叶斯:
有以下几个地方需要注意:
1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分类为例),比如说是句子单词的话,则长度为整个词汇量的长度,对应位置是该单词出现的次数。
2. 计算公式如下:
其中一项条件概率可以通过朴素贝叶斯条件独立展开。要注意一点就是  的计算方法,而由朴素贝叶斯的前提假设可知,  =  ,因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。
3. 如果 中的某一项为0,则其联合概率的乘积也可能为0,即2中公式的分子为0,为了避免这种现象出现,一般情况下会将这一项初始化为1,当然为了保证概率相等,分母应对应初始化为2(这里因为是2类,所以加2,如果是k类就需要加k,术语上叫做laplace光滑, 分母加k的原因是使之满足全概率公式)。
朴素贝叶斯的优点:
对小规模的数据表现很好,适合多分类任务,适合增量式训练。
缺点:
对输入数据的表达形式很敏感。
决策树:
决策树中很重要的一点就是选择一个属性进行分枝,因此要注意一下信息增益的计算公式,并深入理解它。
信息熵的计算公式如下:

其中的n代表有n个分类类别(比如假设是2类问题,那么n=2)。分别计算这2类样本在总样本中出现的概率p1和p2,这样就可以计算出未选中属性分枝前的信息熵。
现在选中一个属性xi用来进行分枝,此时分枝规则是:如果xi=vx的话,将样本分到树的一个分支;如果不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别,分别计算这2个分支的熵H1和H2,计算出分枝后的总信息熵H’=p1*H1+p2*H2.,则此时的信息增益ΔH=H-H’。以信息增益为原则,把所有的属性都测试一边,选择一个使增益最大的属性作为本次分枝属性。
决策树的优点:
计算量简单,可解释性强,比较适合处理有缺失属性值的样本,能够处理不相关的特征;
缺点:
容易过拟合(后续出现了随机森林,减小了过拟合现象);
Logistic回归:
Logistic是用来分类的,是一种线性分类器,需要注意的地方有:
1. logistic函数表达式为:

其导数形式为:

2. logsitc回归方法主要是用最大似然估计来学习的,所以单个样本的后验概率为:

到整个样本的后验概率:

其中:

通过对数进一步化简为:

3. 其实它的loss function为-l(θ),因此我们需使loss function最小,可采用梯度下降法得到。梯度下降法公式为:


Logistic回归优点:
1、实现简单;
2、分类时计算量非常小,速度很快,存储资源低;
缺点:
1、容易欠拟合,一般准确度不太高
2、只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
线性回归:
线性回归才是真正用于回归的,而不像logistic回归是用于分类,其基本思想是用梯度下降法对最小二乘法形式的误差函数进行优化,当然也可以用normal equation直接求得参数的解,结果为:

而在LWLR(局部加权线性回归)中,参数的计算表达式为:

因为此时优化的是:

由此可见LWLR与LR不同,LWLR是一个非参数模型,因为每次进行回归计算都要遍历训练样本至少一次。
线性回归优点:
实现简单,计算简单;
缺点:
不能拟合非线性数据;
KNN算法:
KNN即最近邻算法,其主要过程为:
1. 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);
2. 对上面所有的距离值进行排序;
3. 选前k个最小距离的样本;
4. 根据这k个样本的标签进行投票,得到最后的分类类别;
如何选择一个最佳的K值,这取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响。但会使类别之间的界限变得模糊。一个较好的K值可通过各种启发式技术来获取,比如,交叉验证。另外噪声和非相关性特征向量的存在会使K近邻算法的准确性减小。
近邻算法具有较强的一致性结果。随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些好的K值,K近邻保证错误率不会超过贝叶斯理论误差率。
注:马氏距离一定要先给出样本集的统计性质,比如均值向量,协方差矩阵等。关于马氏距离的介绍如下:

KNN算法的优点:
1. 思想简单,理论成熟,既可以用来做分类也可以用来做回归;
2. 可用于非线性分类;
3. 训练时间复杂度为O(n);
4. 准确度高,对数据没有假设,对outlier不敏感;
缺点:
1. 计算量大;
2. 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
3. 需要大量的内存;
SVM:
要学会如何使用libsvm以及一些参数的调节经验,另外需要理清楚svm算法的一些思路:
1. svm中的最优分类面是对所有样本的几何裕量最大(为什么要选择最大间隔分类器,请从数学角度上说明?网易深度学习岗位面试过程中有被问到。答案就是几何间隔与样本的误分次数间存在关系: ,其中的分母就是样本到分类间隔距离,分子中的R是所有样本中的最长向量值),即: ,其中的分母就是样本到分类间隔距离,分子中的R是所有样本中的最长向量值),即:

经过一系列推导可得为优化下面原始目标:

2. 下面来看看拉格朗日理论:

可以将1中的优化目标转换为拉格朗日的形式(通过各种对偶优化,KKD条件),最后目标函数为:

我们只需要最小化上述目标函数,其中的α为原始优化问题中的不等式约束拉格朗日系数。
3. 对2中最后的式子分别w和b求导可得:


由上面第1式子可以知道,如果我们优化出了α,则直接可以求出w了,即模型的参数搞定。而上面第2个式子可以作为后续优化的一个约束条件。
4. 对2中最后一个目标函数用对偶优化理论可以转换为优化下面的目标函数:

而这个函数可以用常用的优化方法求得α,进而求得w和b。
5. 按照道理,svm简单理论应该到此结束。不过还是要补充一点,即在预测时有:

那个尖括号我们可以用核函数代替,这也是svm经常和核函数扯在一起的原因。
6. 最后是关于松弛变量的引入,因此原始的目标优化公式为:

此时对应的对偶优化公式为:

与前面的相比只是α多了个上界。
SVM算法优点:
可用于线性/非线性分类,也可以用于回归;
低泛化误差;
容易解释;
计算复杂度较低;
缺点:
对参数和核函数的选择比较敏感;
原始的SVM只比较擅长处理二分类问题;
Boosting:
主要以Adaboost为例,首先来看看Adaboost的流程图,如下:

从图中可以看到,在训练过程中我们需要训练出多个弱分类器(图中为3个),每个弱分类器是由不同权重的样本(图中为5个训练样本)训练得到(其中第一个弱分类器对应输入样本的权值是一样的),而每个弱分类器对最终分类结果的作用也不同,是通过加权平均输出的,权值见上图中三角形里面的数值。那么这些弱分类器和其对应的权值是怎样训练出来的呢?
下面通过一个例子来简单说明。
书中(machine learning in action)假设的是5个训练样本,每个训练样本的维度为2,在训练第一个分类器时5个样本的权重各为0.2. 注意这里样本的权值和最终训练的弱分类器组对应的权值α是不同的,样本的权重只在训练过程中用到,而α在训练过程和测试过程都有用到。
现在假设弱分类器是带一个节点的简单决策树,该决策树会选择2个属性(假设只有2个属性)的一个,然后计算出这个属性中的最佳值用来分类。
Adaboost的简单版本训练过程如下:
1. 训练第一个分类器,样本的权值D为相同的均值。通过一个弱分类器,得到这5个样本(请对应书中的例子来看,依旧是machine learning in action)的分类预测标签。与给出的样本真实标签对比,就可能出现误差(即错误)。如果某个样本预测错误,则它对应的错误值为该样本的权重,如果分类正确,则错误值为0. 最后累加5个样本的错误率之和,记为ε。
2. 通过ε来计算该弱分类器的权重α,公式如下:

3. 通过α来计算训练下一个弱分类器样本的权重D,如果对应样本分类正确,则减小该样本的权重,公式为:

如果样本分类错误,则增加该样本的权重,公式为:

4. 循环步骤1,2,3来继续训练多个分类器,只是其D值不同而已。
测试过程如下:
输入一个样本到训练好的每个弱分类中,则每个弱分类都对应一个输出标签,然后该标签乘以对应的α,最后求和得到值的符号即为预测标签值。
Boosting算法的优点:
低泛化误差;
容易实现,分类准确率较高,没有太多参数可以调;
缺点:
对outlier比较敏感;
聚类:
根据聚类思想划分:
1. 基于划分的聚类:
K-means, k-medoids(每一个类别中找一个样本点来代表),CLARANS.
k-means是使下面的表达式值最小:

k-means算法的优点:
(1)k-means算法是解决聚类问题的一种经典算法,算法简单、快速。
(2)对处理大数据集,该算法是相对可伸缩的和高效率的,因为它的复杂度大约是O(nkt),其中n是所有对象的数目,k是簇的数目,t是迭代的次数。通常k<<n。这个算法通常局部收敛。
(3)算法尝试找出使平方误差函数值最小的k个划分。当簇是密集的、球状或团状的,且簇与簇之间区别明显时,聚类效果较好。
缺点:
(1)k-平均方法只有在簇的平均值被定义的情况下才能使用,且对有些分类属性的数据不适合。
(2)要求用户必须事先给出要生成的簇的数目k。
(3)对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。
(4)不适合于发现非凸面形状的簇,或者大小差别很大的簇。
(5)对于"噪声"和孤立点数据敏感,少量的该类数据能够对平均值产生极大影响。
2. 基于层次的聚类:
自底向上的凝聚方法,比如AGNES。
自上向下的分裂方法,比如DIANA。
3. 基于密度的聚类:
DBSACN,OPTICS,BIRCH(CF-Tree),CURE.
4. 基于网格的方法:
STING, WaveCluster.
5. 基于模型的聚类:
EM,SOM,COBWEB.
以上这些算法的简介可参考聚类(百度百科)。
推荐系统:
推荐系统的实现主要分为两个方面:基于内容的实现和协同滤波的实现。
基于内容的实现:
不同人对不同电影的评分这个例子,可以看做是一个普通的回归问题,因此每部电影都需要提前提取出一个特征向量(即x值),然后针对每个用户建模,即每个用户打的分值作为y值,利用这些已有的分值y和电影特征值x就可以训练回归模型了(最常见的就是线性回归)。这样就可以预测那些用户没有评分的电影的分数。(值得注意的是需对每个用户都建立他自己的回归模型)
从另一个角度来看,也可以是先给定每个用户对某种电影的喜好程度(即权值),然后学出每部电影的特征,最后采用回归来预测那些没有被评分的电影。
当然还可以是同时优化得到每个用户对不同类型电影的热爱程度以及每部电影的特征。具体可以参考Ng在coursera上的ml教程:https://www.coursera.org/course/ml
基于协同滤波的实现:
协同滤波(CF)可以看做是一个分类问题,也可以看做是矩阵分解问题。协同滤波主要是基于每个人自己的喜好都类似这一特征,它不依赖于个人的基本信息。比如刚刚那个电影评分的例子中,预测那些没有被评分的电影的分数只依赖于已经打分的那些分数,并不需要去学习那些电影的特征。
SVD将矩阵分解为三个矩阵的乘积,公式如下所示:

中间的矩阵sigma为对角矩阵,对角元素的值为Data矩阵的奇异值(注意奇异值和特征值是不同的),且已经从大到小排列好了。即使去掉特征值小的那些特征,依然可以很好的重构出原始矩阵。如下图所示:

其中更深的颜色代表去掉小特征值重构时的三个矩阵。
果m代表商品的个数,n代表用户的个数,则U矩阵的每一行代表商品的属性,现在通过降维U矩阵(取深色部分)后,每一个商品的属性可以用更低的维度表示(假设为k维)。这样当新来一个用户的商品推荐向量X,则可以根据公式X'*U1*inv(S1)得到一个k维的向量,然后在V’中寻找最相似的那一个用户(相似度测量可用余弦公式等),根据这个用户的评分来推荐(主要是推荐新用户未打分的那些商品)。具体例子可以参考网页:SVD在推荐系统中的应用。
另外关于SVD分解后每个矩阵的实际含义可以参考google吴军的《数学之美》一书(不过个人感觉吴军解释UV两个矩阵时好像弄反了,不知道大家怎样认为)。或者参考machine learning in action其中的svd章节。
pLSA:
pLSA由LSA发展过来,而早期LSA的实现主要是通过SVD分解。pLSA的模型图如下:

公式中的意义如下:

具体可以参考2010龙星计划:机器学习中对应的主题模型那一讲
LDA:
主题模型,概率图如下:

和pLSA不同的是LDA中假设了很多先验分布,且一般参数的先验分布都假设为Dirichlet分布,其原因是共轭分布时先验概率和后验概率的形式相同。
GDBT:
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),好像在阿里内部用得比较多(所以阿里算法岗位面试时可能会问到),它是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的输出结果累加起来就是最终答案。它在被提出之初就和SVM一起被认为是泛化能力(generalization)较强的算法。近些年更因为被用于搜索排序的机器学习模型而引起大家关注。
GBDT是回归树,不是分类树。其核心就在于,每一棵树是从之前所有树的残差中来学习的。为了防止过拟合,和Adaboosting一样,也加入了boosting这一项。
关于GDBT的介绍可以可以参考:GBDT(MART) 迭代决策树入门教程 | 简介。
Regularization:
作用是(网易电话面试时有问到):
1. 数值上更容易求解;
2. 特征数目太大时更稳定;
3. 控制模型的复杂度,光滑性。复杂性越小且越光滑的目标函数泛化能力越强。而加入规则项能使目标函数复杂度减小,且更光滑。
4. 减小参数空间;参数空间越小,复杂度越低。
5. 系数越小,模型越简单,而模型越简单则泛化能力越强(Ng宏观上给出的解释)。
6. 可以看成是权值的高斯先验。
异常检测:
可以估计样本的密度函数,对于新样本直接计算其密度,如果密度值小于某一阈值,则表示该样本异常。而密度函数一般采用多维的高斯分布。如果样本有n维,则每一维的特征都可以看作是符合高斯分布的,即使这些特征可视化出来不太符合高斯分布,也可以对该特征进行数学转换让其看起来像高斯分布,比如说x=log(x+c), x=x^(1/c)等。异常检测的算法流程如下:

其中的ε也是通过交叉验证得到的,也就是说在进行异常检测时,前面的p(x)的学习是用的无监督,后面的参数ε学习是用的有监督。那么为什么不全部使用普通有监督的方法来学习呢(即把它看做是一个普通的二分类问题)?主要是因为在异常检测中,异常的样本数量非常少而正常样本数量非常多,因此不足以学习到好的异常行为模型的参数,因为后面新来的异常样本可能完全是与训练样本中的模式不同。
另外,上面是将特征的每一维看成是相互独立的高斯分布,其实这样的近似并不是最好的,但是它的计算量较小,因此也常被使用。更好的方法应该是将特征拟合成多维高斯分布,这时有特征之间的相关性,但随之计算量会变复杂,且样本的协方差矩阵还可能出现不可逆的情况(主要在样本数比特征数小,或者样本特征维数之间有线性关系时)。
上面的内容可以参考Ng的https://www.coursera.org/course/ml
EM算法:
有时候因为样本的产生和隐含变量有关(隐含变量是不能观察的),而求模型的参数时一般采用最大似然估计,由于含有了隐含变量,所以对似然函数参数求导是求不出来的,这时可以采用EM算法来求模型的参数的(对应模型参数个数可能有多个),EM算法一般分为2步:
E步:选取一组参数,求出在该参数下隐含变量的条件概率值;
M步:结合E步求出的隐含变量条件概率,求出似然函数下界函数(本质上是某个期望函数)的最大值。
重复上面2步直至收敛。
公式如下所示:
M步公式中下界函数的推导过程:
EM算法一个常见的例子就是GMM模型,每个样本都有可能由k个高斯产生,只不过由每个高斯产生的概率不同而已,因此每个样本都有对应的高斯分布(k个中的某一个),此时的隐含变量就是每个样本对应的某个高斯分布。
GMM的E步公式如下(计算每个样本对应每个高斯的概率):
更具体的计算公式为:
M步公式如下(计算每个高斯的比重,均值,方差这3个参数):
关于EM算法可以参考Ng的cs229课程资料 或者网易公开课:斯坦福大学公开课 :机器学习课程。
Apriori:
Apriori是关联分析中比较早的一种方法,主要用来挖掘那些频繁项集合。其思想是:
1. 如果一个项目集合不是频繁集合,那么任何包含它的项目集合也一定不是频繁集合;
2. 如果一个项目集合是频繁集合,那么它的任何非空子集也是频繁集合;
Aprioir需要扫描项目表多遍,从一个项目开始扫描,舍去掉那些不是频繁的项目,得到的集合称为L,然后对L中的每个元素进行自组合,生成比上次扫描多一个项目的集合,该集合称为C,接着又扫描去掉那些非频繁的项目,重复…
看下面这个例子:
元素项目表格:
如果每个步骤不去掉非频繁项目集,则其扫描过程的树形结构如下:
在其中某个过程中,可能出现非频繁的项目集,将其去掉(用阴影表示)为:
上面的内容主要参考的是machine learning in action这本书。
FP Growth:
FP Growth是一种比Apriori更高效的频繁项挖掘方法,它只需要扫描项目表2次。其中第1次扫描获得当个项目的频率,去掉不符合支持度要求的项,并对剩下的项排序。第2遍扫描是建立一颗FP-Tree(frequent-patten tree)。
接下来的工作就是在FP-Tree上进行挖掘。
比如说有下表:
它所对应的FP_Tree如下:
然后从频率最小的单项P开始,找出P的条件模式基,用构造FP_Tree同样的方法来构造P的条件模式基的FP_Tree,在这棵树上找出包含P的频繁项集。
依次从m,b,a,c,f的条件模式基上挖掘频繁项集,有些项需要递归的去挖掘,比较麻烦,比如m节点,具体的过程可以参考博客:Frequent Pattern 挖掘之二(FP Growth算法),里面讲得很详细。 |  QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2017-6-22 10:07:03
发表于 2017-6-22 10:07:03




























































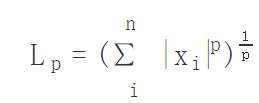

















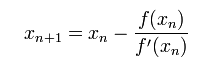





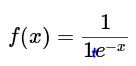
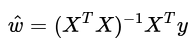
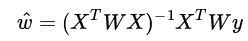

















 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡