前言
本人呕心沥血所写,经过好一段时间反复锤炼和整理修改。感谢所参考的博友们!同时,欢迎前来查阅赏脸的博友们收藏和转载,附上本人的链接
关于几个疑问和几处心得!
a. 用NAT,还是桥接,还是only-host模式?
答: hostonly、桥接和NAT
b. 用static的ip,还是dhcp的?
答:static
c. 别认为快照和克隆不重要,小技巧,比别人灵活用,会很节省时间和大大减少错误。
d. 重用起来脚本语言的编程,如paython或shell编程。
对于用scp -r命令或deploy.conf(配置文件),deploy.sh(实现文件复制的shell脚本文件),runRemoteCdm.sh(在远程节点上执行命令的shell脚本文件)。
e. 重要Vmare Tools增强工具,或者,rz上传、sz下载。
f. 大多数人常用
Xmanager Enterprise *安装步骤
用到的所需:
1、VMware-workstation-full-11.1.2.61471.1437365244.exe
2、CentOS-6.5-x86_64-bin-DVD1.iso
3、jdk-7u69-linux-x64.tar.gz
4、hadoop-2.6.0.tar.gz
机器规划:
192.168.80.31 ---------------- master
192.168.80.32 ---------------- slave1
192.168.80.33 ---------------- slave1
目录规划:
所有namenode节点产生的日志 /data/dfs/name
所有datanode节点产生的日志 /data/dfs/data
第一步:安装VMware-workstation虚拟机,我这里是VMware-workstation11版本
详细见 ->
VMware workstation 11 的下载
VMWare Workstation 11的安装
VMware Workstation 11安装之后的一些配置
第二步:安装CentOS系统,我这里是6.6版本。推荐(生产环境中常用)
详细见 ->
CentOS 6.5的安装详解
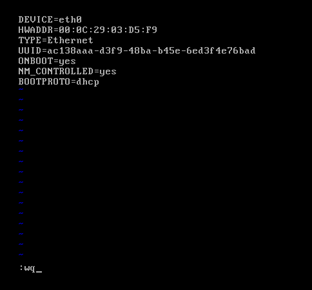
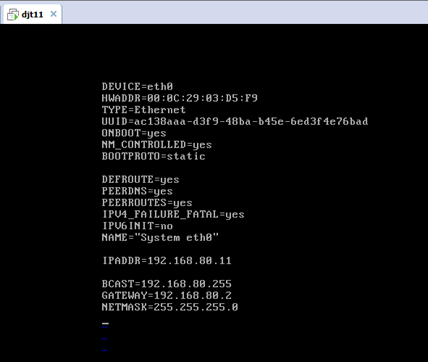
CentOS 6.5安装之后的网络配置
CentOS 6.5静态IP的设置(NAT和桥接都适用)
CentOS 命令行界面与图形界面切换
网卡eth0、eth1...ethn
Centos 6.5下的OPENJDK卸载和SUN的JDK安装、环境变量配置
第三步:VMware Tools增强工具安装
详细见 ->
VMware里Ubuntukylin-14.04-desktop的VMware Tools安装图文详解
第四步:准备小修改(学会用快照和克隆,根据自身要求情况,合理位置快照)
详细见 ->
CentOS常用命令、快照、克隆大揭秘
新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu)
步骤流程(本博文):
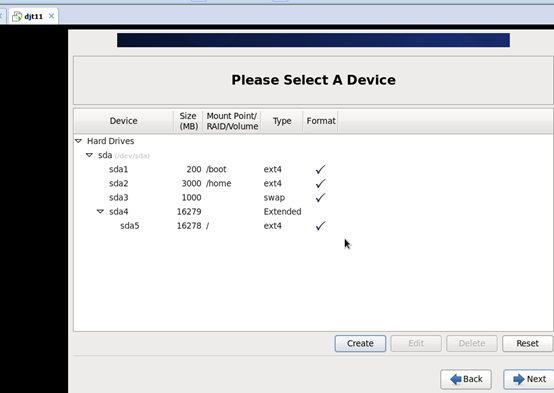
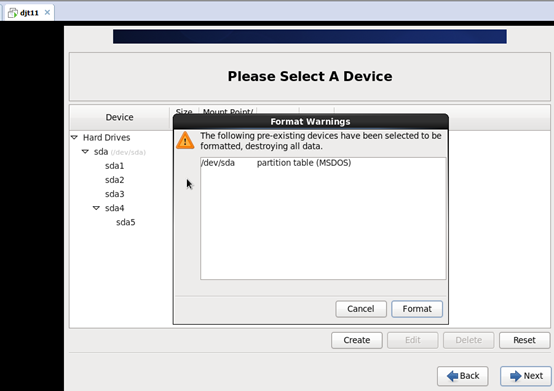
1、 搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 分配1G及以上的状况)
2 、搭建一个5节点的hadoop分布式小集群--预备工作(djt11、djt12、djt13、djt14、djt15的网络连接、ip地址静态、拍照)
3、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 远程)
4、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 主机规划、软件规划、目录规划)
补充: 若是用户规划和目录规划,执行反了,则出现什么结果呢?请看---强烈建议不要这样干
5、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的环境检查 )
6 、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的SSH免密码通信配置)
7 、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的jdk安装)
8 、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的djt11脚本工具的使用)
9 、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的Zookeeper安装)
10、 搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的hadoop集群环境搭建)继续
1 、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 分配1G及以上的状况)
对于这步,基础得看,CentOS 6.5的安装详解。
虚拟机名称:djt11
位置:D:\SoftWare\Virtual Machines\CentOS\CentOS 6.5\djt11
若是4G内存的笔记本来安装这5个节点的Hadoop小集群的话, 最好,安装时每个还是1G,这样便于安装。至于使用的时候,就0.5G就好了。
NAT
少了??
2 搭建一个5节点的hadoop分布式小集群--预备工作(djt11、djt12、djt13、djt14、djt15的网络连接、ip地址静态、拍照)
需要注意的是,5节点各自的MAC和UUID地址是不一样。
2.1 、对djt11
即,成功由原来的192.168.80.137(是动态获取的)成功地,改变成了192.168.80.11(静态的)
以上是djt11 的 192.168.80.11。
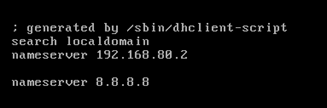
vi /etc/hosts
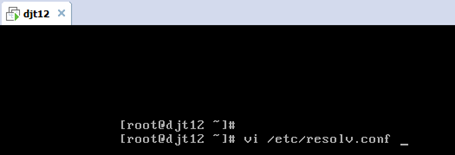
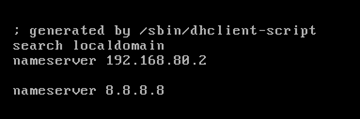
vi /etc/resolv.conf
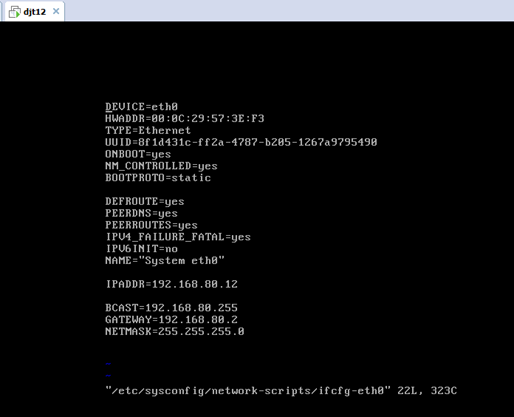
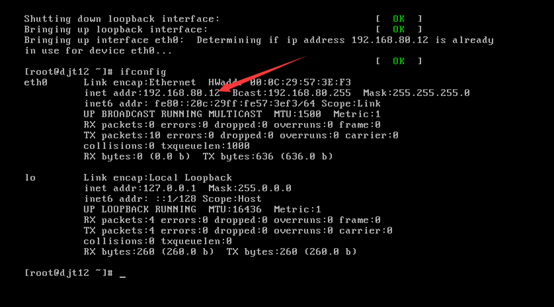
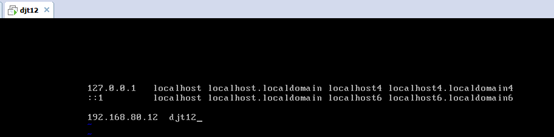
2.2、对djt12
即,成功由原来的192.168.80.**(是动态获取的)成功地,改变成了192.168.80.12(静态的)
以上是djt12 的 192.168.80.12
即,djt12的步骤变得更精华了。笔记就是越做越清楚和简单啊。
vi /etc/hosts
vi /etc/resolv.conf
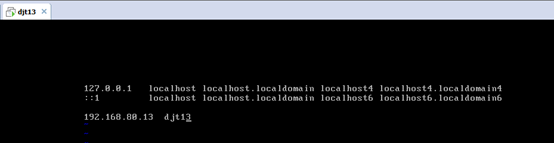
2.3、对djt13
vi /etc/hosts
vi /etc/resolv.conf
2.4、对djt14
vi /etc/hosts
vi /etc/resolv.conf
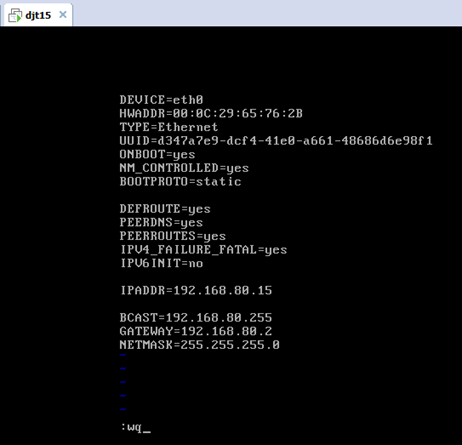
2.5、对djt15
vi /etc/hosts
vi /etc/resolv.conf
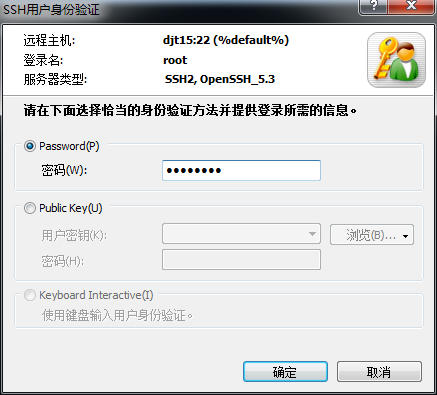
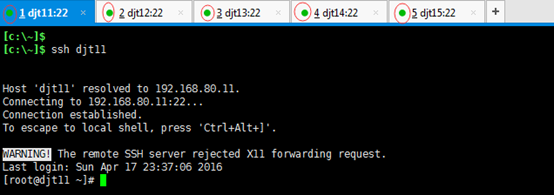
3、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 远程)
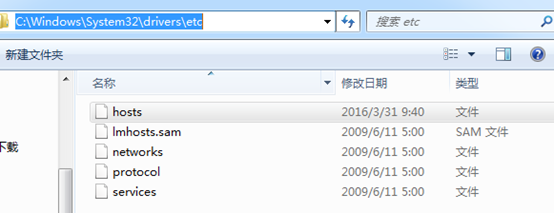
C:\Windows\System32\drivers\etc\hosts
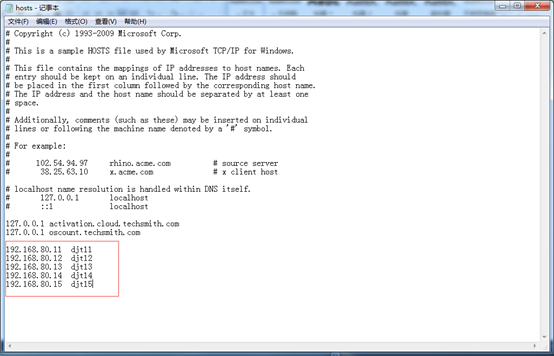
192.168.80.11 djt11
192.168.80.12 djt12
192.168.80.13 djt13
192.168.80.14 djt14
192.168.80.15 djt15
3.1、对djt11
3.2、对djt12
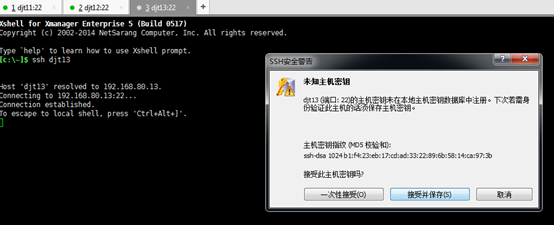
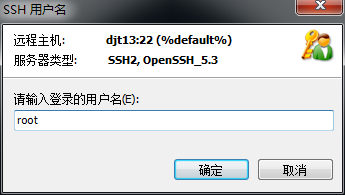
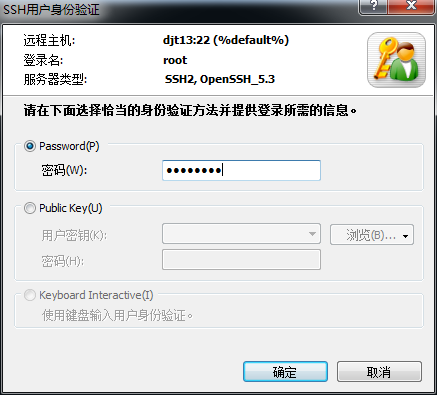
3.3、对djt13
3.4、对djt14
3.5、对djt15
总的如下
*****************************可以跳过这个阶段***********************
补充:若是用户规划和目录规划,执行反了(即目录规划在前,用户规划在后),则出现什么结果呢?请看---强烈建议不要这样干
强烈建议,不要这样干!!!!
=> 所以,记住,先是用户规划,再目录规划!!!
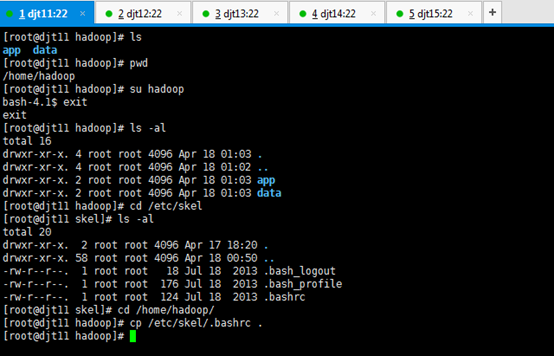
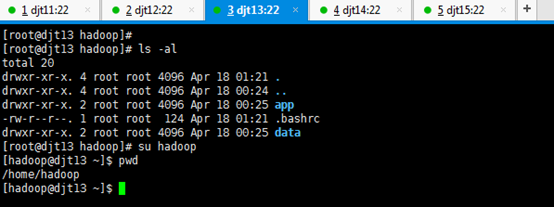
用户规划
每个节点的hadoop用户组和用户需要大家自己创建,单节点已经讲过,这里就不耽误大家时间。
依次,对djt11、djt12、djt13、djt14、 djt15进行用户规划,hadoop用户组,hadoop用户。
目录规划
首先,
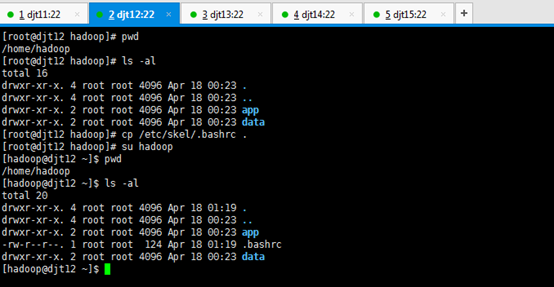
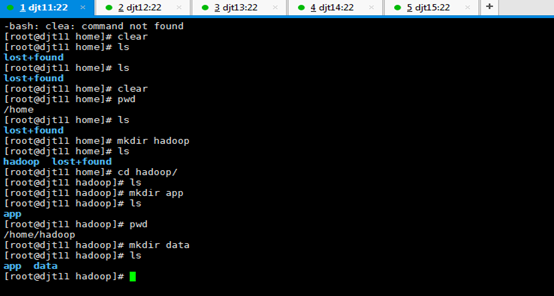
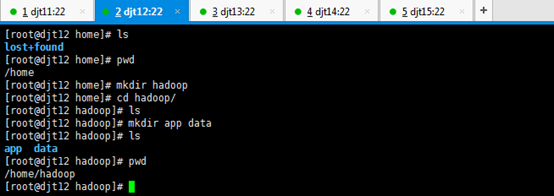
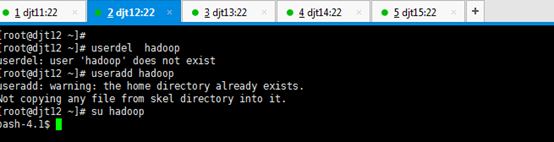
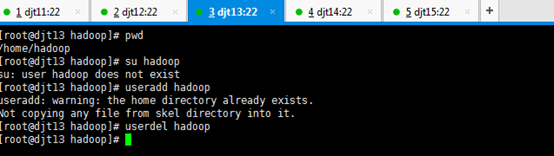
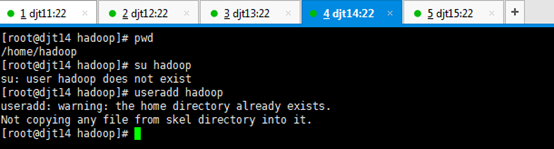
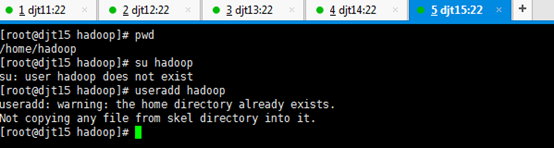
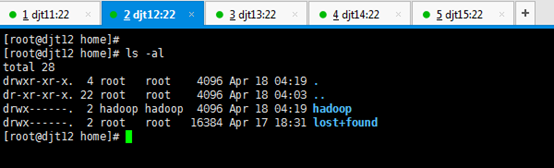
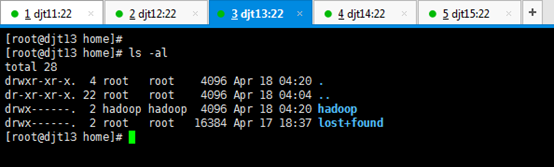
直接上来,就是 目录规划,再用户规划。(这是犯了最低级错误啊!zhouls)(以下这是错误的,博友们,看看就好)(直接跳到步骤4去)
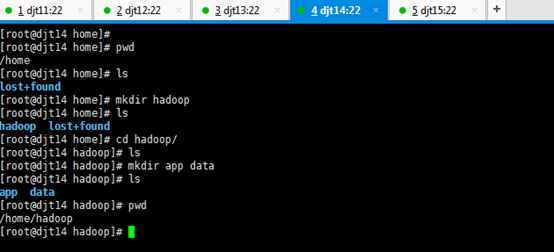
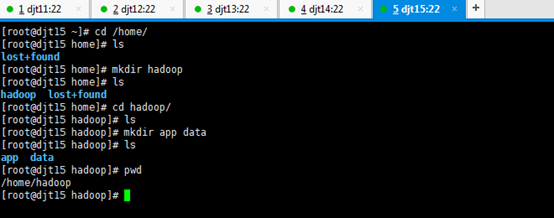
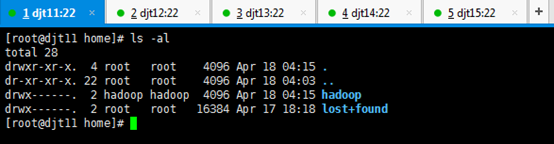
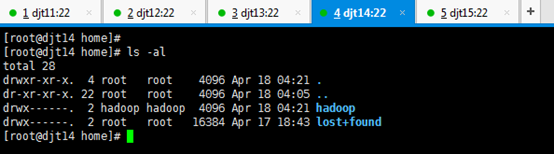
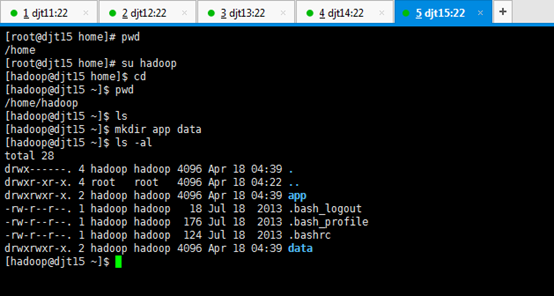
刚开始,只要root用户,都还创建hadoop用户,在/home下只有lost+found。直接上来,就是:mkdir hadoop,然后在里面就是mkdir app data。
然后,
是报错误,但是,这不分明就是犯了错误吗?最后导致如下问题。
所以,
那么如何来解决呢??
虽然,这样可以挽救没有事先创建hadoop用户,来达到挽救。但是,密码呢?
这一步,依然还是出现错误。因为,没有密码。
*****************************
4、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 主机规划、软件规划、目录规划)
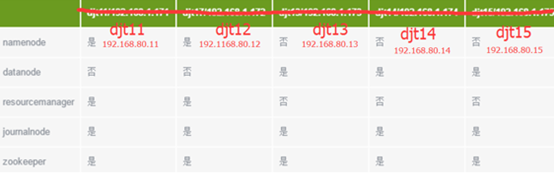
主机规划
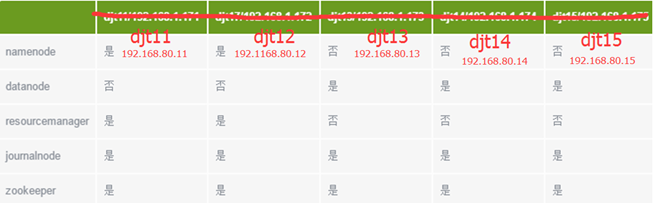
若是条件有限。则就只搭建3个吧。最开始啊,namenode是存在单点故障问题。从hadoop2.0之后,就设置了热备,防止宕机。
这里我们使用5 台主机来配置Hadoop集群。
Journalnode和ZooKeeper保持奇数个,这点大家要有个概念,最少不少于 3 个节点。
软件规划
这里啊,我们实现namenode热备和resourcemanger热备。在hadoop2.0之前啊,是没有实现这个功能。hadoop2.2.0只实现namenode热备。在hadoop2.4.0实现了namenode热备和resourcemanger热备,但是不是很稳定,所以,我们这里啊,就使用hadoop2.6.0。
用户规划

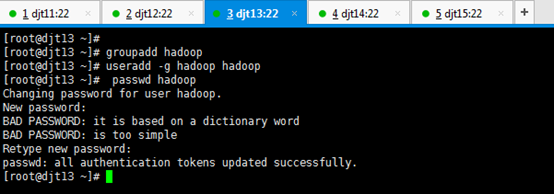
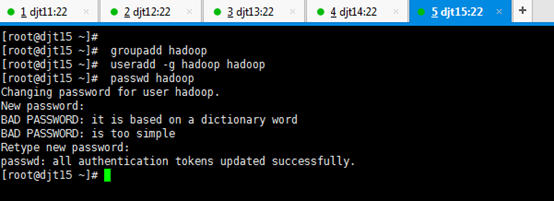
依次,对djt11、djt12、djt13、djt14、 djt15进行用户规划,hadoop用户组,hadoop用户。
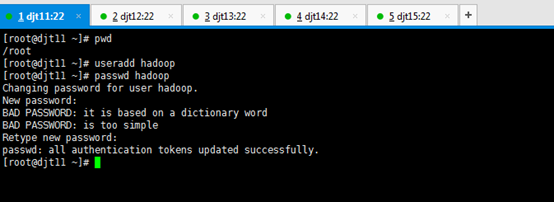
groupadd hadoop
//这是新建hadoop用户组
useradd –g hadoop hadoop
//这是新建hadoop用户,并增加到hadoop用户组
passwd hadoop
//这是创建hadoop用户的密码
扩展知识:
usermod -a -g 用户组 用户
若是,直接来。
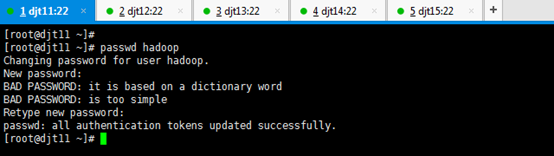
useradd hadoop ,
passwd hadoop ,
则会自动创建hadoop用户组。
以至于,会出现如下。
或者,
先新建用户组,再来新建用户 。
[iyunv@djt11 ~]# groupadd hadoop
[iyunv@djt11 ~]# useradd -g hadoop hadoop
[iyunv@djt11 ~]# passwd hadoop
Changing password for user hadoop.
New password: (输入hadoop用户想设置的密码)
BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password: (输入hadoop用户想设置的密码)
passwd: all authentication tokens updated successfully.
先新建用户组,再来新建用户 。
[iyunv@djt12 ~]# groupadd hadoop
[iyunv@djt12 ~]# useradd -g hadoop hadoop
[iyunv@djt12 ~]# passwd hadoop
Changing password for user hadoop.
New password: (输入hadoop用户想设置的密码)
BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password: (输入hadoop用户想设置的密码)
passwd: all authentication tokens updated successfully.
[iyunv@djt13 ~]# groupadd hadoop
[iyunv@djt13 ~]# useradd -g hadoop hadoop
[iyunv@djt13 ~]# passwd hadoop
Changing password for user hadoop.
New password: (输入hadoop用户想设置的密码)
BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password: (输入hadoop用户想设置的密码)
passwd: all authentication tokens updated successfully.
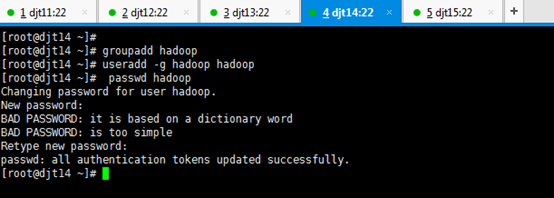
[iyunv@djt14 ~]# groupadd hadoop
[iyunv@djt14 ~]# useradd -g hadoop hadoop
[iyunv@djt14 ~]# passwd hadoop
Changing password for user hadoop.
New password: (输入hadoop用户想设置的密码)
BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password: (输入hadoop用户想设置的密码)
passwd: all authentication tokens updated successfully.
[iyunv@djt15 ~]# groupadd hadoop
[iyunv@djt15 ~]# useradd -g hadoop hadoop
[iyunv@djt15 ~]# passwd hadoop
Changing password for user hadoop.
New password: (输入hadoop用户想设置的密码)
BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password: (输入hadoop用户想设置的密码)
passwd: all authentication tokens updated successfully.
目录规划
对于单节点的hadoop集群:
所有的软件目录是在/usr/java/下。
数据目录是在/daa/dfs/name,/data/dfs/name,
/data/tmp。
日志目录是在/usr/java/hadoop/logs/下。
其中,启动日志是在/usr/java/hadoop/logs
作业运行日志是在/usr/java/hadoop/logs/userlogs/下
对于5节点的hadoop集群:
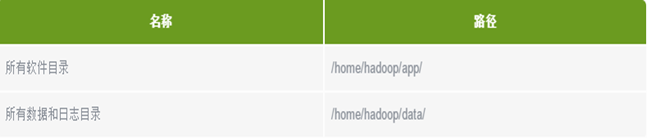
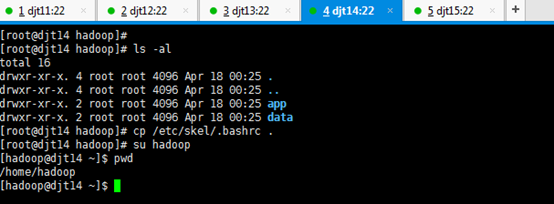
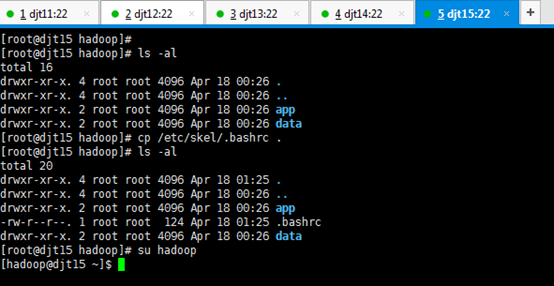
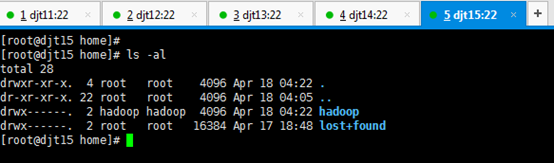
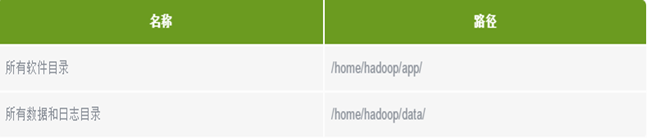
新建hadoop用户后,自动生成/home/hadoop。
所有的软件目录是在/home/hadoop/app/下。
所有的数据和日志目录是在/home/hadoop/data
以前,是在/usr/java/hadoop下,现在此刻,开始,在/home/hadoop/app/hadoop(这才叫正规)
以及,在/home/hadoop/app/zookeeper , /home/hadoop/app/jdk1.7.0_79
对djt11而言,
新建hadoop用户后,自动生成/home/hadoop。
所有的软件目录是在/home/hadoop/app/下。
所有的数据和日志目录是在/home/hadoop/data
对djt12而言,
新建hadoop用户后,自动生成/home/hadoop。
所有的软件目录是在/home/hadoop/app/下。
所有的数据和日志目录是在/home/hadoop/data
对djt13而言,
新建hadoop用户后,自动生成/home/hadoop。
所有的软件目录是在/home/hadoop/app/下。
所有的数据和日志目录是在/home/hadoop/data
对djt14而言,
新建hadoop用户后,自动生成/home/hadoop。
所有的软件目录是在/home/hadoop/app/下。
所有的数据和日志目录是在/home/hadoop/data
对djt15而言,
新建hadoop用户后,自动生成/home/hadoop。
所有的软件目录是在/home/hadoop/app/下。
所有的数据和日志目录是在/home/hadoop/data
5、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的环境检查 )
集群安装前的环境检查
在集群安装之前,我们需要一个对其环境的一个检查。
时钟同步
所有节点的系统时间要与当前时间保持一致,查看当前系统时间。
如果系统时间与当前时间不一致,进行以下操作。
对djt11
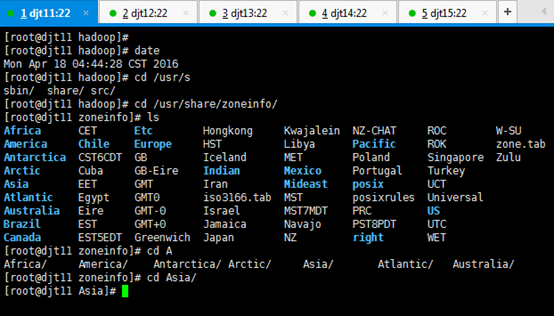
[iyunv@djt11 hadoop]# date
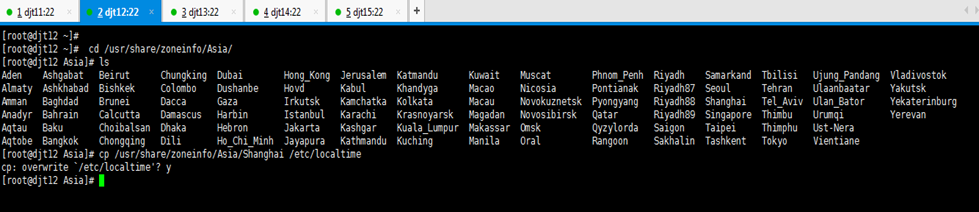
[iyunv@djt11 hadoop]# cd /usr/share/zoneinfo/
[iyunv@djt11 zoneinfo]# ls
[iyunv@djt11 zoneinfo]# cd Asia/
[iyunv@djt11 Asia]#
//当前时区替换为上海
[iyunv@djt11 Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
cp: overwrite `/etc/localtime'? y
[iyunv@djt11 Asia]#
需要ntp来实现时间的同步。
依次,对djt11、djt12、djt13、djt14、 djt15进行时钟同步和安装ntp命令。
我们可以同步当前系统时间和日期与NTP(网络时间协议)一致。
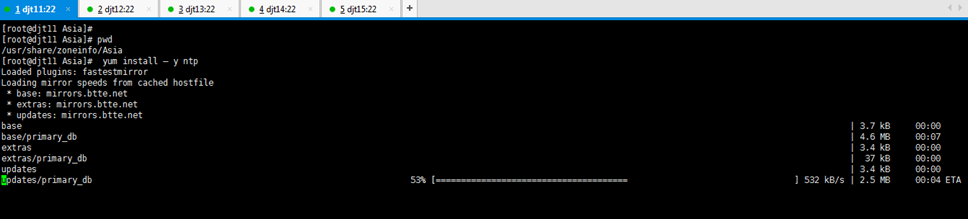
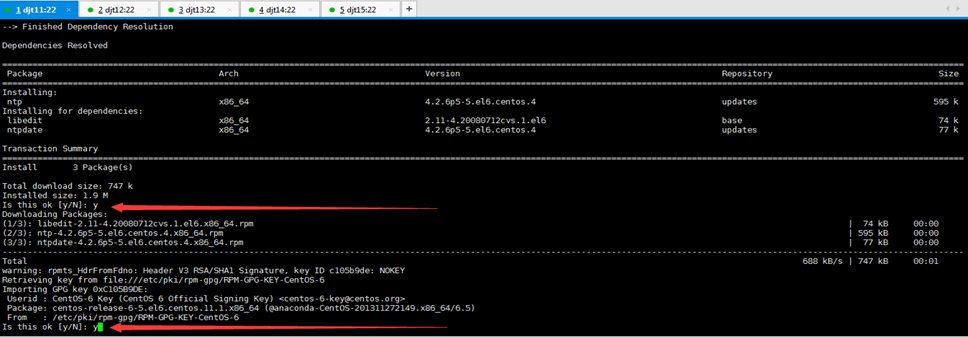
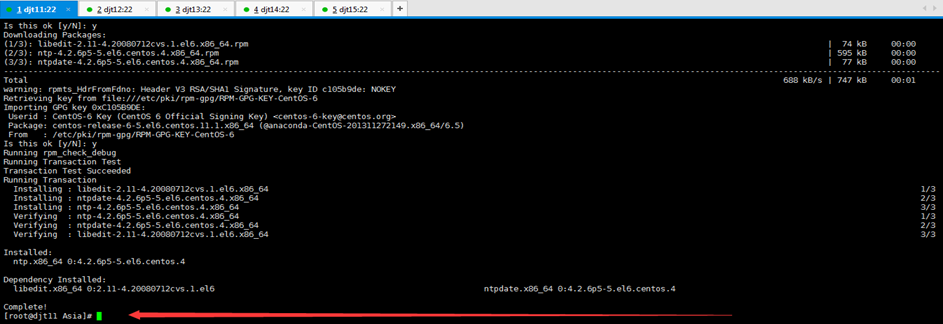
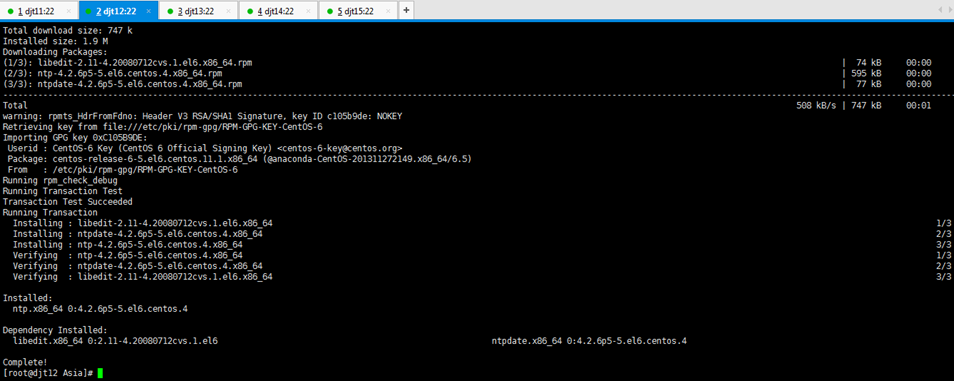
[iyunv@djt11 Asia]# yum install -y ntp
//如果ntp命令不存在,在线安装ntp
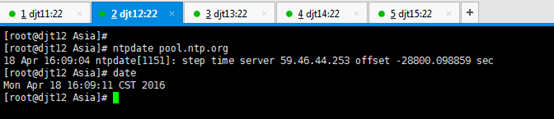
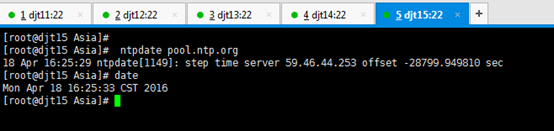
[iyunv@djt11 Asia]# ntpdate pool.ntp.org
//执行此命令同步日期时间
[iyunv@djt11 Asia]# date
//查看当前系统时间
对djt12
[iyunv@djt12 ~]# cd /usr/share/zoneinfo/Asia/
[iyunv@djt12 Asia]# ls
[iyunv@djt12 Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
cp: overwrite `/etc/localtime'? y
[iyunv@djt12 Asia]# pwd
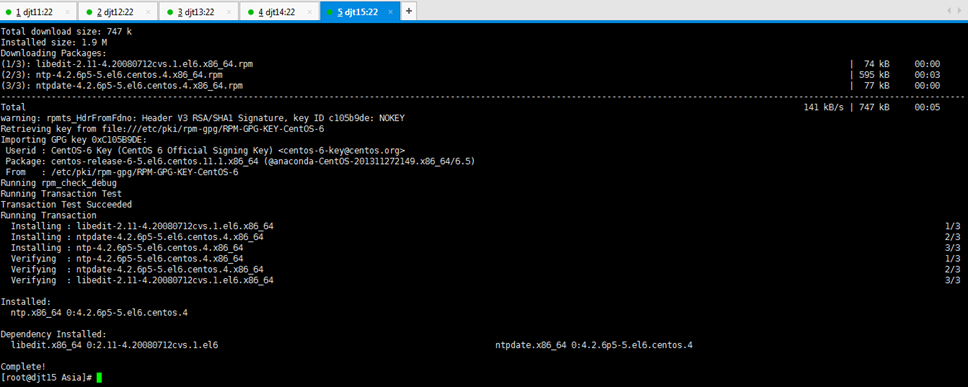
[iyunv@djt12 Asia]# yum -y install ntp
对djt12的ntp命令,安装成功。
[iyunv@djt12 Asia]# ntpdate pool.ntp.org
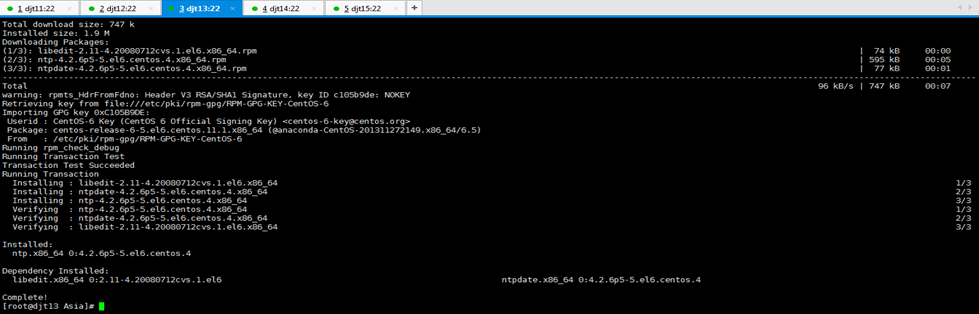
对djt13
[iyunv@djt13 ~]# cd /usr/share/zoneinfo/Asia/
[iyunv@djt13 Asia]# ls
[iyunv@djt13 Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
cp: overwrite `/etc/localtime'? y
[iyunv@djt13 Asia]# pwd
[iyunv@djt13 Asia]# yum -y install ntp
对djt13的ntp命令,安装成功
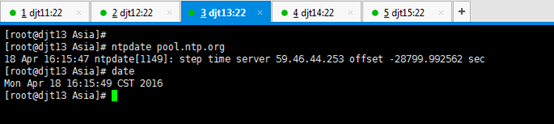
[iyunv@djt13 Asia]# ntpdate pool.ntp.org
[iyunv@djt13 Asia]# date
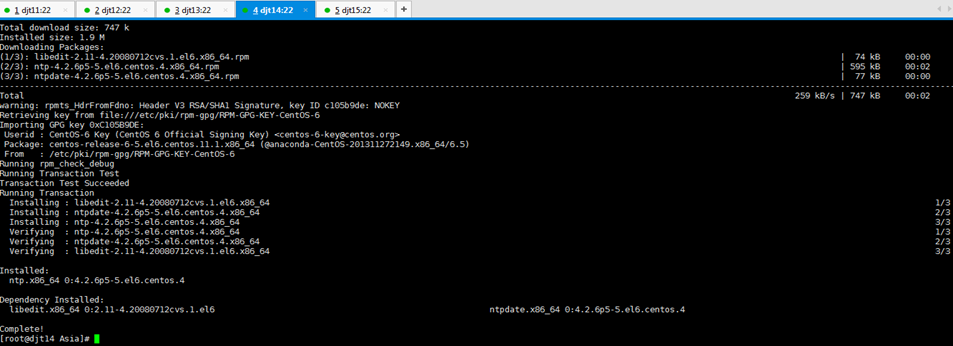
对djt14
[iyunv@djt14 ~]# cd /usr/share/zoneinfo/Asia/
[iyunv@djt14 Asia]# ls
[iyunv@djt14 Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
cp: overwrite `/etc/localtime'? y
[iyunv@djt14 Asia]# pwd
[iyunv@djt14 Asia]# yum -y install ntp
对djt14的ntp命令的成功安装
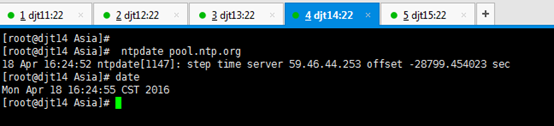
[iyunv@djt14 Asia]# ntpdate pool.ntp.org
[iyunv@djt14 Asia]# date
对djt15
[iyunv@djt15 ~]# cd /usr/share/zoneinfo/Asia/
[iyunv@djt15 Asia]# ls
[iyunv@djt15 Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
cp: overwrite `/etc/localtime'? y
[iyunv@djt15 Asia]# pwd
[iyunv@djt15 Asia]# yum -y install ntp
对djt15的ntp命令的成功安装
[iyunv@djt15 Asia]# ntpdate pool.ntp.org
[iyunv@djt15 Asia]# date
hosts文件检查
所有节点的hosts文件都要配置静态ip与hostname之间的对应关系。
依次,对djt11、djt12、djt13、djt14、 djt15进行host与IP配置。
对djt11
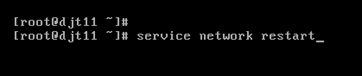
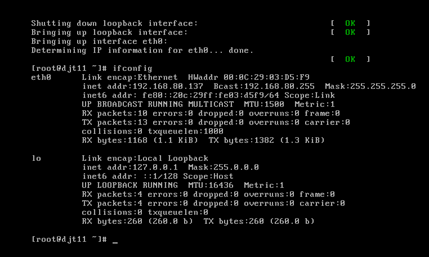
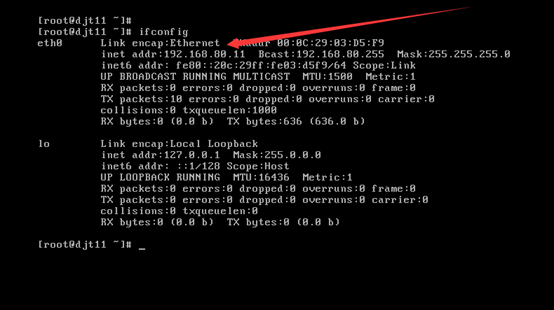
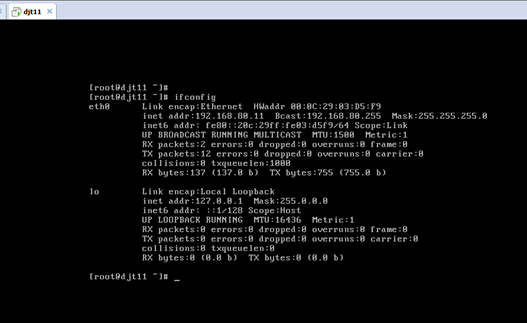
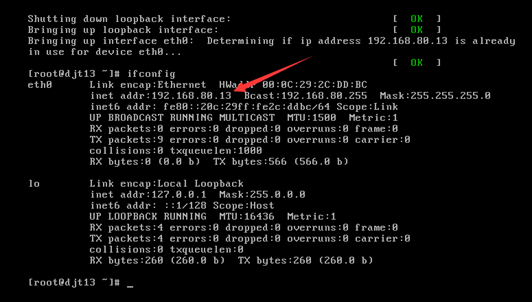
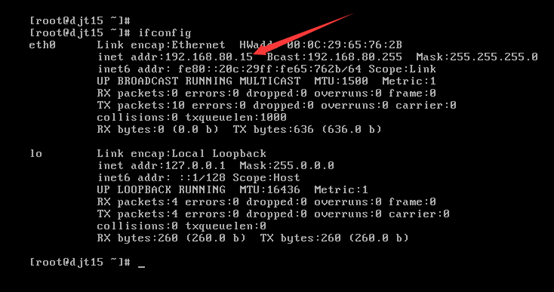
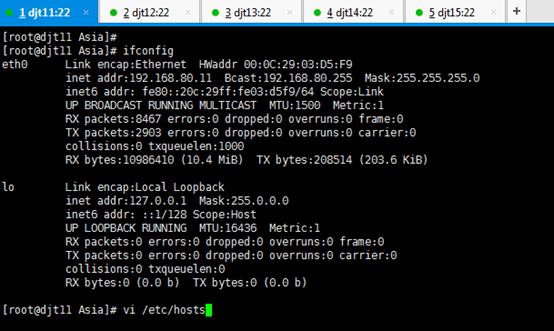
[iyunv@djt11 Asia]# ifconfig
[iyunv@djt11 Asia]# vi /etc/hosts
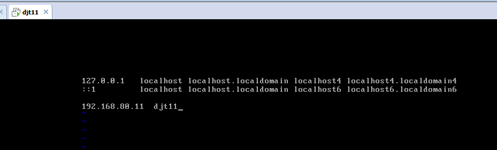
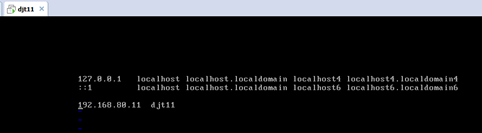
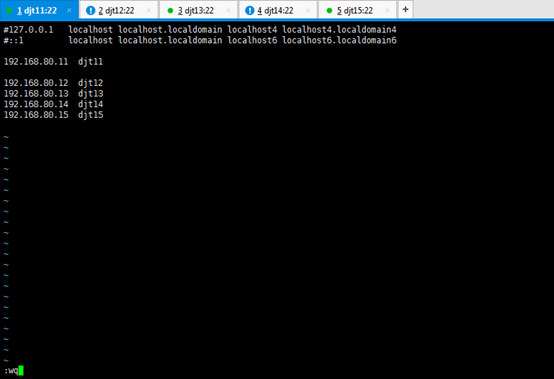
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.80.11 djt11
192.168.80.12 djt12
192.168.80.13 djt13
192.168.80.14 djt14
192.168.80.15 djt15
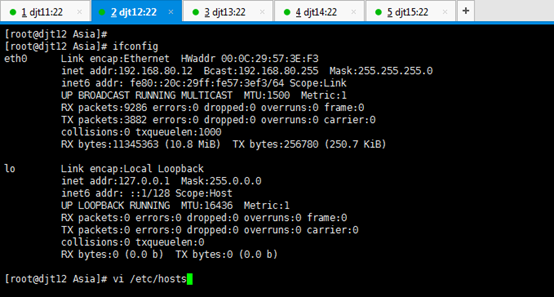
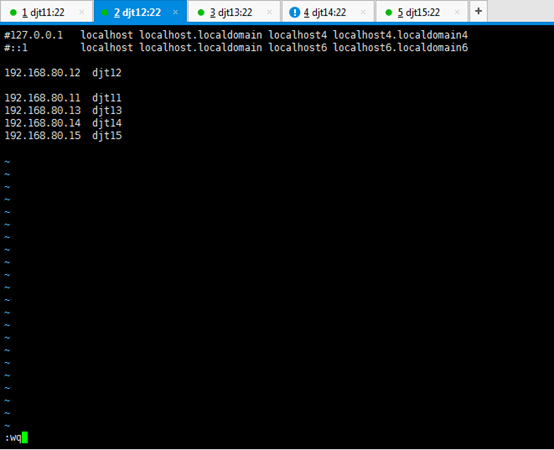
对djt12
[iyunv@djt12 Asia]# ifconfig
[iyunv@djt12 Asia]# vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.80.12 djt12
192.168.80.11 djt11
192.168.80.13 djt13
192.168.80.14 djt14
192.168.80.15 djt15
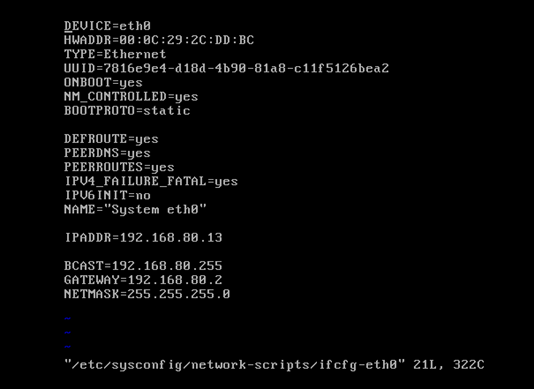
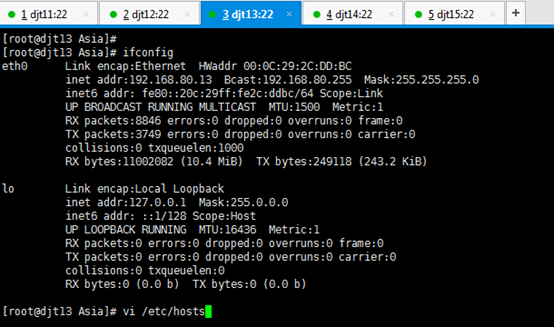
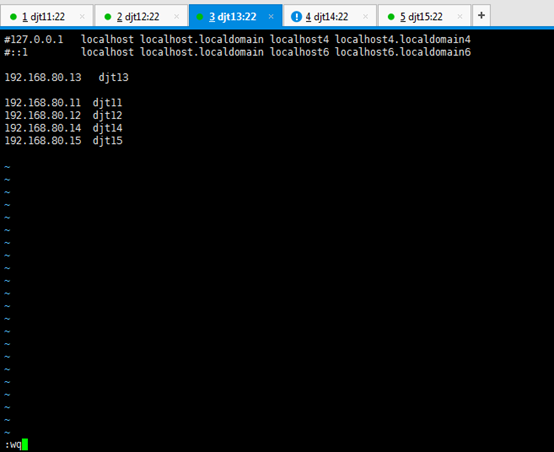
对djt13
[iyunv@djt13 Asia]# ifconfig
[iyunv@djt13 Asia]# vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.80.13 djt13
192.168.80.11 djt11
192.168.80.12 djt12
192.168.80.14 djt14
192.168.80.15 djt15
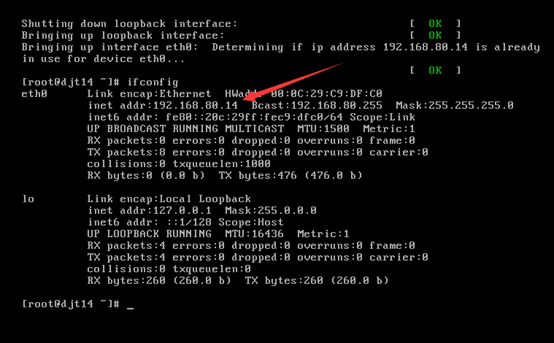
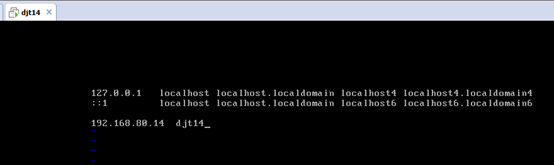
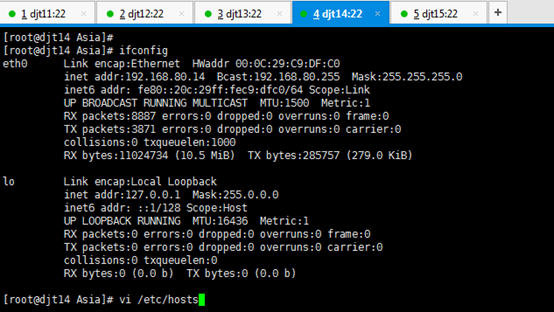
对djt14
[iyunv@djt14 Asia]# ifconfig
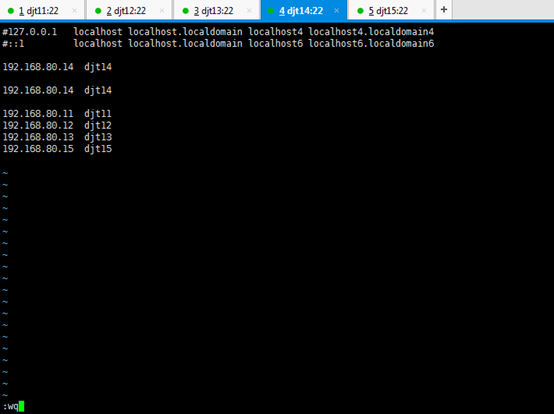
[iyunv@djt14 Asia]# vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.80.14 djt14
192.168.80.11 djt11
192.168.80.12 djt12
192.168.80.13 djt13
192.168.80.15 djt15
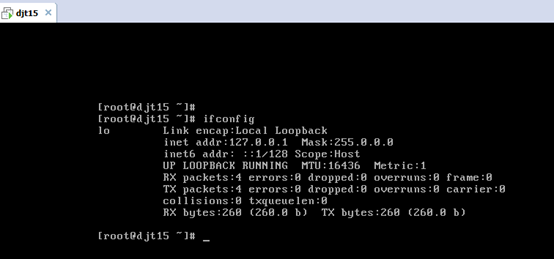
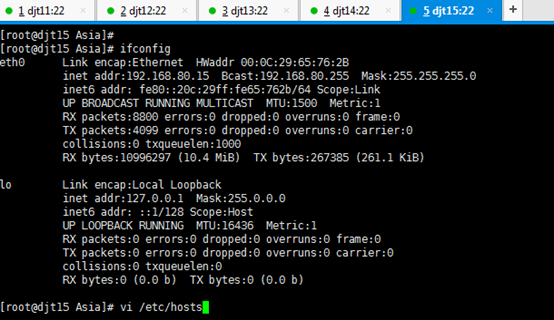
对djt15
[iyunv@djt15 Asia]# ifconfig
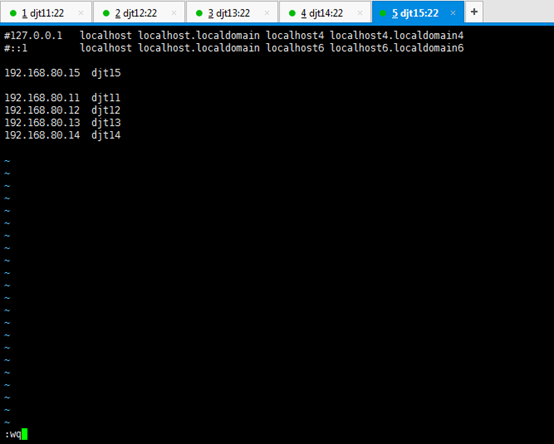
[iyunv@djt15 Asia]# vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
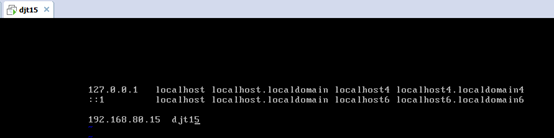
192.168.80.15 djt15
192.168.80.11 djt11
192.168.80.12 djt12
192.168.80.13 djt13
192.168.80.14 djt14
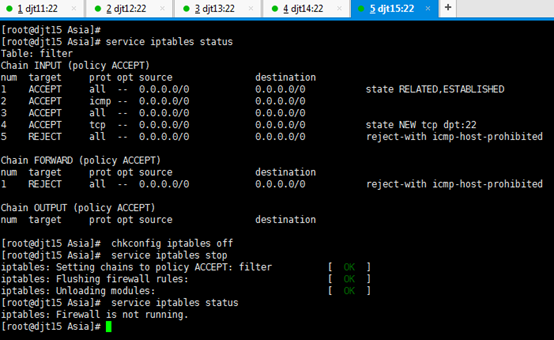
禁用防火墙
所有节点的防火墙都要关闭。
依次,对djt11、djt12、djt13、djt14、 djt15进行禁用防火墙。
[iyunv@djt11 Asia]# service iptables status
[iyunv@djt11 Asia]# chkconfig iptables off
//永久关闭防火墙
[iyunv@djt11 Asia]# service iptables stop //临时关闭防火墙
[iyunv@djt11 Asia]# service iptables status
iptables: Firewall is not running.
//查看防火墙状态
[iyunv@djt12 Asia]# service iptables status
[iyunv@djt12 Asia]# chkconfig iptables off
//永久关闭防火墙
[iyunv@djt12 Asia]# service iptables stop //临时关闭防火墙
[iyunv@djt12 Asia]# service iptables status
iptables: Firewall is not running.
//查看防火墙状态
[iyunv@djt13 Asia]# service iptables status
[iyunv@djt13 Asia]# chkconfig iptables off
//永久关闭防火墙
[iyunv@djt13 Asia]# service iptables stop //临时关闭防火墙
[iyunv@djt13 Asia]# service iptables status
iptables: Firewall is not running.
//查看防火墙状态
[iyunv@djt14 Asia]# service iptables status
[iyunv@djt14 Asia]# chkconfig iptables off
//永久关闭防火墙
[iyunv@djt14 Asia]# service iptables stop //临时关闭防火墙
[iyunv@djt14 Asia]# service iptables status
iptables: Firewall is not running.
//查看防火墙状态
[iyunv@djt15 Asia]# service iptables status
[iyunv@djt15 Asia]# chkconfig iptables off
//永久关闭防火墙
[iyunv@djt15 Asia]# service iptables stop //临时关闭防火墙
[iyunv@djt15 Asia]# service iptables status
iptables: Firewall is not running.
//查看防火墙状态
6、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的SSH免密码通信配置)
配置SSH免密码通信
1、每台机器的各自本身的无密码访问
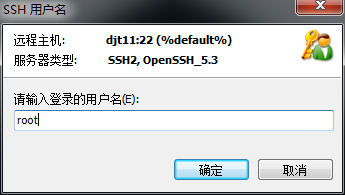
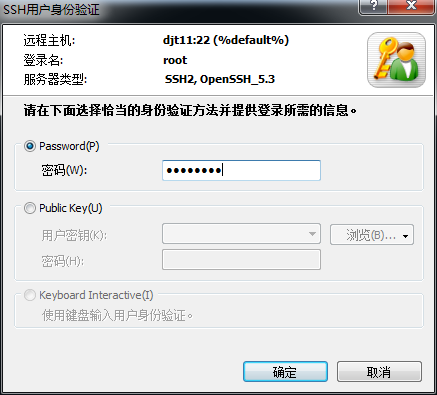
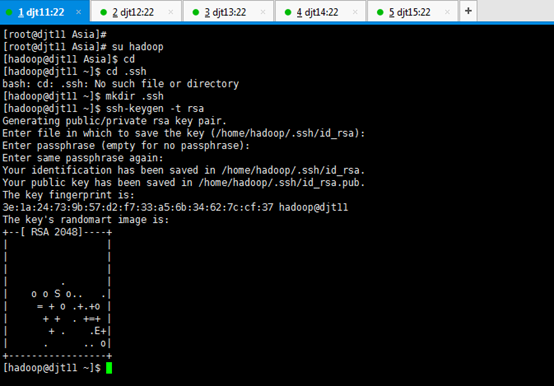
对djt11
[iyunv@djt11 Asia]# su hadoop
[hadoop@djt11 Asia]$ cd
[hadoop@djt11 ~]$ cd .ssh
[hadoop@djt11 ~]$ mkdir .ssh
[hadoop@djt11 ~]$ ssh-keygen -t rsa
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Enter键
Enter passphrase (empty for no passphrase): Enter键
Enter same passphrase again: Enter键
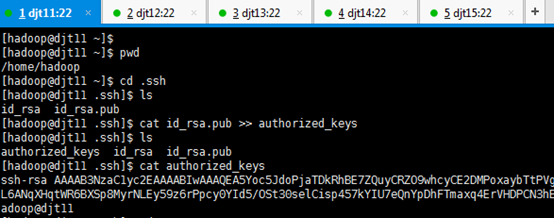
[hadoop@djt11 ~]$ pwd
[hadoop@djt11 ~]$ cd .ssh
[hadoop@djt11 .ssh]$ ls
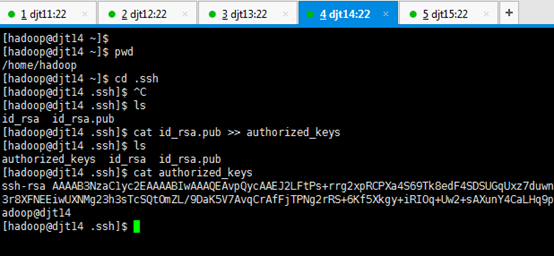
[hadoop@djt11 .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@djt11 .ssh]$ ls
[hadoop@djt11 .ssh]$ cat authorized_keys
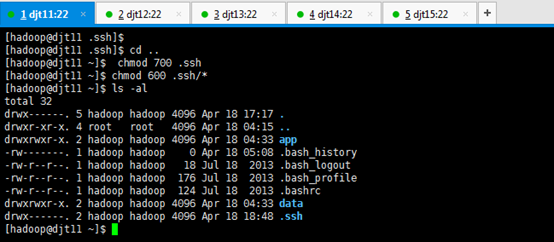
[hadoop@djt11 .ssh]$ cd ..
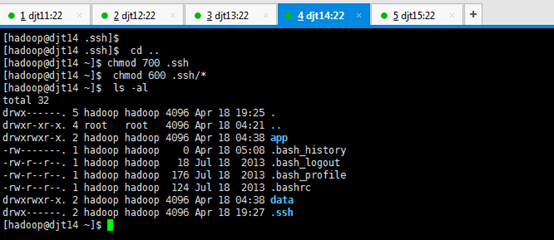
[hadoop@djt11 ~]$ chmod 700 .ssh
[hadoop@djt11 ~]$ chmod 600 .ssh/*
[hadoop@djt11 ~]$ ls -al
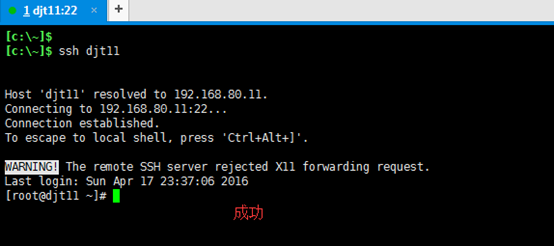
[hadoop@djt11 ~]$ ssh djt11
[hadoop@djt11 ~]$ su root
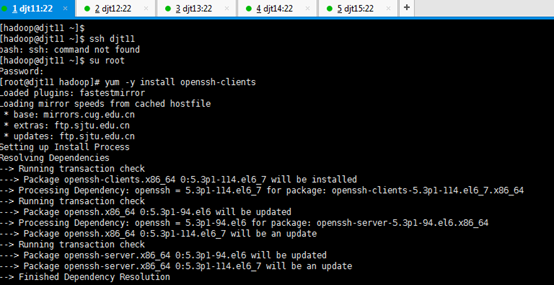
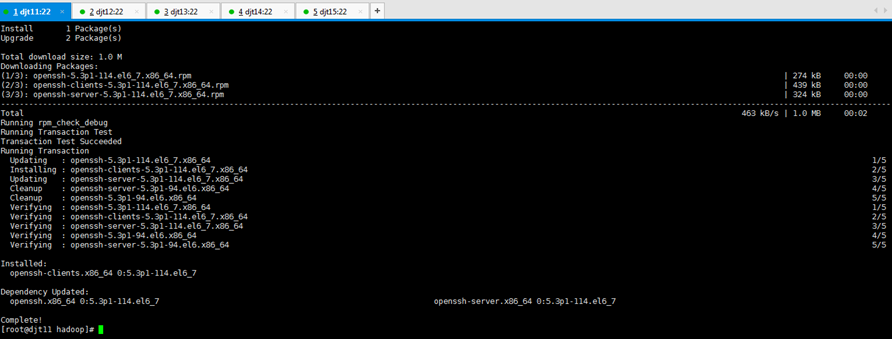
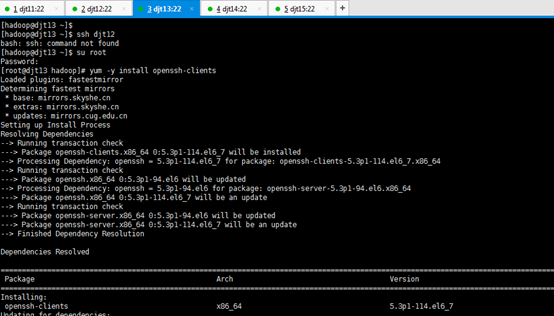
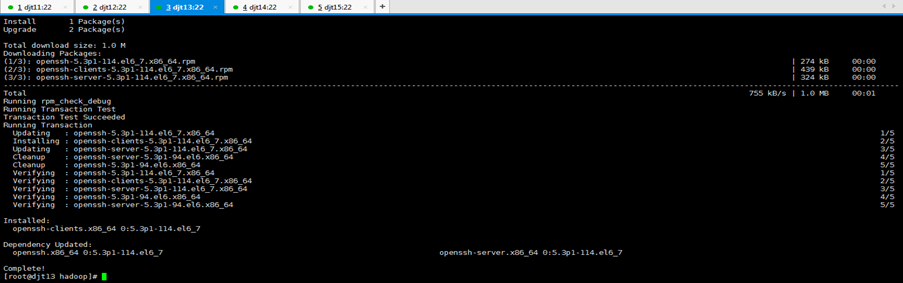
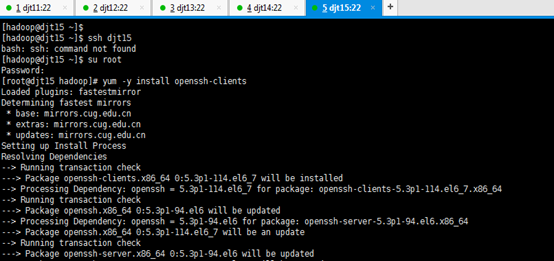
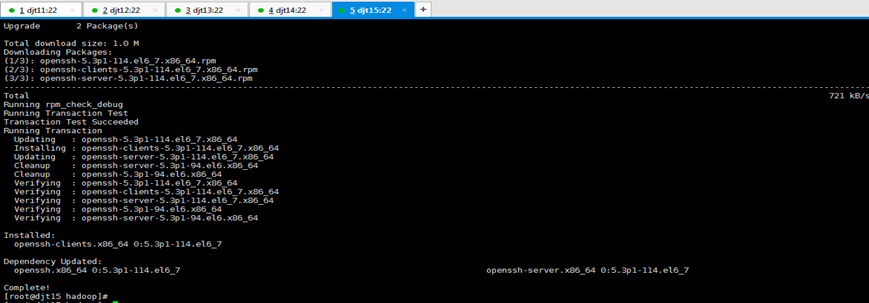
[iyunv@djt11 hadoop]# yum -y install openssh-clients
对djt11安装ssh命令成功
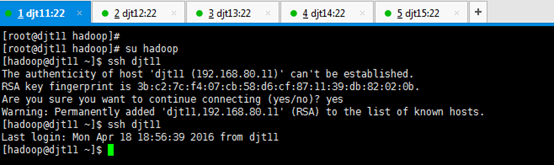
[iyunv@djt11 hadoop]# su hadoop
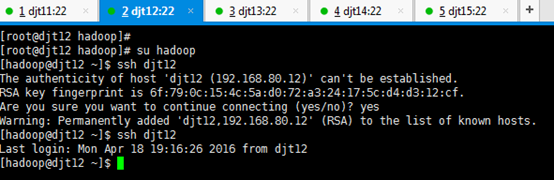
[hadoop@djt11 ~]$ ssh djt11
Are you sure you want to continue connecting (yes/no)? yes
[hadoop@djt11 ~]$ ssh djt11
对djt12
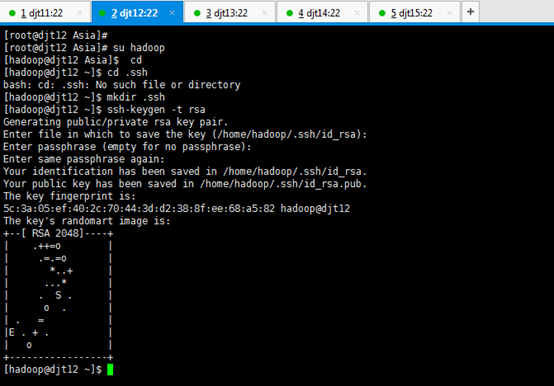
[iyunv@djt12 Asia]# su hadoop
[hadoop@djt12 Asia]$ cd
[hadoop@djt12 ~]$ cd .ssh
[hadoop@djt12 ~]$ mkdir .ssh
[hadoop@djt12 ~]$ ssh-keygen -t rsa
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Enter
Enter passphrase (empty for no passphrase): Enter键
Enter same passphrase again: Enter键
[hadoop@djt12 ~]$ pwd
[hadoop@djt12 ~]$ cd .ssh
[hadoop@djt12 .ssh]$ ls
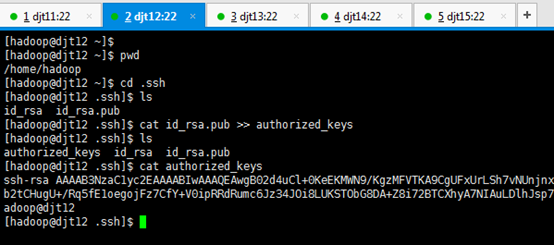
[hadoop@djt12 .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@djt12 .ssh]$ ls
[hadoop@djt12 .ssh]$ cat authorized_keys
[hadoop@djt12 .ssh]$ cd ..
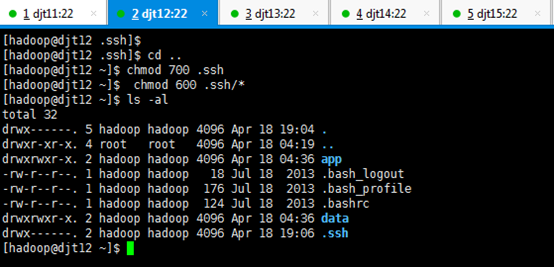
[hadoop@djt12 ~]$ chmod 700 .ssh
[hadoop@djt12 ~]$ chmod 600 .ssh/*
[hadoop@djt12 ~]$ ls -al
对djt12进行ssh命令,安装成功
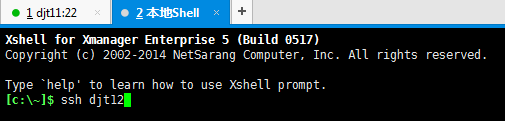
[hadoop@djt12 ~]$ ssh djt12
[hadoop@djt12 ~]$ su root
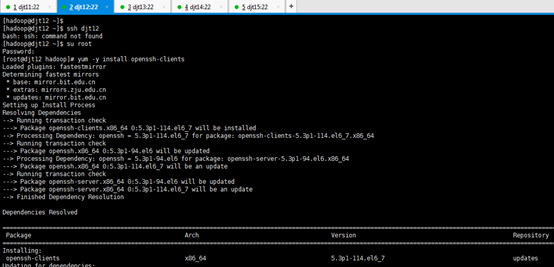
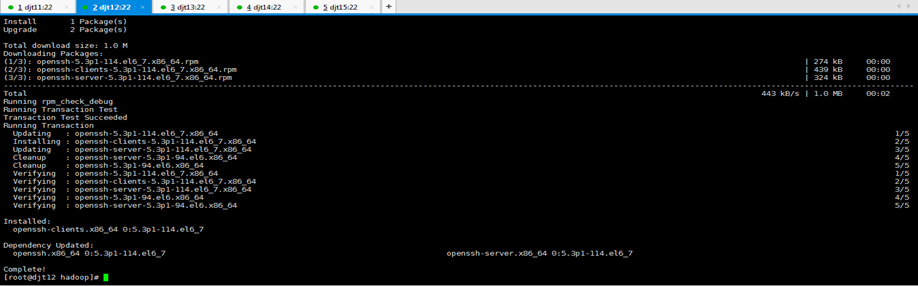
[iyunv@djt12 hadoop]# yum -y install openssh-clients
[iyunv@djt12 hadoop]# su hadoop
[hadoop@djt12 ~]$ ssh djt12
Are you sure you want to continue connecting (yes/no)? yes
[hadoop@djt12 ~]$ ssh djt12
对djt13
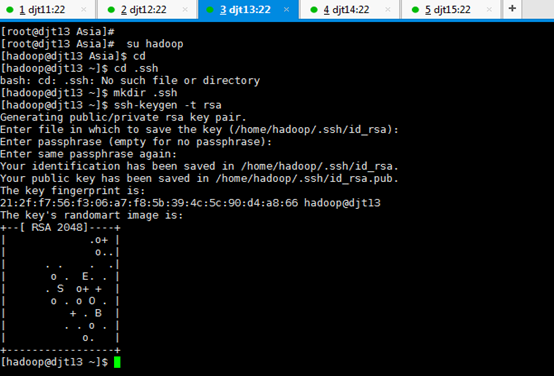
[iyunv@djt13 Asia]# su hadoop
[hadoop@djt13 Asia]$ cd
[hadoop@djt13 ~]$ cd .ssh
[hadoop@djt13 ~]$ mkdir .ssh
[hadoop@djt13 ~]$ ssh-keygen -t rsa
[hadoop@djt13 ~]$ pwd
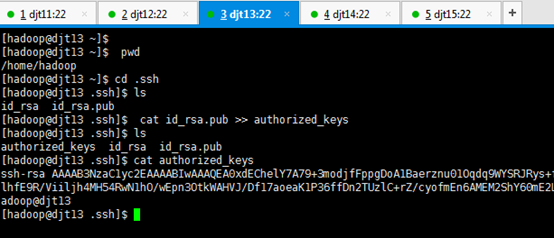
[hadoop@djt13 ~]$ cd .ssh
[hadoop@djt13 .ssh]$ ls
[hadoop@djt13 .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@djt13 .ssh]$ ls
[hadoop@djt13 .ssh]$ cat authorized_keys
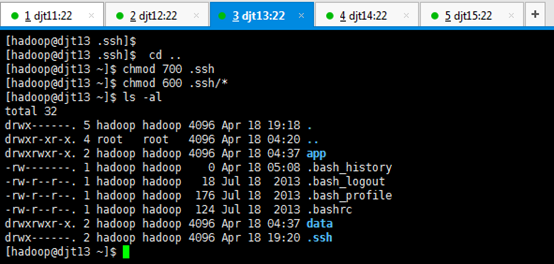
[hadoop@djt13 .ssh]$ cd ..
[hadoop@djt13 ~]$ chmod 700 .ssh
[hadoop@djt13 ~]$ chmod 600 .ssh/*
[hadoop@djt13 ~]$ ls -al
[hadoop@djt13 ~]$ ssh djt13
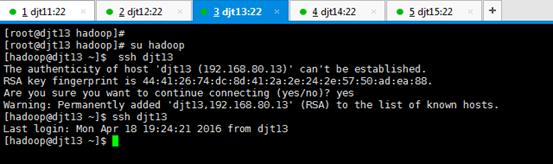
[hadoop@djt13 ~]$ su root
[iyunv@djt13 hadoop]# yum -y install openssh-clients
对djt13进行ssh命令,安装成功
[iyunv@djt13 hadoop]# su hadoop
[hadoop@djt13 ~]$ ssh djt13
Are you sure you want to continue connecting (yes/no)? yes
[hadoop@djt13 ~]$ ssh djt13
对djt14
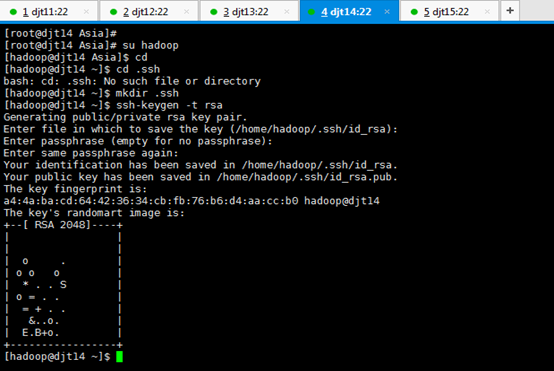
[iyunv@djt14 Asia]# su hadoop
[hadoop@djt14 Asia]$ cd
[hadoop@djt14 ~]$ cd .ssh
[hadoop@djt14 ~]$ mkdir .ssh
[hadoop@djt14 ~]$ ssh-keygen -t rsa
[hadoop@djt14 ~]$ pwd
[hadoop@djt14 ~]$ cd .ssh
[hadoop@djt14 .ssh]$ ls
[hadoop@djt14 .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@djt14 .ssh]$ ls
[hadoop@djt14 .ssh]$ cat authorized_keys
[hadoop@djt14 .ssh]$ cd ..
[hadoop@djt14 ~]$ chmod 700 .ssh
[hadoop@djt14 ~]$ chmod 600 .ssh/*
[hadoop@djt14 ~]$ ls -al
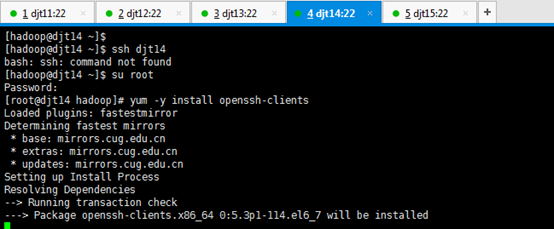
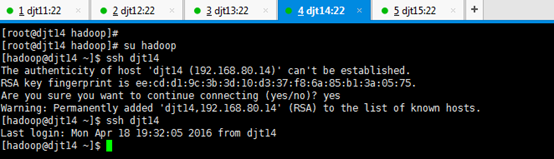
[hadoop@djt14 ~]$ ssh djt14
[hadoop@djt14 ~]$ su root
[iyunv@djt14 hadoop]# yum -y install openssh-clients
对djt14进行ssh命令,安装成功
[iyunv@djt14 hadoop]# su hadoop
[hadoop@djt14 ~]$ ssh djt14
Are you sure you want to continue connecting (yes/no)? yes
[hadoop@djt14 ~]$ ssh djt14
对djt15
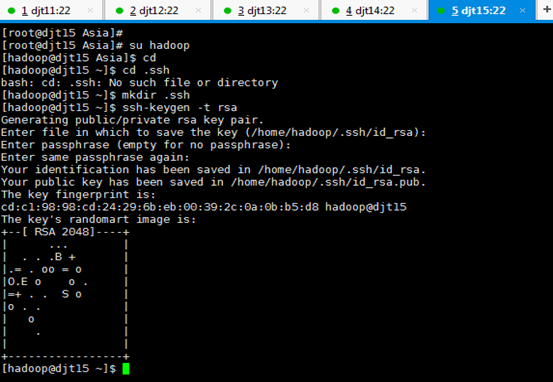
[iyunv@djt15 Asia]# su hadoop
[hadoop@djt15 Asia]$ cd
[hadoop@djt15 ~]$ cd .ssh
[hadoop@djt15 ~]$ mkdir .ssh
[hadoop@djt15 ~]$ ssh-keygen -t rsa
[hadoop@djt15 ~]$ pwd
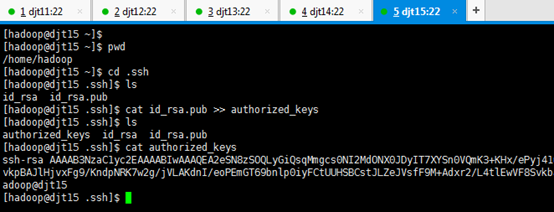
[hadoop@djt15 ~]$ cd .ssh
[hadoop@djt15 .ssh]$ ls
[hadoop@djt15 .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@djt15 .ssh]$ ls
[hadoop@djt15 .ssh]$ cat authorized_keys
[hadoop@djt15 .ssh]$ cd ..
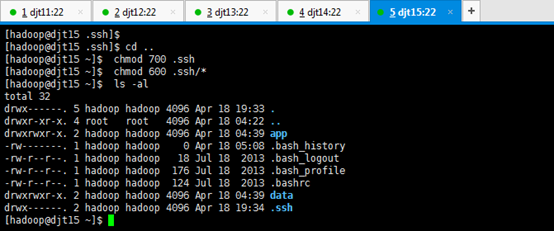
[hadoop@djt15 ~]$ chmod 700 .ssh
[hadoop@djt15 ~]$ chmod 600 .ssh/*
[hadoop@djt15 ~]$ ls -al
[hadoop@djt15 ~]$ ssh djt14
[hadoop@djt15 ~]$ su root
[iyunv@djt15 hadoop]# yum -y install openssh-clients
对djt15进行ssh命令,安装成功
[iyunv@djt15 hadoop]# su hadoop
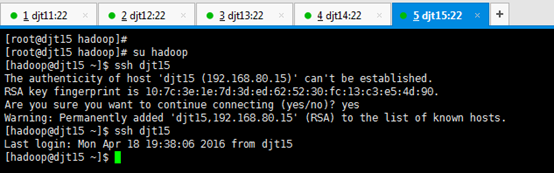
[hadoop@djt15 ~]$ ssh djt15
Are you sure you want to continue connecting (yes/no)? yes
[hadoop@djt15 ~]$ ssh djt15
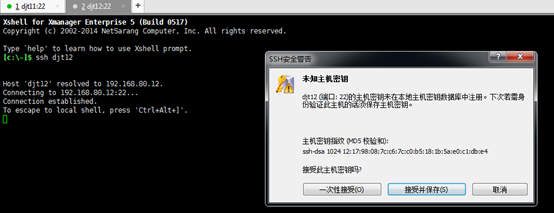
集群所有节点都要行上面的操作。依次,对djt11、djt12、djt13、djt14、 djt15进行SSH。
即,此刻,1、每台机器的各自本身的无密码访问已经成功设置好了。
2、现在来实现每台机器的之间无密码访问的设置?
首先,将所有节点中的共钥id_ras.pub拷贝到djt11中的authorized_keys文件中。
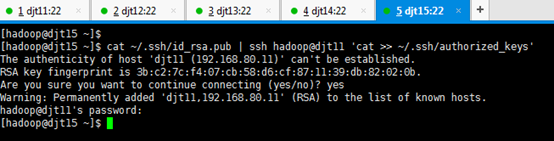
cat ~/.ssh/id_rsa.pub | ssh hadoop@djt11 'cat >> ~/.ssh/authorized_keys' 所有节点都需要执行这条命令。
2.1 完成djt12与djt11,djt13与djt11,djt14与djt11,djt15与djt11链接
2.1.1 djt12与djt11实现无密码访问
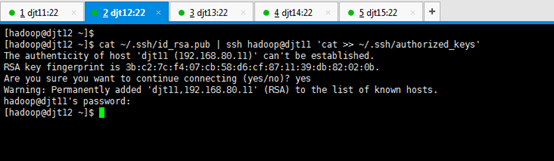
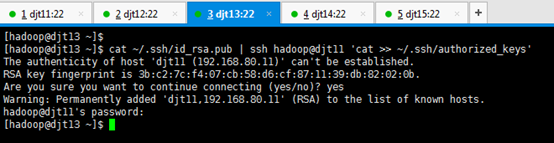
[hadoop@djt12 ~]$ cat ~/.ssh/id_rsa.pub | ssh hadoop@djt11 'cat >> ~/.ssh/authorized_keys'
Are you sure you want to continue connecting (yes/no)? yes
hadoop@djt11's password:(是djt11用户hadoop的密码是,hadoop)
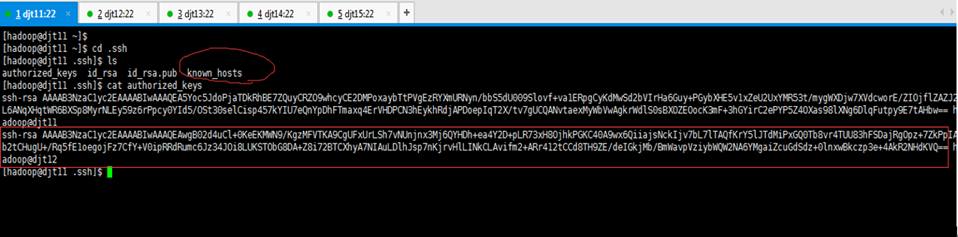
[hadoop@djt11 ~]$ cd .ssh
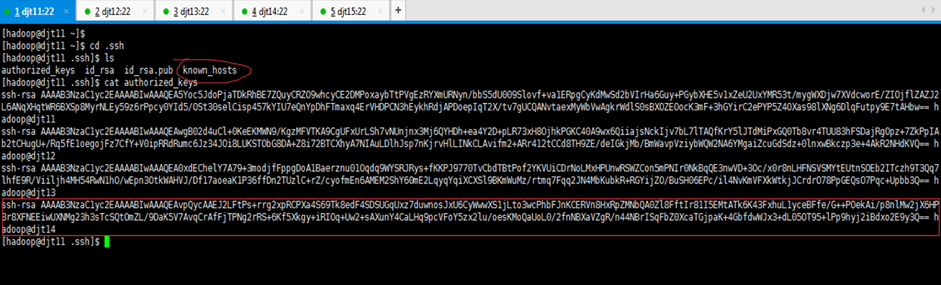
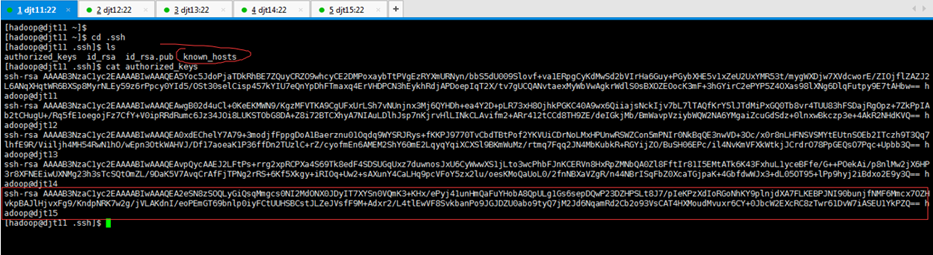
[hadoop@djt11 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[hadoop@djt11 .ssh]$ cat authorized_keys
known_hostss是,该档案是纪录连到对方时,对方给的 host key。每次连线时都会检查目前对方给的 host key 与纪录的 host key 是否相同,可以简单验证连结是否又被诈骗等相关事宜。
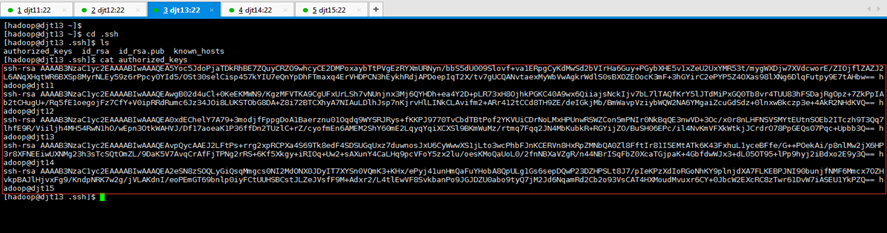
2.1.2 djt13与djt11实现无密码访问
[hadoop@djt13 ~]$ cat ~/.ssh/id_rsa.pub | ssh hadoop@djt11 'cat >> ~/.ssh/authorized_keys'
Are you sure you want to continue connecting (yes/no)? yes
hadoop@djt11's password:(是djt11用户hadoop的密码是,hadoop)
[hadoop@djt11 ~]$ cd .ssh
[hadoop@djt11 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[hadoop@djt11 .ssh]$ cat authorized_keys
known_hostss是,该档案是纪录连到对方时,对方给的 host key。每次连线时都会检查目前对方给的 host key 与纪录的 host key 是否相同,可以简单验证连结是否又被诈骗等相关事宜。
2.1.3djt14 与djt11实现无密码访问
[hadoop@djt14 ~]$ cat ~/.ssh/id_rsa.pub | ssh hadoop@djt11 'cat >> ~/.ssh/authorized_keys'
Are you sure you want to continue connecting (yes/no)? yes
hadoop@djt11's password:(是djt11用户hadoop的密码是,hadoop)
[hadoop@djt11 ~]$ cd .ssh
[hadoop@djt11 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[hadoop@djt11 .ssh]$ cat authorized_keys
2.1.4 djt15与djt11实现无密码访问
[hadoop@djt15 ~]$ cat ~/.ssh/id_rsa.pub | ssh hadoop@djt11 'cat >> ~/.ssh/authorized_keys'
Are you sure you want to continue connecting (yes/no)? yes
hadoop@djt11's password:(是djt11用户hadoop的密码是,hadoop)
[hadoop@djt11 ~]$ cd .ssh
[hadoop@djt11 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[hadoop@djt11 .ssh]$ cat authorized_keys
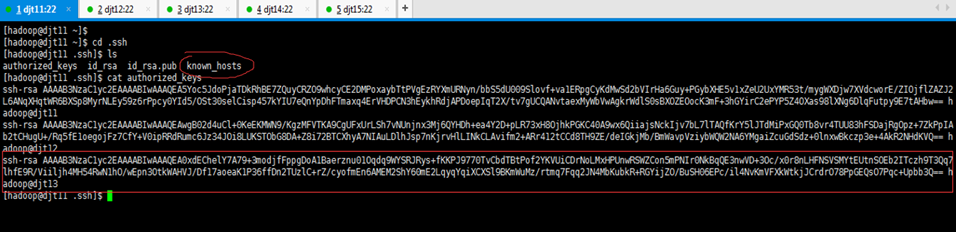
即,以上是完成如下的工作。
djt12与djt11链接,djt13与djt11链接,djt14与djt11链接,djt15与djt11链接
这里是重点!!!
2.2 将djt11中的authorized_keys文件分发到所有节点上面
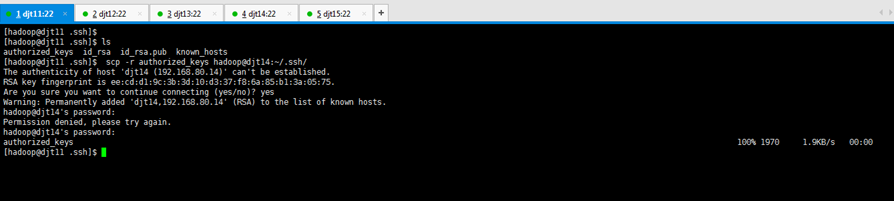
2.2.1 将djt11中的authorized_keys文件分发到djt12节点上面
[hadoop@djt11 .ssh]$ ls
[hadoop@djt11 .ssh]$ scp -r authorized_keys hadoop@djt12:~/.ssh/
Are you sure you want to continue connecting (yes/no)? yes
hadoop@djt12's password:(djt12的hadoop用户的密码,是hadoop)
[hadoop@djt12 ~]$ cd .ssh
[hadoop@djt12 .ssh]$ ls
[hadoop@djt12 .ssh]$ cat authorized_keys
2.2.2 将djt11中的authorized_keys文件分发到djt13节点上面
[hadoop@djt11 .ssh]$ ls
[hadoop@djt11 .ssh]$ scp -r authorized_keys hadoop@djt13:~/.ssh/
Are you sure you want to continue connecting (yes/no)? yes
hadoop@djt13's password:(djt13的hadoop用户的密码,是hadoop)
[hadoop@djt13 ~]$ cd .ssh
[hadoop@djt13 .ssh]$ ls
[hadoop@djt13 .ssh]$ cat authorized_keys
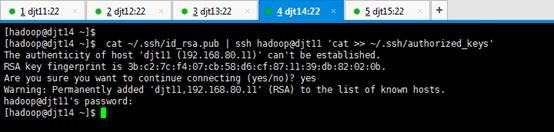
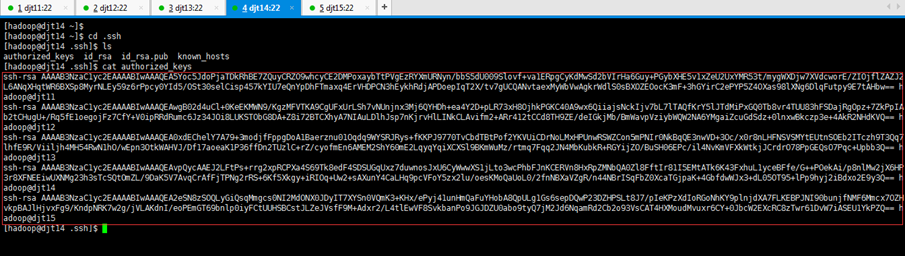
2.2.3 将djt11中的authorized_keys文件分发到djt14节点上面
[hadoop@djt11 .ssh]$ ls
[hadoop@djt11 .ssh]$ scp -r authorized_keys hadoop@djt14:~/.ssh/
Are you sure you want to continue connecting (yes/no)? yes
hadoop@djt14's password:(djt14的hadoop用户的密码,是hadoop)
[hadoop@djt14 ~]$ cd .ssh
[hadoop@djt14 .ssh]$ ls
[hadoop@djt14 .ssh]$ cat authorized_keys
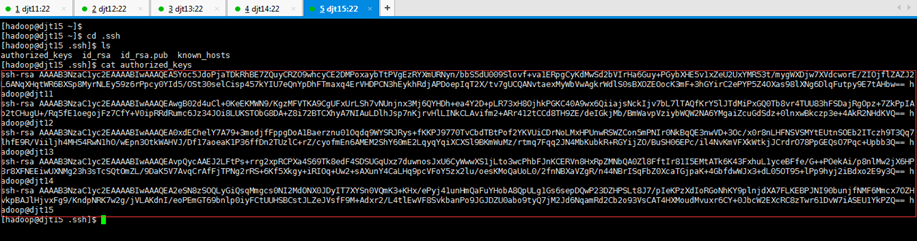
2.2.4 将djt11中的authorized_keys文件分发到djt15节点上面
[hadoop@djt11 .ssh]$ ls
[hadoop@djt11 .ssh]$ scp -r authorized_keys hadoop@djt15:~/.ssh/
Are you sure you want to continue connecting (yes/no)? yes
hadoop@djt15's password:(djt15的hadoop用户的密码,是hadoop)
[hadoop@djt15 ~]$ cd .ssh
[hadoop@djt15 .ssh]$ ls
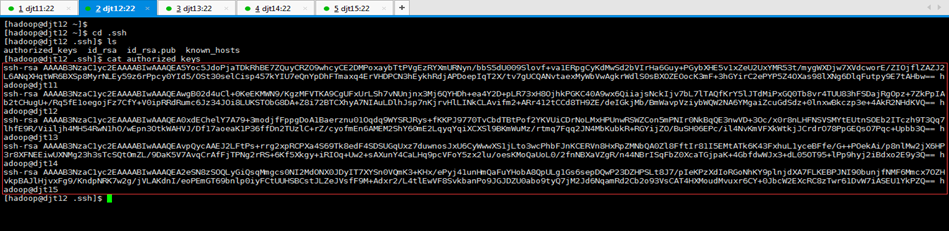
[hadoop@djt15 .ssh]$ cat authorized_keys
大家通过ssh 相互访问,如果都能无密码访问,代表ssh配置成功。
现在,再来之间访问,则可实现无密码访问了。
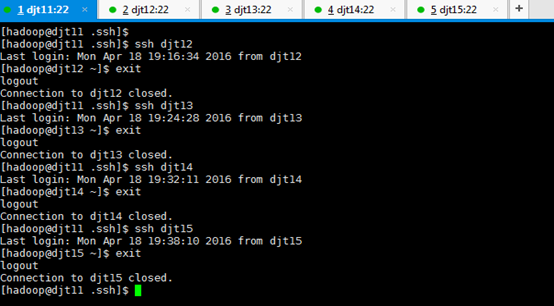
从djt11出发,
[hadoop@djt11 .ssh]$ ssh djt12
[hadoop@djt12 ~]$ exit
[hadoop@djt11 .ssh]$ ssh djt13
[hadoop@djt13 ~]$ exit
[hadoop@djt11 .ssh]$ ssh djt14
[hadoop@djt14 ~]$ exit
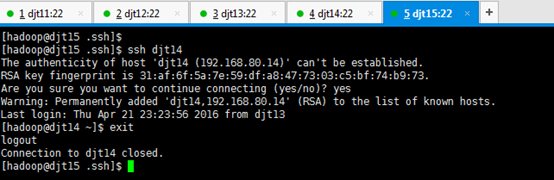
[hadoop@djt11 .ssh]$ ssh djt15
[hadoop@djt15 ~]$ exit
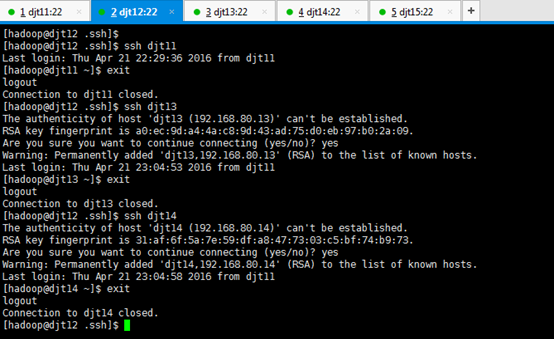
从djt12出发,
注意:因为,在这里djt12与djt11是第一次
注意:因为,在这里djt12与djt13是第一次
注意:因为,在这里djt12与djt14是第一次
[hadoop@djt12 .ssh]$ ssh djt11
[hadoop@djt11 ~]$ exit
Connection to djt11 closed.
[hadoop@djt12 .ssh]$ ssh djt13
Are you sure you want to continue connecting (yes/no)? yes
[hadoop@djt13 ~]$ exit
Connection to djt13 closed.
[hadoop@djt12 .ssh]$ ssh djt14
Are you sure you want to continue connecting (yes/no)? yes
[hadoop@djt14 ~]$ exit
Connection to djt14 closed.
[hadoop@djt12 .ssh]$
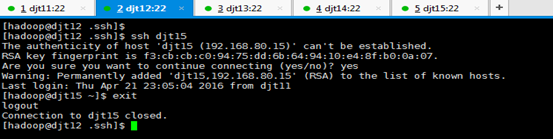
注意:因为,在这里djt12与djt15是第一次
[hadoop@djt12 .ssh]$ ssh djt15
Are you sure you want to continue connecting (yes/no)? yes
Connection to djt15 closed.
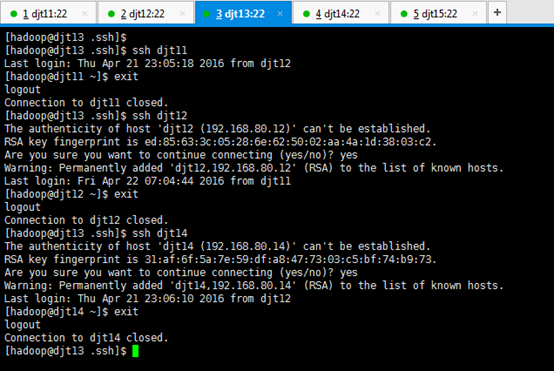
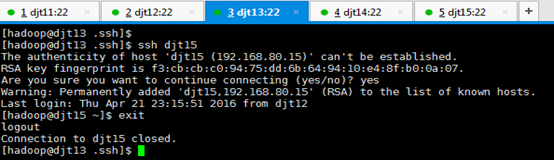
从djt13出发,
[hadoop@djt13 .ssh]$ ssh djt11
[hadoop@djt11 ~]$ exit
[hadoop@djt13 .ssh]$ ssh djt12
[hadoop@djt12 ~]$ exit
[hadoop@djt13 .ssh]$ ssh djt12
[hadoop@djt12 ~]$ exit
[hadoop@djt13 .ssh]$ ssh djt14
[hadoop@djt14 ~]$ exit
[hadoop@djt13 .ssh]$ ssh djt15
[hadoop@djt15 ~]$ exit
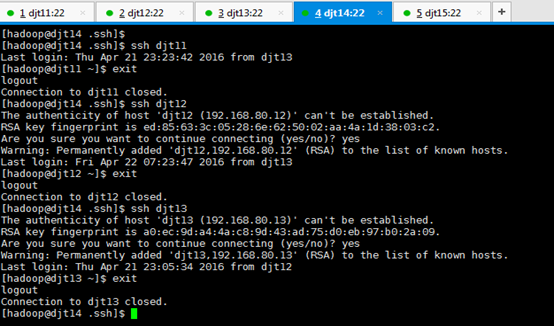
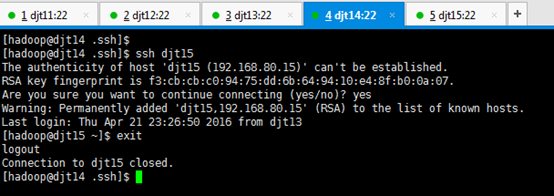
从djt14出发,
[hadoop@djt14 .ssh]$ ssh djt11
[hadoop@djt11 ~]$ exit
[hadoop@djt14 .ssh]$ ssh djt12
[hadoop@djt12 ~]$ exit
[hadoop@djt14 .ssh]$ ssh djt13
[hadoop@djt13 ~]$ exit
[hadoop@djt14 .ssh]$ ssh djt15
[hadoop@djt15 ~]$ exit
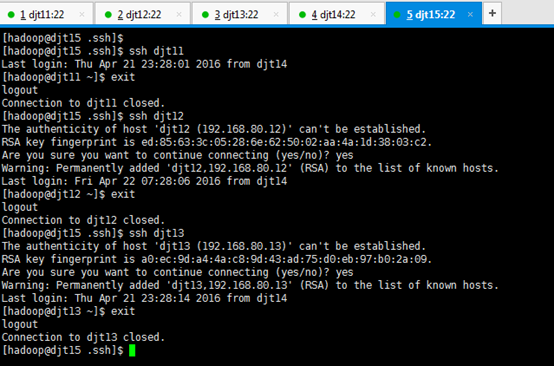
从djt15出发,
[hadoop@djt15 .ssh]$ ssh djt11
[hadoop@djt11 ~]$ exit
[hadoop@djt15 .ssh]$ ssh djt12
[hadoop@djt12 ~]$ exit
[hadoop@djt15 .ssh]$ ssh djt13
[hadoop@djt13 ~]$ exit
[hadoop@djt15 .ssh]$ ssh djt13
[hadoop@djt14 ~]$ exit
7 、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的jdk安装)
jdk安装
其实啊,jdk安装这一步,只需要对djt11进行jdk上传,用后面的命令,如下
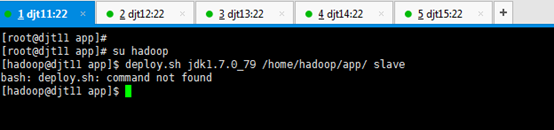
deploy.sh jdk1.7.0_79/ /home/hadoop/app/ slave
或
sh deploy.sh jdk1.7.0_79/ /home/hadoop/app/ slave
即可。即完成,等价于分别rz上传jdk工作,之后,再各自进行环境变量配置。
对djt11
1、将本地下载好的jdk1.7,上传至djt11节点下的/home/hadoop/app目录。
[hadoop@djt11 .ssh]$ cd
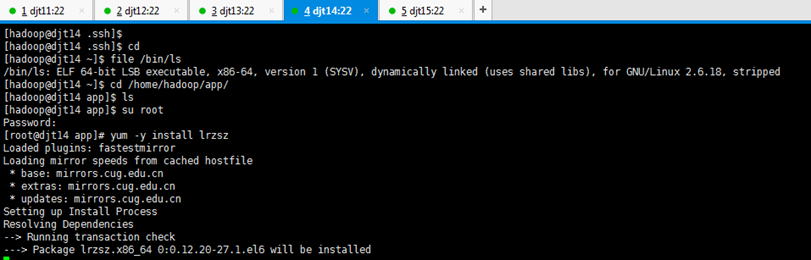
[hadoop@djt11 ~]$ file /bin/ls
[hadoop@djt11 ~]$ cd /home/hadoop/app/
[hadoop@djt11 app]$ ls
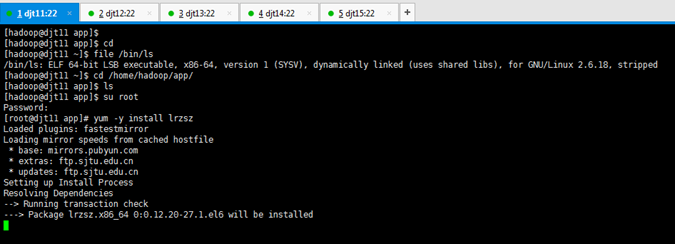
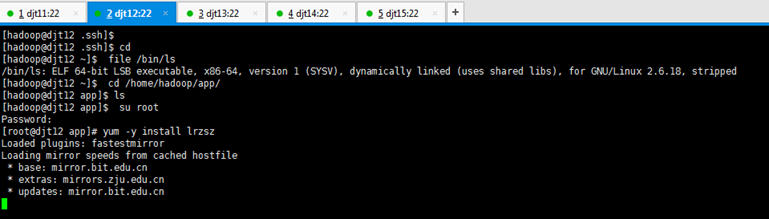
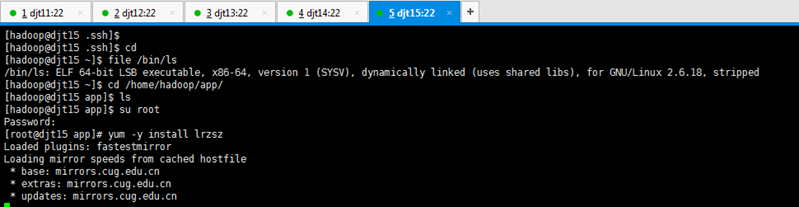
[hadoop@djt11 app]$ su root
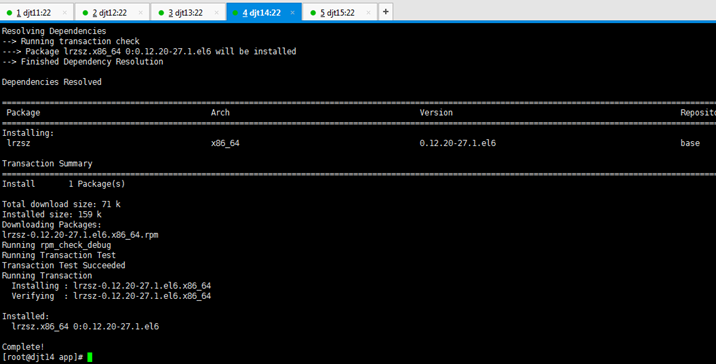
[iyunv@djt11 app]# yum -y install lrzsz
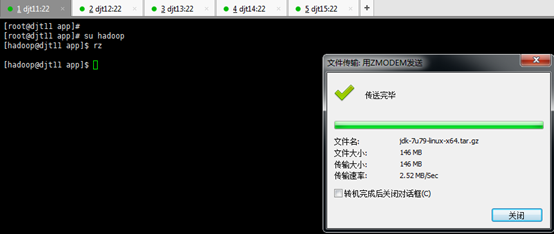
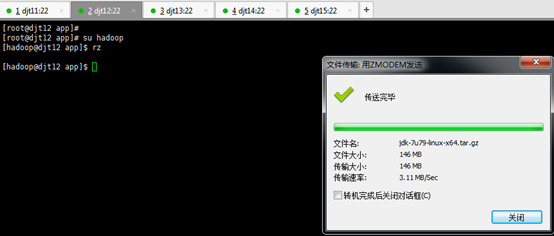
对rzsz命令,安装成功
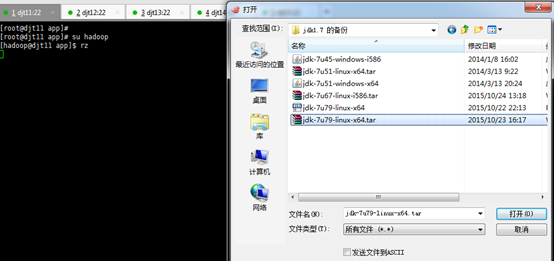
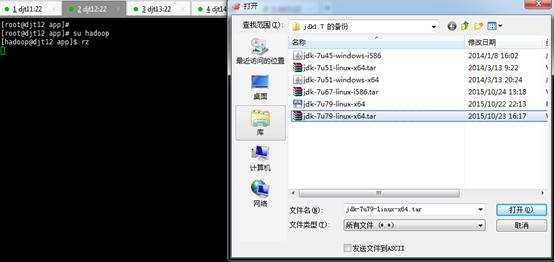
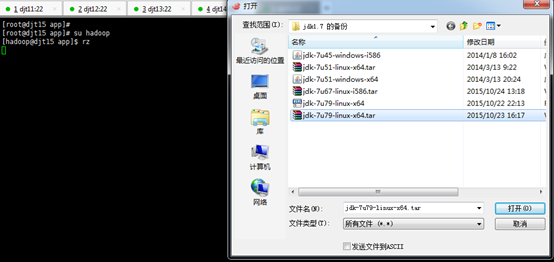
[iyunv@djt11 app]# su hadoop
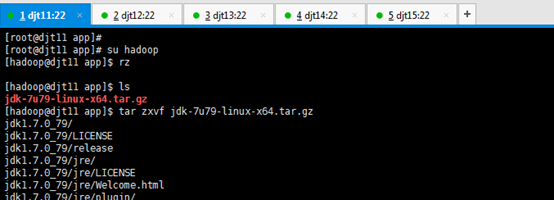
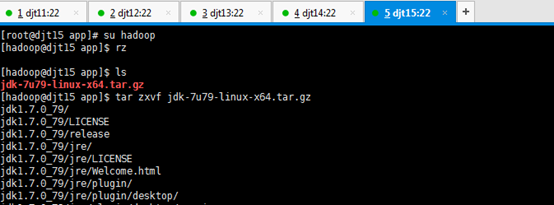
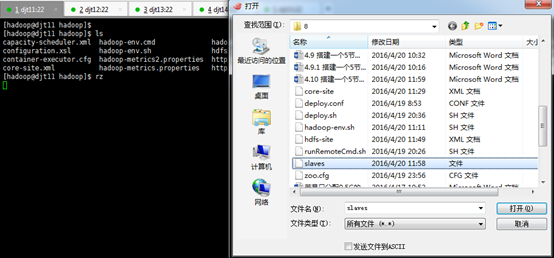
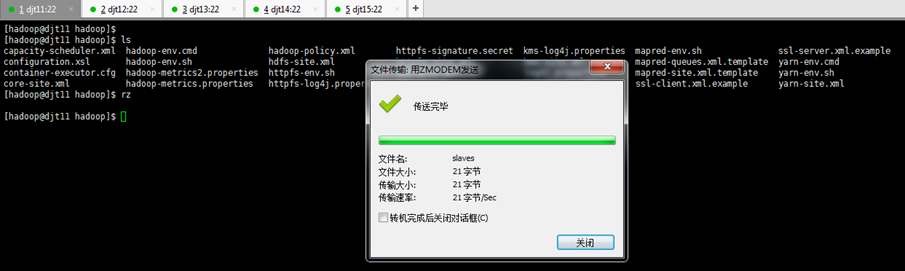
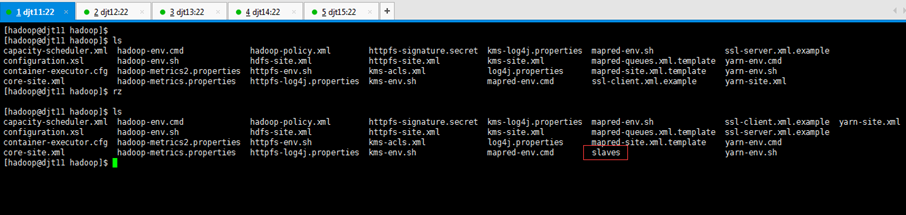
[hadoop@djt11 app]$ rz
[hadoop@djt11 app]$ ls
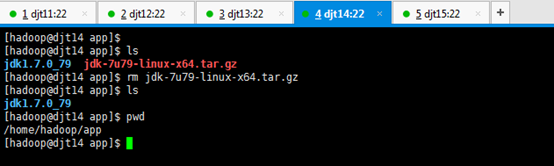
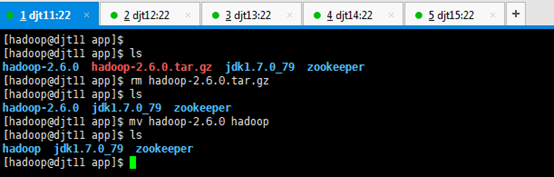
[hadoop@djt11 app]$ tar zxvf jdk-7u79-linux-x64.tar.gz
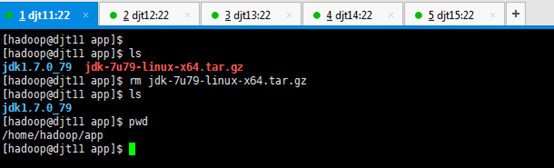
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ rm jdk-7u79-linux-x64.tar.gz
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ pwd
2、添加jdk环境变量。
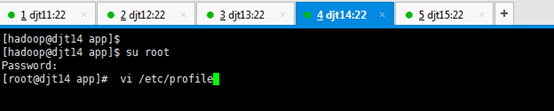
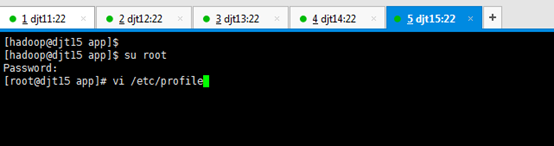
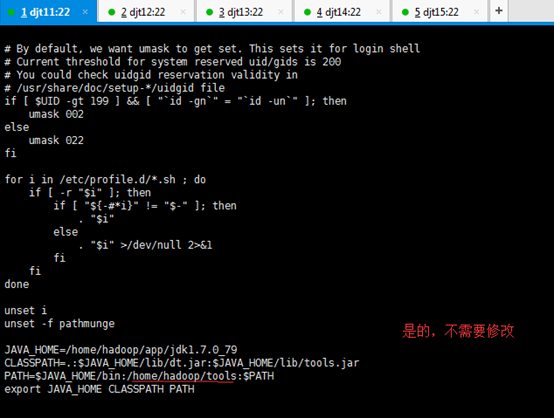
[hadoop@djt11 app]$ su root
[iyunv@djt11 app]# vi /etc/pro
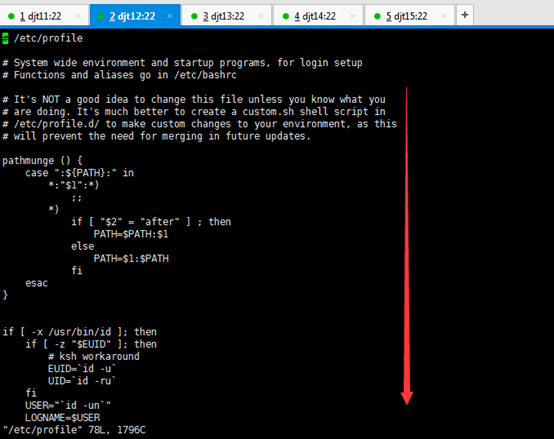
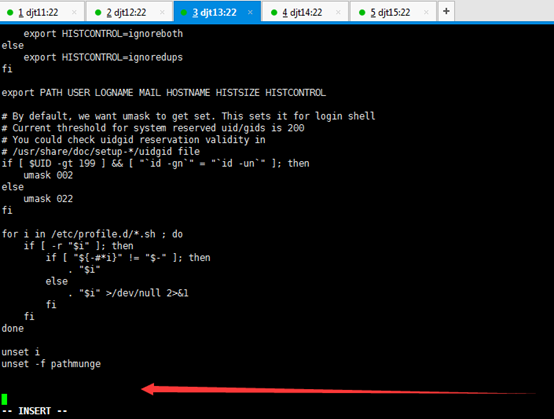
[iyunv@djt11 app]# vi /etc/profile
一直往下走。
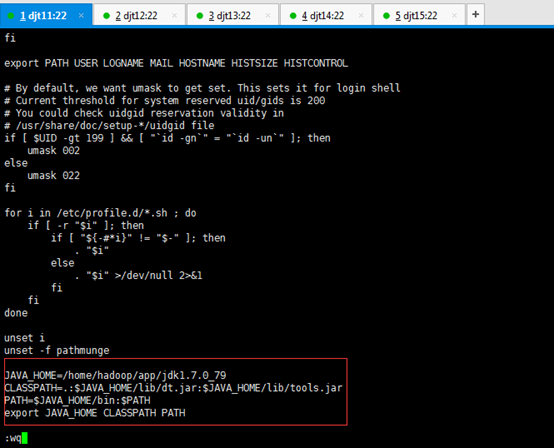
在最尾端,追加。
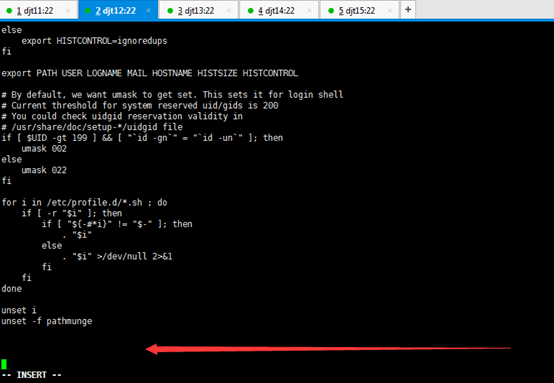
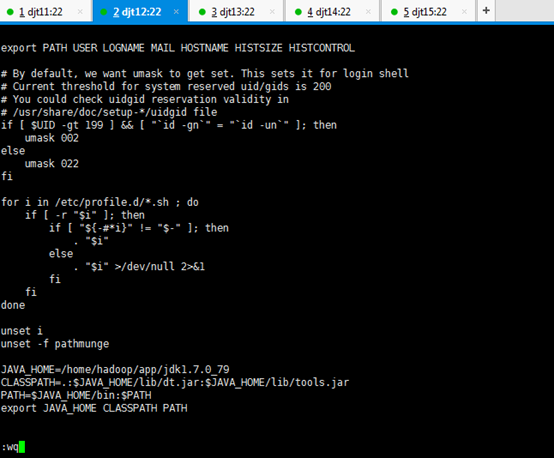
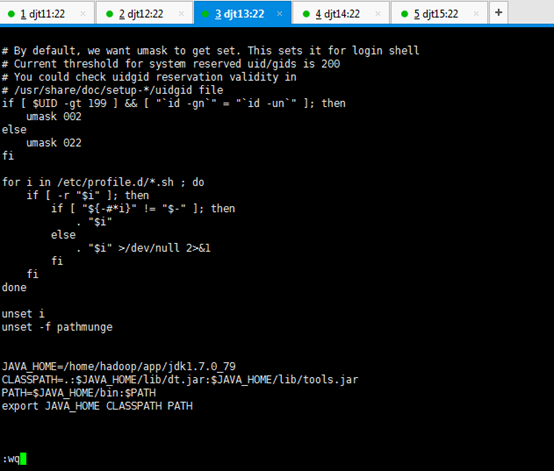
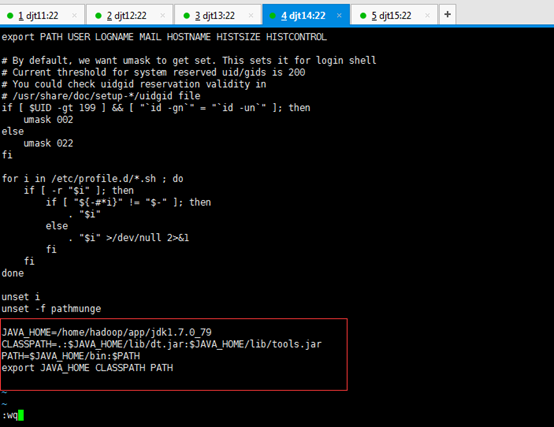
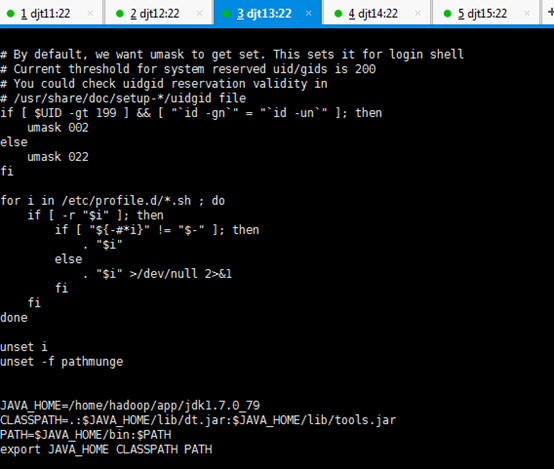
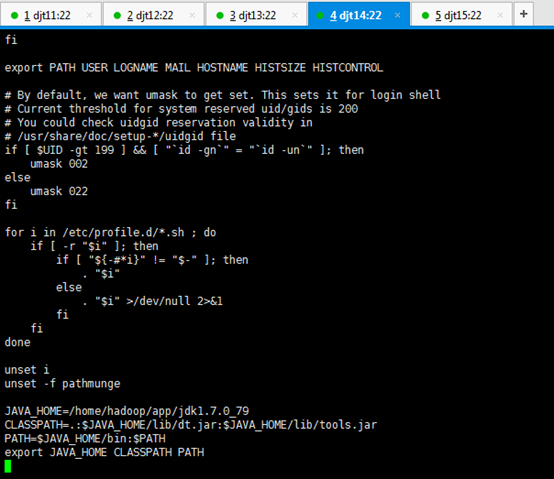
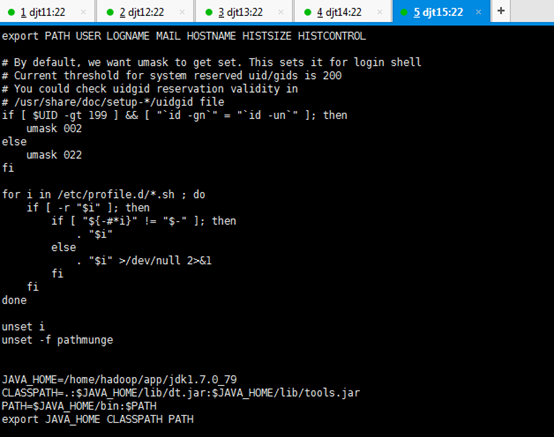
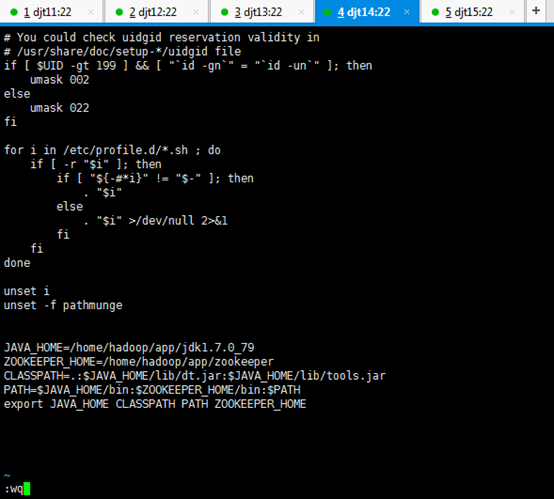
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
3、查看jdk是否安装成功。
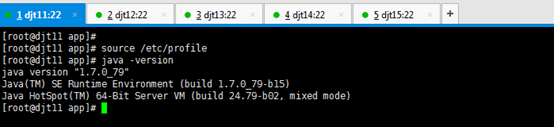
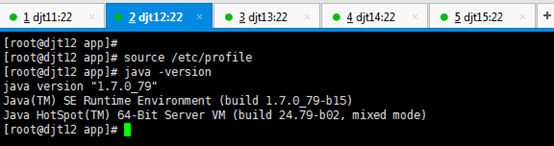
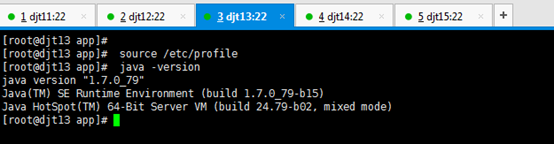
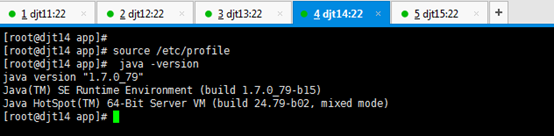
[iyunv@djt11 app]# source /etc/profile
[iyunv@djt11 app]# java -version
出现以上结果就说明djt11节点上的jdk安装成功。
4、然后将djt11下的jdk安装包复制到其他节点上。
[hadoop@djt11 app]$ deploy.sh jdk1.7.0_79 /home/hadoop/app/ slave
其中,slave是djt12,djt13,djt14,djt15的标签。
即,说明的是,djt11是master。 djt12, djt13, djt14, djt15 是slave。
因为,考虑到后续,deploy.sh是,在创建/home/hadoop/tools目录下。
所以,4这一小步,就放到后面去。
djt12,djt13,djt14,djt15节点重复djt11节点上的jdk配置即可。重复!!!
对djt12
1、 将本地下载好的jdk1.7,上传至djt12节点下的/home/hadoop/app目录。
[hadoop@djt12 .ssh]$ cd
[hadoop@djt12 ~]$ file /bin/ls
[hadoop@djt12 ~]$ cd /home/hadoop/app/
[hadoop@djt12 app]$ ls
[hadoop@djt12 app]$ su root
[iyunv@djt12 app]# yum -y install lrzsz
对djt12的rzsz命令,安装成功
[iyunv@djt12 app]# su hadoop
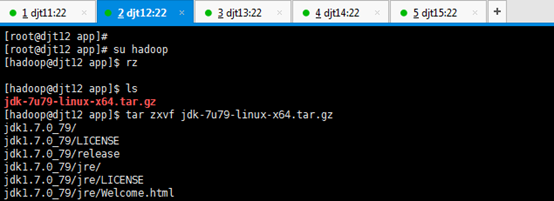
[hadoop@djt12 app]$ rz
[hadoop@djt12 app]$ ls
[hadoop@djt12 app]$ tar zxvf jdk-7u79-linux-x64.tar.gz
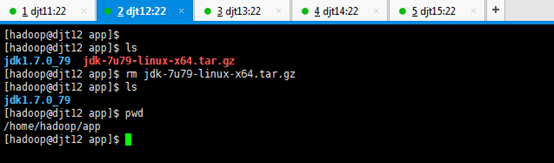
[hadoop@djt12 app]$ ls
[hadoop@djt12 app]$ rm jdk-7u79-linux-x64.tar.gz
[hadoop@djt12 app]$ ls
[hadoop@djt12 app]$ pwd
2、添加jdk环境变量。
[hadoop@djt12 app]$ su root
[iyunv@djt12 app]# vi /etc/profile
一直往下走
在最尾端,追加
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
出现以上结果就说明djt12节点上的jdk安装成功。
[iyunv@djt12 app]# source /etc/profile
[iyunv@djt12 app]# java -version
djt13,djt14,djt15节点重复djt11节点上的jdk配置即可。重复!!!
对djt13
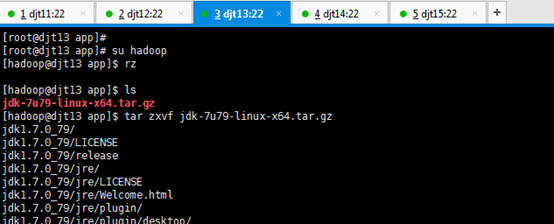
1、 将本地下载好的jdk1.7,上传至djt13节点下的/home/hadoop/app目录。
[hadoop@djt13 .ssh]$ cd
[hadoop@djt13 ~]$ file /bin/ls
[hadoop@djt13 ~]$ cd /home/hadoop/app/
[hadoop@djt13 app]$ ls
[hadoop@djt13 app]$ su root
[iyunv@djt13 app]# yum -y install lrzsz
对djt13的rzsz命令,安装成功
[iyunv@djt13 app]# su hadoop
[hadoop@djt13 app]$ rz
[hadoop@djt13 app]$ ls
[iyunv@djt15 app]# su hadoop
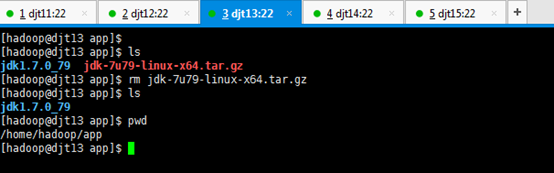
[hadoop@djt13 app]$ tar zxvf jdk-7u79-linux-x64.tar.gz
[hadoop@djt13 app]$ ls
[hadoop@djt13 app]$ rm jdk-7u79-linux-x64.tar.gz
[hadoop@djt13 app]$ ls
[hadoop@djt13 app]$ pwd
2、添加jdk环境变量。
[hadoop@djt13 app]$ su root
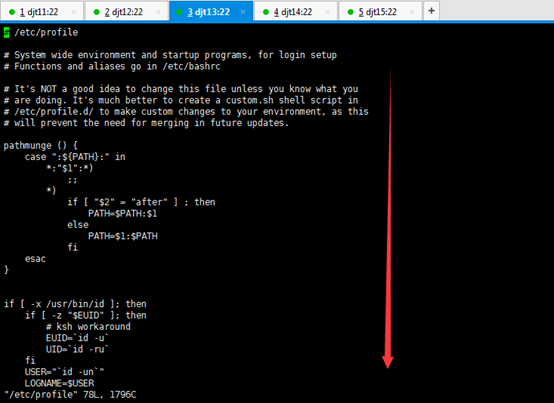
[iyunv@djt13 app]# vi /etc/profile
一直往下走
在最尾端,追加
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
[iyunv@djt13 app]# source /etc/profile
[iyunv@djt13 app]# java -version
出现以上结果就说明djt13节点上的jdk安装成功。
djt14、djt15节点重复djt11节点上的jdk配置即可。重复!!!
对djt14
1、 将本地下载好的jdk1.7,上传至djt14节点下的/home/hadoop/app目录。
[hadoop@djt14 .ssh]$ cd
[hadoop@djt14 ~]$ file /bin/ls
[hadoop@djt14 ~]$ cd /home/hadoop/app/
[hadoop@djt14 app]$ ls
[hadoop@djt14 app]$ su root
[iyunv@djt14app]# yum -y install lrzsz
对djt14的rzsz命令,安装成功
[iyunv@djt14 app]# su hadoop
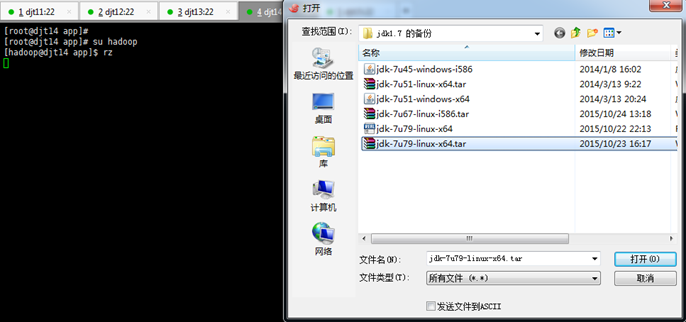
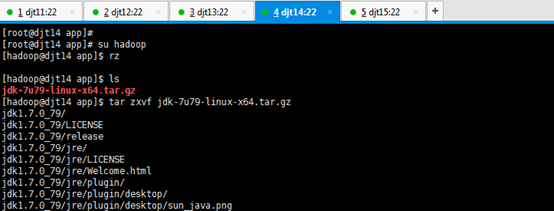
[hadoop@djt14 app]$ rz
[hadoop@djt14 app]$ ls
[hadoop@djt14 app]$ tar zxvf jdk-7u79-linux-x64.tar.gz
[hadoop@djt14 app]$ ls
[hadoop@djt14 app]$ rm jdk-7u79-linux-x64.tar.gz
[hadoop@djt14 app]$ ls
[hadoop@djt14 app]$ pwd
2、添加jdk环境变量。
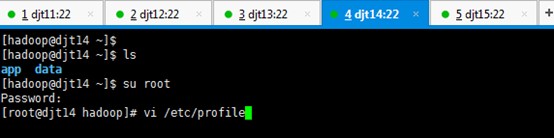
[hadoop@djt14 app]$ su root
[iyunv@djt14 app]# vi /etc/profile
一直往下走
在最尾端,追加
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
出现以上结果就说明djt14节点上的jdk安装成功。
djt15节点重复djt11节点上的jdk配置即可。重复!!!
对djt15
1、 将本地下载好的jdk1.7,上传至djt15节点下的/home/hadoop/app目录。
[hadoop@djt15.ssh]$ cd
[hadoop@djt15 ~]$ file /bin/ls
[hadoop@djt15 ~]$ cd /home/hadoop/app/
[hadoop@djt15 app]$ ls
[hadoop@djt15 app]$ su root
[iyunv@djt15app]# yum -y install lrzsz
对djt15的rzsz命令,安装成功
[iyunv@djt15 app]# su hadoop
[hadoop@djt15 app]$ rz
[hadoop@djt15 app]$ ls
[hadoop@djt15 app]$ tar zxvf jdk-7u79-linux-x64.tar.gz
[hadoop@djt15 app]$ ls
[hadoop@djt15 app]$ rm jdk-7u79-linux-x64.tar.gz
[hadoop@djt15 app]$ ls
[hadoop@djt15 app]$ pwd
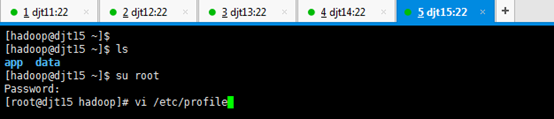
[hadoop@djt15 app]$ su root
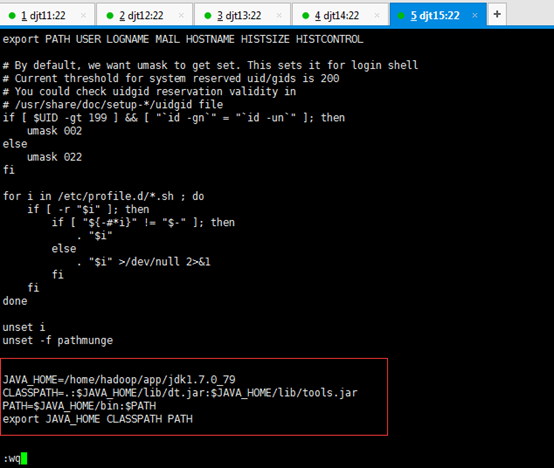
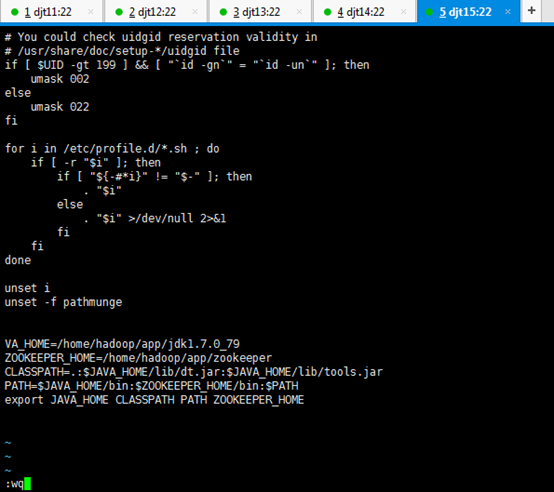
[iyunv@djt15 app]# vi /etc/profile
在最尾端,追加
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
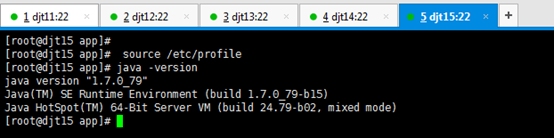
[iyunv@djt15 app]# source /etc/profile
[iyunv@djt15 app]# java -version
出现以上结果就说明djt15节点上的jdk安装成功。
至此,对djt11、djt12、djt13、djt14、djt15 集群安装前的jdk安装,成功。
8、 搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的djt11脚本工具的使用)
脚本工具的使用
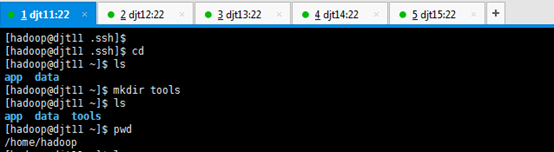
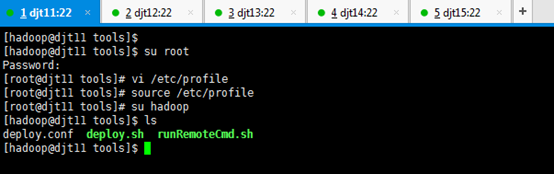
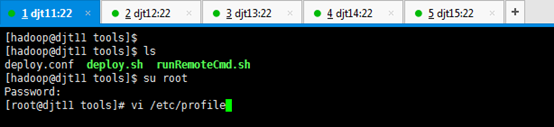
1、在djt11节点上创建/home/hadoop/tools目录。
[hadoop@djt11 .ssh]$ cd
[hadoop@djt11 ~]$ ls
[hadoop@djt11 ~]$ mkdir tools
[hadoop@djt11 ~]$ ls
[hadoop@djt11 ~]$ pwd
[hadoop@djt11 ~]$ su root
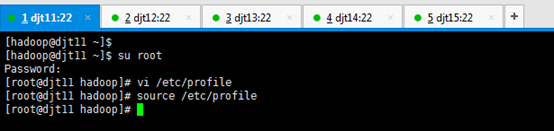
[iyunv@djt11 hadoop]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:/home/hadoop/tools:$PATH
export JAVA_HOME CLASSPATH PATH
[iyunv@djt11 hadoop]$ source /etc/profile
将本地脚本文件上传至/home/hadoop/tools目录下。这些脚本大家如果能看懂也可以自己写, 如果看不懂直接使用就可以,后面慢慢补补Linux相关的知识。
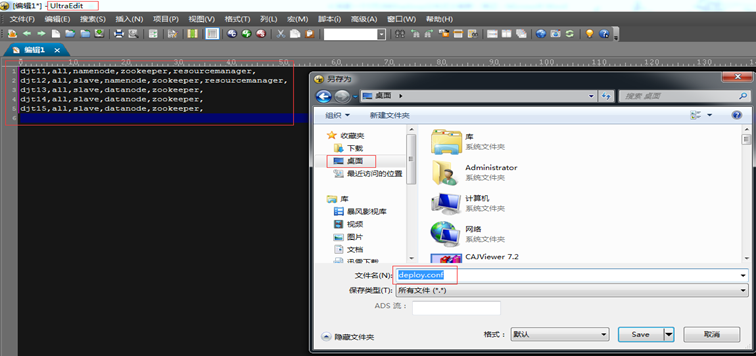
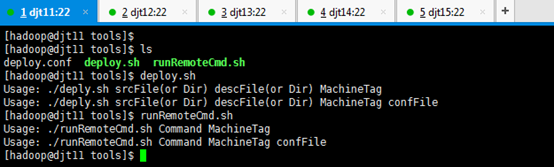
现在,自己编写runRemoteCmd.sh deploy.sh deploy.conf 的内容。
deploy.conf 的内容:
djt11,all,namenode,zookeeper,resourcemanager,
djt12,all,slave,namenode,zookeeper,resourcemanager,
djt13,all,slave,datanode,zookeeper,
djt14,all,slave,datanode,zookeeper,
djt15,all,slave,datanode,zookeeper,
deploy.sh的内容:
#!/bin/bash
#set -x
if [ $# -lt 3 ]
then
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag"
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag confFile"
exit
fi
src=$1
dest=$2
tag=$3
if [ 'a'$4'a' == 'aa' ]
then
confFile=/home/hadoop/tools/deploy.conf
else
confFile=$4
fi
if [ -f $confFile ]
then
if [ -f $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp $src $server":"${dest}
done
elif [ -d $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp -r $src $server":"${dest}
done
else
echo "Error: No source file exist"
fi
else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
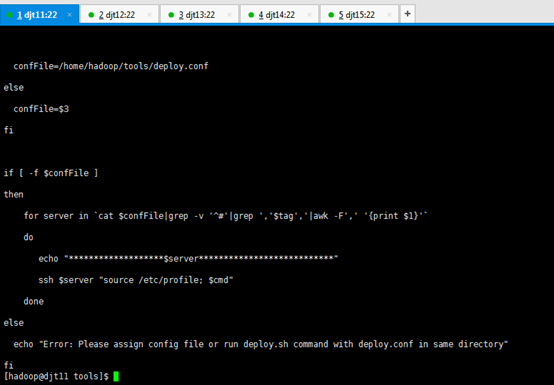
runRemoteCmd.sh 的内容:
#!/bin/bash
#set -x
if [ $# -lt 2 ]
then
echo "Usage: ./runRemoteCmd.sh Command MachineTag"
echo "Usage: ./runRemoteCmd.sh Command MachineTag confFile"
exit
fi
cmd=$1
tag=$2
if [ 'a'$3'a' == 'aa' ]
then
confFile=/home/hadoop/tools/deploy.conf
else
confFile=$3
fi
if [ -f $confFile ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
echo "*******************$server***************************"
ssh $server "source /etc/profile; $cmd"
done
else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
如何来创建上述文件。
在这里,后来,推荐使用软件Notepad++软件。
在deploy.conf里。
取个别名all,是所有节点。
可以看出,我们是将djt11和djt12作为namenode。
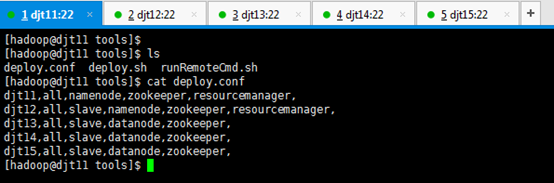
[hadoop@djt11 tools]$ cat deploy.conf
[hadoop@djt11 tools]$ cat deploy.sh
[hadoop@djt11 tools]$ cat runRemoteCmd.sh
以上三个文件,方便我们搭建hadoop分布式集群。具体如何使用看后面如何操作。
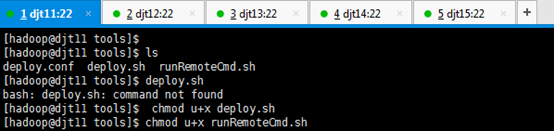
如果我们想直接使用脚本,还需要给脚本添加执行权限。
[hadoop@djt11 tools]$ ls
[hadoop@djt11 tools]$ deploy.sh
[hadoop@djt11 tools]$ chmod u+x deploy.sh
[hadoop@djt11 tools]$ chmod u+x runRemoteCmd.sh
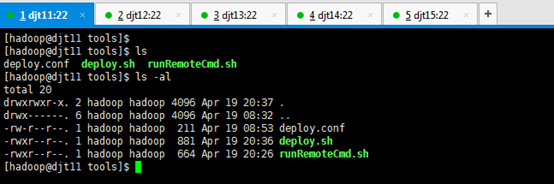
查看下
[hadoop@djt11 tools]$ ls -al
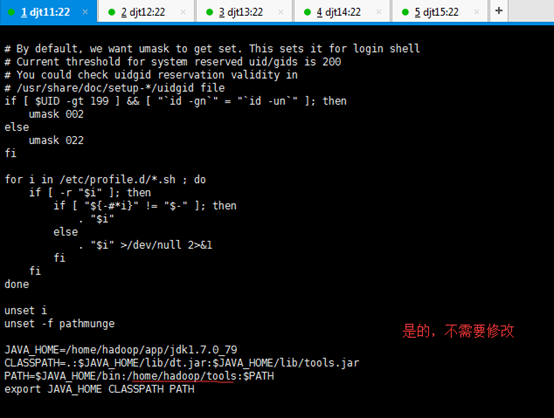
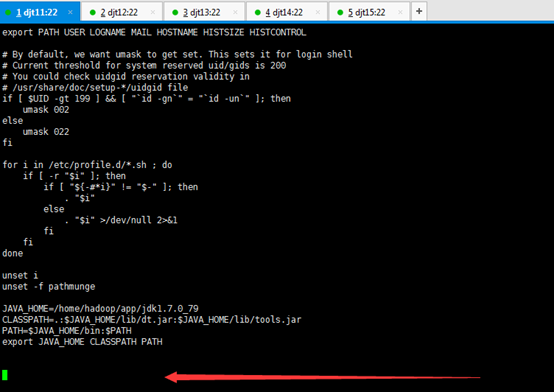
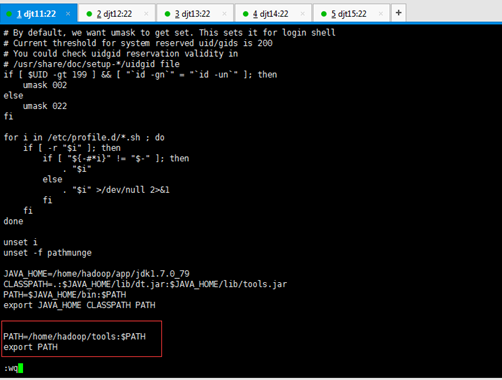
5、同时我们需要将/home/hadoop/tools目录配置到PATH路径中。
追加
PATH=/home/hadoop/tools:$PATH
export PATH
或者
PATH=$JAVA_HOME/bin:/home/hadoop/tools:$PATH
[iyunv@djt11 tools]# source /etc/profile
[iyunv@djt11 tools]# su hadoop
[hadoop@djt11 tools]$ ls
这些Tools,只需要在djt11里有就可以了。
即vi /etc/profile下的环境变量里自然就少了。
djt11
PATH=$JAVA_HOME/bin:/home/hadoop/tools:$PATH
djt11, djt12,djt13,djt14,djt15
PATH=$JAVA_HOME/bin: $PATH
测试下
[hadoop@djt11 tools]$ deploy.sh
[hadoop@djt11 tools]$ runRemoteCmd.sh
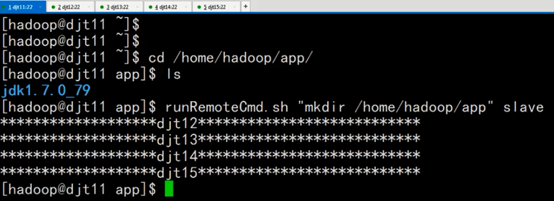
因为,我们之前每个节点都单独创建了,软件安装目录/home/hadoop/app。这是一个快速创建的方法,很值得学习。
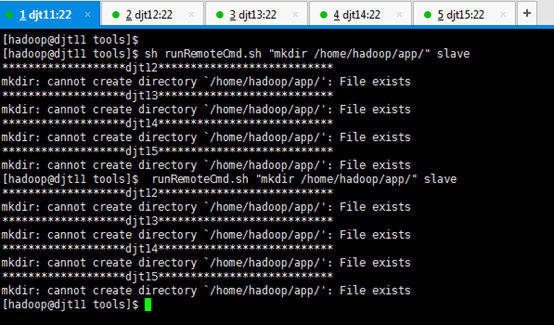
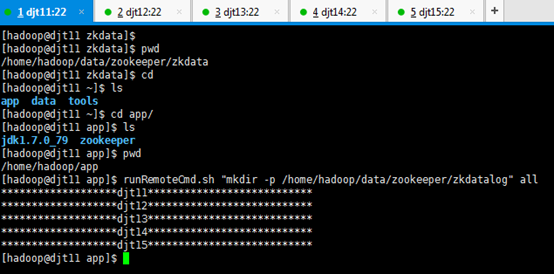
我们在djt11节点上,通过runRemoteCmd.sh脚本,一键创建所有节点的软件安装目录/home/hadoop/app。
[hadoop@djt11 tools]$ runRemoteCmd.sh "mkdir /home/hadoop/app" slave
或者
[hadoop@djt11 tools]$ sh runRemoteCmd.sh "mkdir /home/hadoop/app" slave
我们可以在所有节点查看到/home/hadoop/app目录已经创建成功。
因为,djt11已结创建了,所以,作为slave的djt12,djt13,djt14,djt15。
因为,djt11已结创建了,所以,作为slave的djt12,djt13,djt14,djt15。
如果,之前没有创建的话,则是如下:
[hadoop@djt11 app]$ scp -r jdk1.7.0_79/ hadoop@djt12:/home/hadoop/app/
因为,这样也是可以,在djt11里直接将jdk1.7.0_79复制过去到djt12,djt13,djt14,djt15。
当然咯,之前,我们早就已经分别都弄好了,这里,假设的是djt12,djt13,djt14,djt15没有弄好jdk。
但是,这样操作,缺点是速度比较慢。
如,djt11对djt13,djt11对djt14,djt11对djt15传jdk就不赘述了。
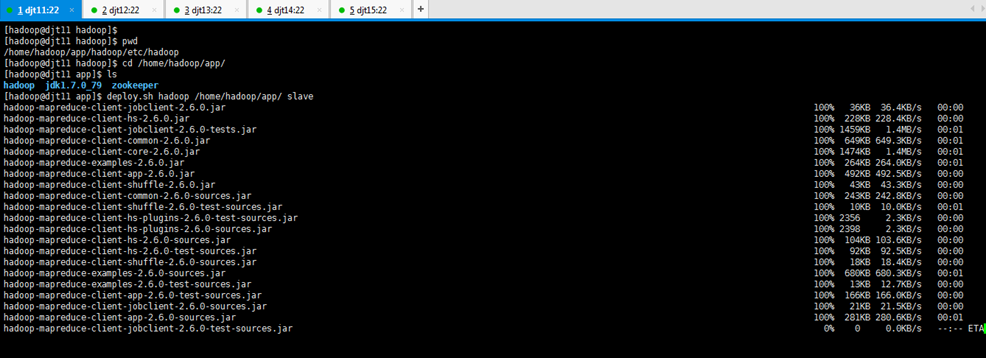
[hadoop@djt11 app]$ deploy.sh jdk1.7.0_79/ /home/hadoop/app/ slave
或者,
[hadoop@djt11 app]$ sh deploy.sh jdk1.7.0_79/ /home/hadoop/app/ slave
通常,是采用脚本,来进行分发。速度很快。
会有4个这样的分发状态界面。因为,是分别对djt12,djt13,djt14,djt15。
分发完毕
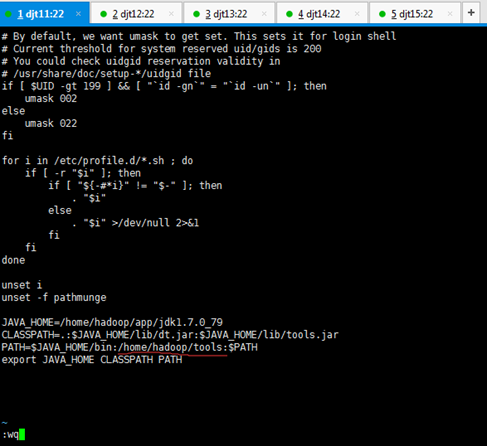
然后,对其,脚本工具的环境变量进行设置
对djt11
[hadoop@djt11 tools]$ ls
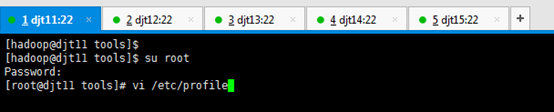
[hadoop@djt11 tools]$ su root
[hadoop@djt11 tools]$ vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:/home/hadoop/tools:$PATH
export JAVA_HOME CLASSPATH PATH
对djt12
[hadoop@djt12 ~]$ ls
[hadoop@djt12 ~]$ su root
[iyunv@djt12 hadoop]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
对djt13
[hadoop@djt13 ~]$ ls
[hadoop@djt13 ~]$ su root
[iyunv@djt13 hadoop]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
对djt14
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
对djt15
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
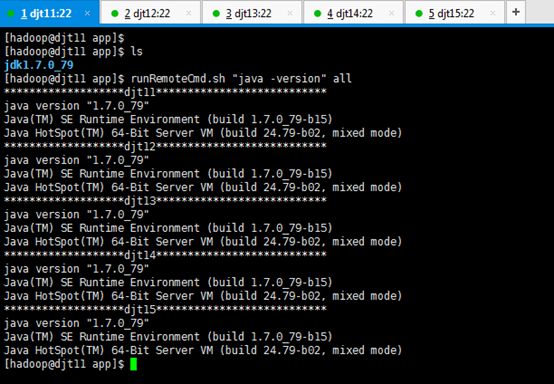
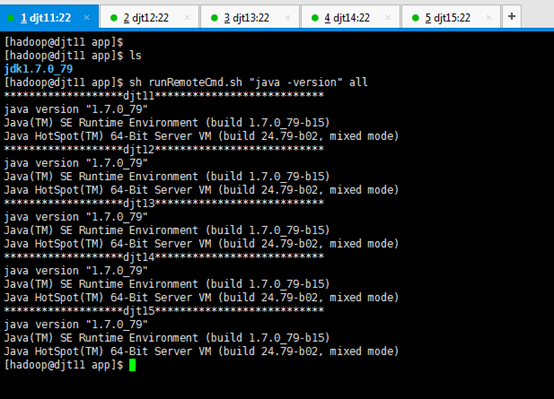
这里,统一查看对djt11,djt12,djt13,djt14,djt15的jdk版本信息。
[hadoop@djt11 app]$ runRemoteCmd.sh "java -version" all
或者
[hadoop@djt11 app]$ sh runRemoteCmd.sh "java -version" all
9 、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的Zookeeper安装)
Zookeeper安装
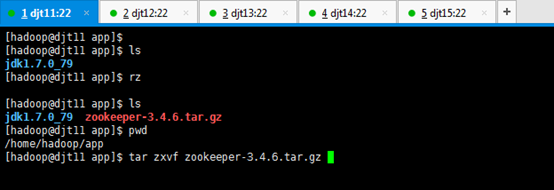
1、将本地下载好的zookeeper-3.4.6.tar.gz安装包,上传至djt11节点下的/home/hadoop/app目录下。
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ rz
[hadoop@djt11 app]$ tar zxvf zookeeper-3.4.6.tar.gz
[hadoop@djt11 app]$ ls
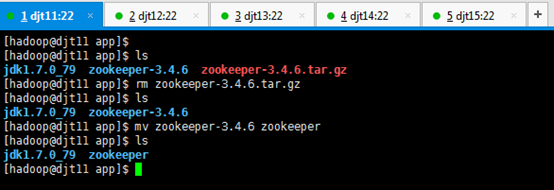
[hadoop@djt11 app]$ rm zookeeper-3.4.6.tar.gz
[hadoop@djt11 app]$ mv zookeeper-3.4.6 zookeeper
[hadoop@djt11 app]$ ls
2、修改Zookeeper中的配置文件。
[hadoop@djt11 app]$ ls
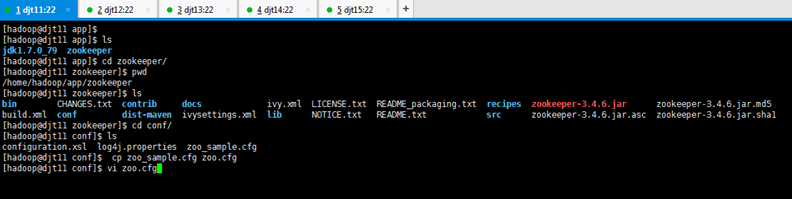
[hadoop@djt11 app]$ cd zookeeper/
[hadoop@djt11 zookeeper]$ pwd
[hadoop@djt11 zookeeper]$ ls
[hadoop@djt11 zookeeper]$ cd conf/
[hadoop@djt11 conf]$ ls
[hadoop@djt11 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@djt11 conf]$ vi zoo.cfg
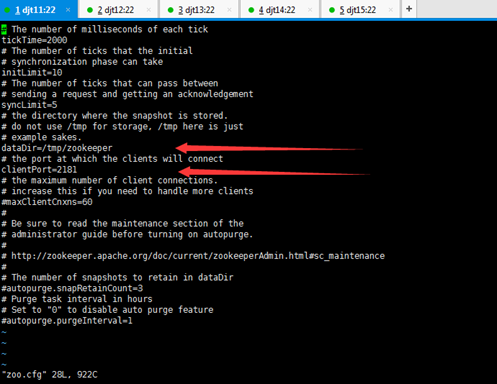
这是,zoo_sample.cfg的范例。我们要修改成我们自己集群信息的。
# example sakes.
dataDir=/home/hadoop/data/zookeeper/zkdata
dataLogDir=/home/hadoop/data/zookeeper/zkdatalog
# the port at which the clients will connect
clientPort=2181
#server.
server.1=djt11:2888:3888
server.2=djt12:2888:3888
server.3=djt13:2888:3888
server.4=djt14:2888:3888
server.5=djt15:2888:3888
解读:
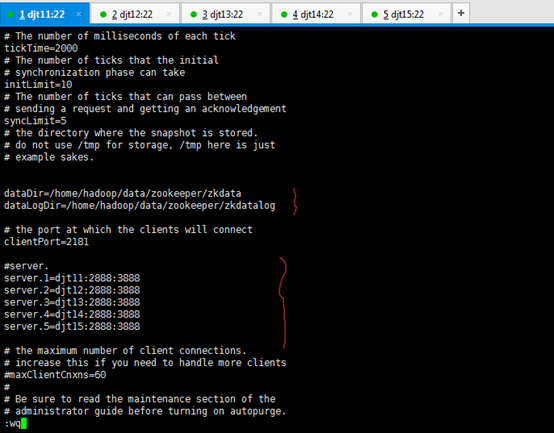
dataDir=/home/hadoop/data/zookeeper/zkdata //数据文件目录
dataLogDir=/home/hadoop/data/zookeeper/zkdatalog //日志目录
# the port at which the clients will connect
clientPort=2181 //默认端口号
#server.服务编号=主机名称:Zookeeper不同节点之间同步和通信的端口:选举端口(选举leader)
server.1=djt11:2888:3888
server.2=djt12:2888:3888
server.3=djt13:2888:3888
server.4=djt14:2888:3888
server.5=djt15:2888:3888
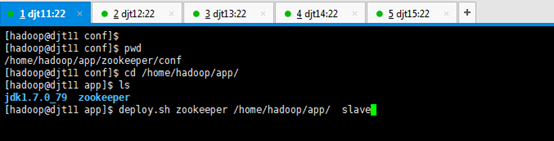
3、通过远程命令deploy.sh将Zookeeper安装目录拷贝到其他节点上面。
[hadoop@djt11 app]$ deploy.sh zookeeper /home/hadoop/app/ slave
slave是djt12、djt13、djt14、djt15
[hadoop@djt11 conf]$ pwd
[hadoop@djt11 conf]$ cd /home/hadoop/app/
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ deploy.sh zookeeper /home/hadoop/app/ slave
djt11对djt12、djt13、djt14、djt15的zookeeper安装目录发放完毕。
查看,被接收djt11发放zookeeper的djt12
查看,被接收djt11发放zookeeper的djt13
查看,被接收djt11发放zookeeper的djt14
查看,被接收djt11发放zookeeper的djt15
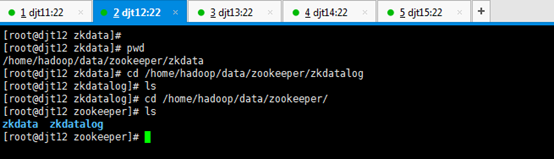
4、通过远程命令runRemoteCmd.sh在所有的节点上面创建目录:
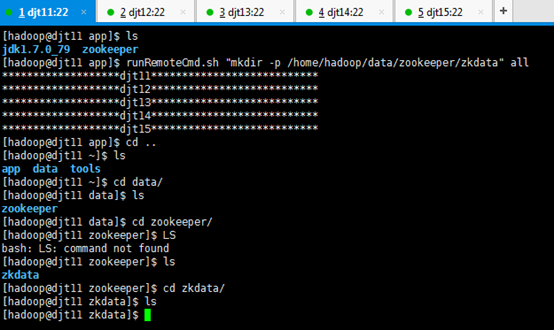
[hadoop@djt11 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdata" all
//创建数据目录
[hadoop@djt11 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdata" all
[hadoop@djt11 app]$ cd ..
[hadoop@djt11 ~]$ ls
[hadoop@djt11 ~]$ cd data/
[hadoop@djt11 data]$ ls
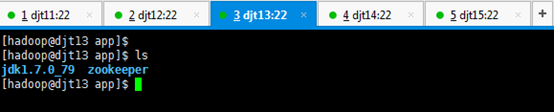
[hadoop@djt11 data]$ cd zookeeper/
[hadoop@djt11 zookeeper]$ ls
[hadoop@djt11 zookeeper]$ cd zkdata/
[hadoop@djt11 zkdata]$ ls
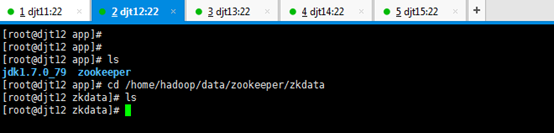
[iyunv@djt12 app]# ls
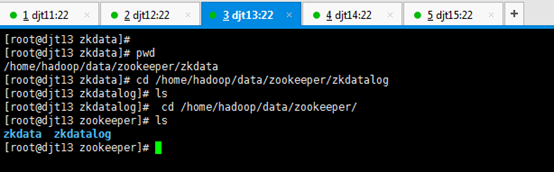
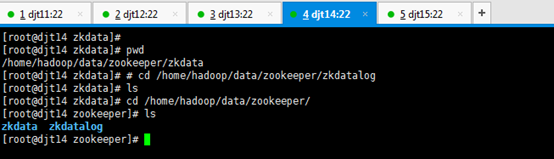
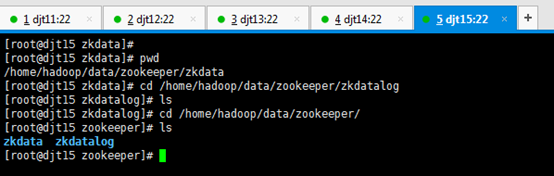
[iyunv@djt12 app]# cd /home/hadoop/data/zookeeper/zkdata
[iyunv@djt13 app]# ls
[iyunv@djt13 app]# cd /home/hadoop/data/zookeeper/zkdata
[iyunv@djt14 app]# ls
[iyunv@djt14 app]# cd /home/hadoop/data/zookeeper/zkdata
[iyunv@djt15 app]# ls
[iyunv@djt15 app]# cd /home/hadoop/data/zookeeper/zkdata
[hadoop@djt11 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdatalog" all
//创建日志目录
[hadoop@djt11 zkdata]$ pwd
[hadoop@djt11 zkdata]$ cd
[hadoop@djt11 ~]$ ls
[hadoop@djt11 ~]$ cd app/
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ pwd
[hadoop@djt11 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdatalog" all
[iyunv@djt12 zkdata]# pwd
[iyunv@djt12 zkdata]# cd /home/hadoop/data/zookeeper/zkdatalog
[iyunv@djt12 zkdatalog]# ls
[iyunv@djt12 zkdatalog]# cd /home/hadoop/data/zookeeper/
[iyunv@djt12 zookeeper]# ls
[iyunv@djt13 zkdata]# pwd
[iyunv@djt13 zkdata]# cd /home/hadoop/data/zookeeper/zkdatalog
[iyunv@djt13 zkdatalog]# ls
[iyunv@djt13 zkdatalog]# cd /home/hadoop/data/zookeeper/
[iyunv@djt13 zookeeper]# ls
[iyunv@djt14 zkdata]# pwd
[iyunv@djt14 zkdata]# cd /home/hadoop/data/zookeeper/zkdatalog
[iyunv@djt14 zkdatalog]# ls
[iyunv@djt14 zkdatalog]# cd /home/hadoop/data/zookeeper/
[iyunv@djt14 zookeeper]# ls
[iyunv@djt15 zkdata]# pwd
[iyunv@djt15 zkdata]# cd /home/hadoop/data/zookeeper/zkdatalog
[iyunv@djt15 zkdatalog]# ls
[iyunv@djt15 zkdatalog]# cd /home/hadoop/data/zookeeper/
[iyunv@djt15 zookeeper]# ls
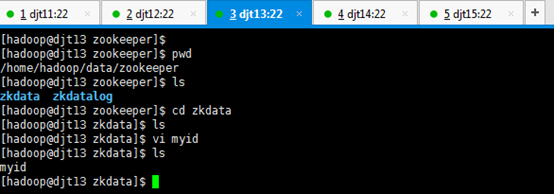
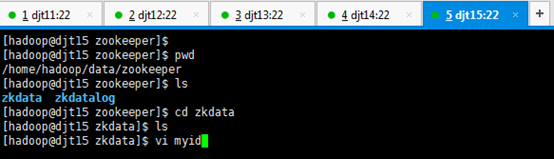
5、然后分别在djt11、djt12、djt13、djt14、djt15上面,进入zkdata目录下,创建文件myid,里面的内容分别填充为:1、2、3、4、5, 这里我们以djt11为例。
[hadoop@djt11 app]$ pwd
[hadoop@djt11 app]$ cd
[hadoop@djt11 ~]$ ls
[hadoop@djt11 ~]$ cd data/
[hadoop@djt11 data]$ ls
[hadoop@djt11 data]$ cd zookeeper/
[hadoop@djt11 zookeeper]$ ls
[hadoop@djt11 zookeeper]$ cd zkdata
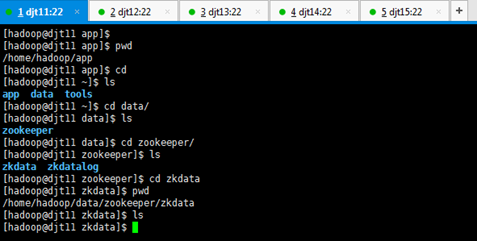
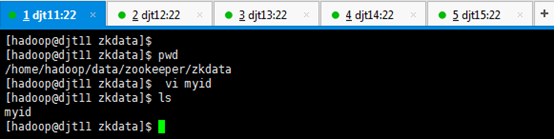
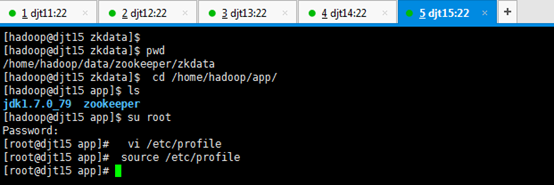
[hadoop@djt11 zkdata]$ pwd
[hadoop@djt11 zkdata]$ pwd
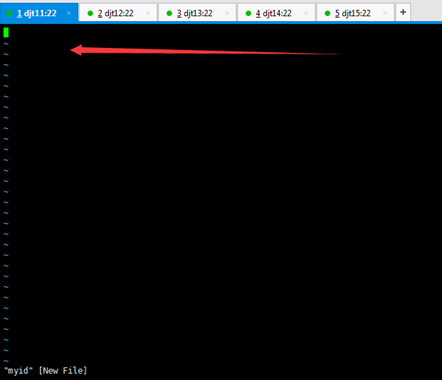
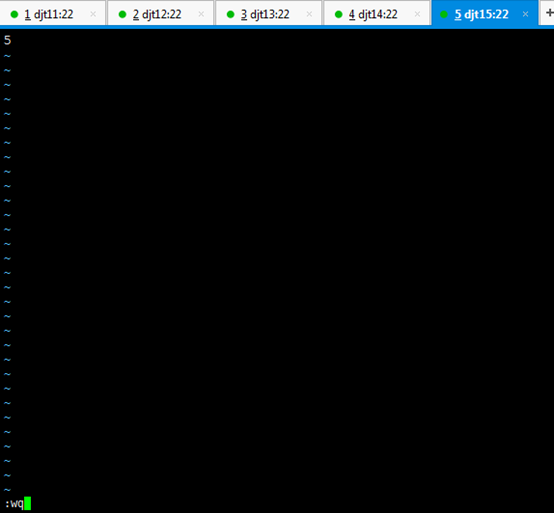
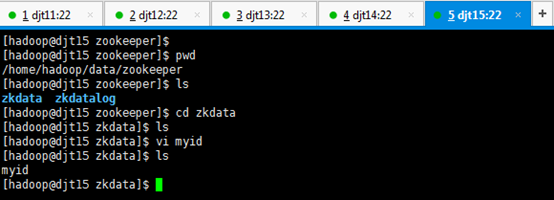
[hadoop@djt11 zkdata]$ vi myid
1 //输入数字1
对应,
djt11对应的zookeeper1编号
或者 echo "1" > myid
[hadoop@djt12 zookeeper]$ pwd
[hadoop@djt12 zookeeper]$ ls
[hadoop@djt12 zookeeper]$ cd zkdata
[hadoop@djt12 zkdata]$ ls
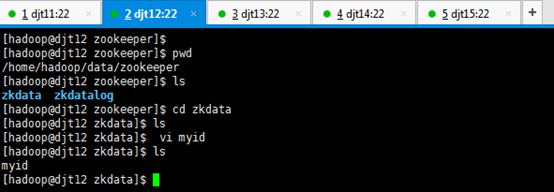
[hadoop@djt12 zkdata]$ vi myid
2 //输入数字2
对应,
djt12对应的zookeeper2编号
或者 echo "2" > myid
[hadoop@djt13 zookeeper]$ pwd
[hadoop@djt13 zookeeper]$ ls
[hadoop@djt13 zookeeper]$ cd zkdata
[hadoop@djt13 zkdata]$ ls
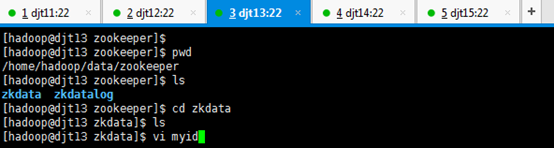
[hadoop@djt13 zkdata]$ vi myid
3 //输入数字3
对应,
djt13对应的zookeeper3编号
或者 echo "3" > myid
[hadoop@djt13 zookeeper]$ pwd
[hadoop@djt13 zookeeper]$ ls
[hadoop@djt13 zookeeper]$ cd zkdata
[hadoop@djt13 zkdata]$ ls
[hadoop@djt13 zkdata]$ vi myid
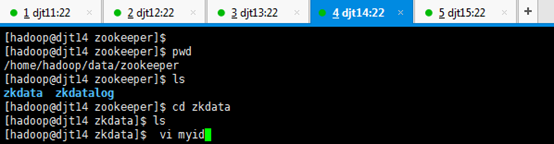
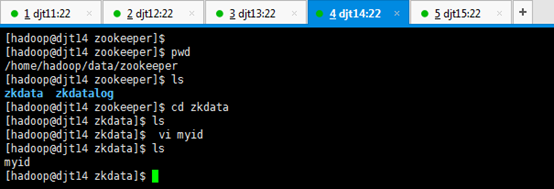
[hadoop@djt14 zookeeper]$ pwd
[hadoop@djt14 zookeeper]$ ls
[hadoop@djt14 zookeeper]$ cd zkdata
[hadoop@djt14 zkdata]$ ls
[hadoop@djt14 zkdata]$ vi myid
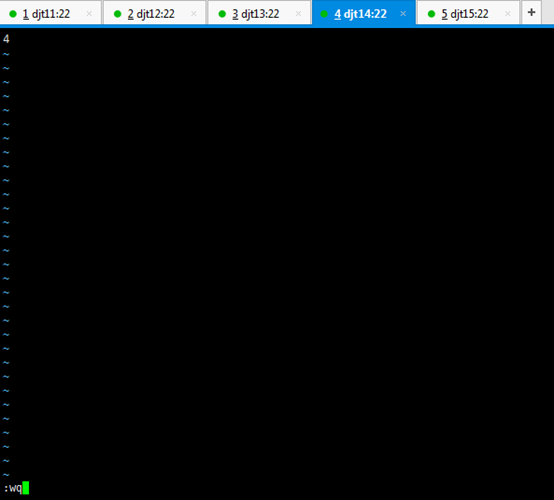
4 //输入数字4
对应,
djt14对应的zookeeper4编号
或者 echo "4" > myid
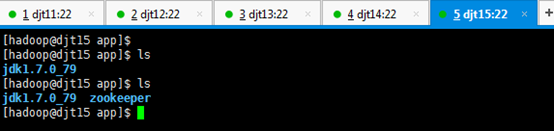
[hadoop@djt15 zookeeper]$ pwd
[hadoop@djt15 zookeeper]$ ls
[hadoop@djt15 zookeeper]$ cd zkdata
[hadoop@djt15 zkdata]$ ls
[hadoop@djt15 zkdata]$ vi myid
5 //输入数字5
对应,
djt15对应的zookeeper5编号
或者 echo "1" > myid
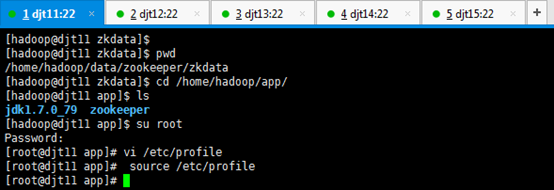
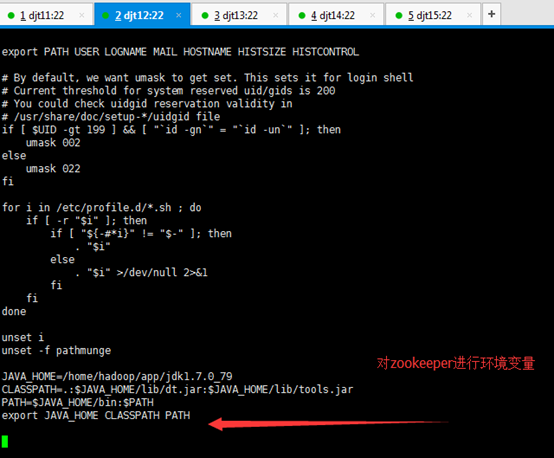
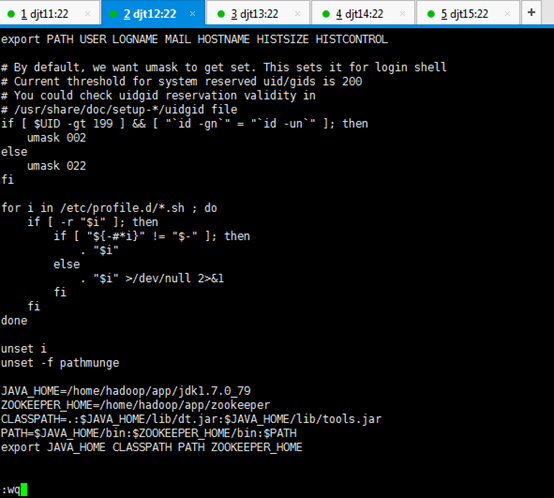
6、配置Zookeeper环境变量。
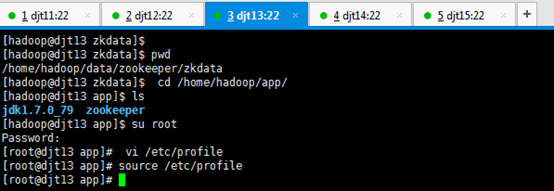
[hadoop@djt11 zkdata]$ pwd
[hadoop@djt11 zkdata]$ cd /home/hadoop/app/
[hadoop@djt11 app]$ ls
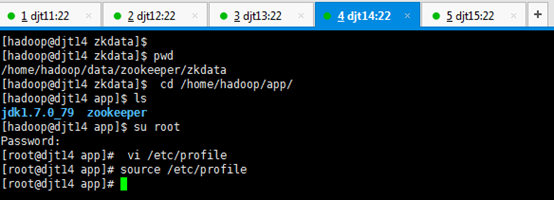
[hadoop@djt11 app]$ su root
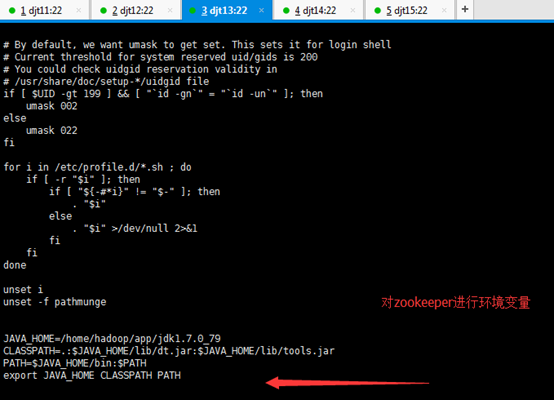
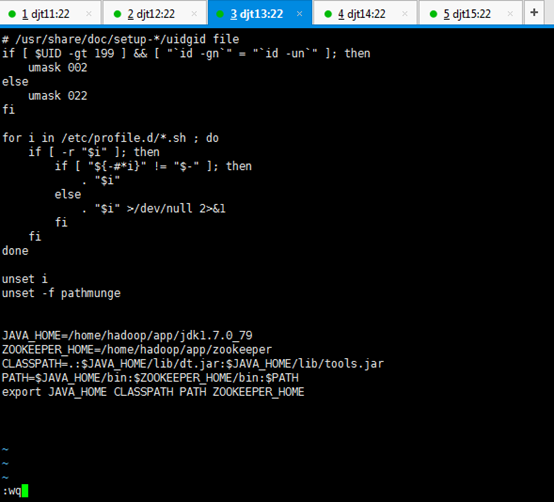
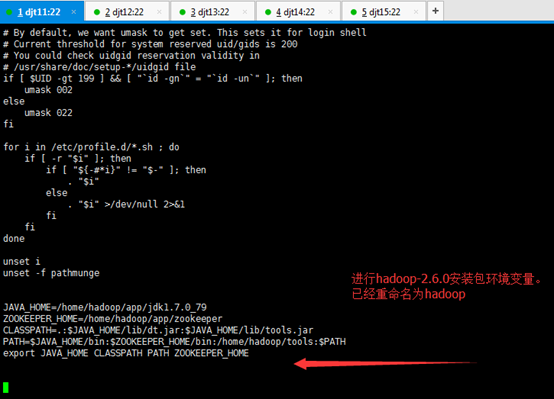
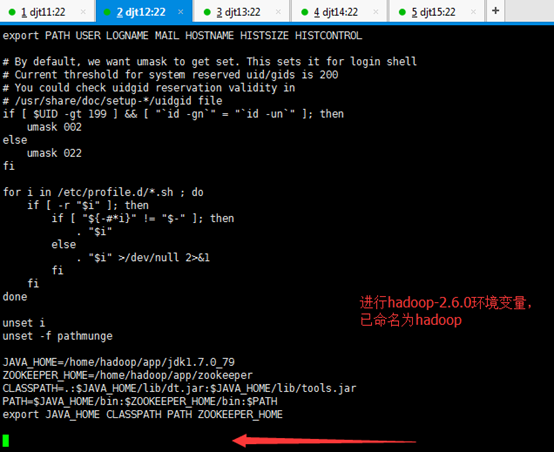
[iyunv@djt11 app]# vi /etc/profile
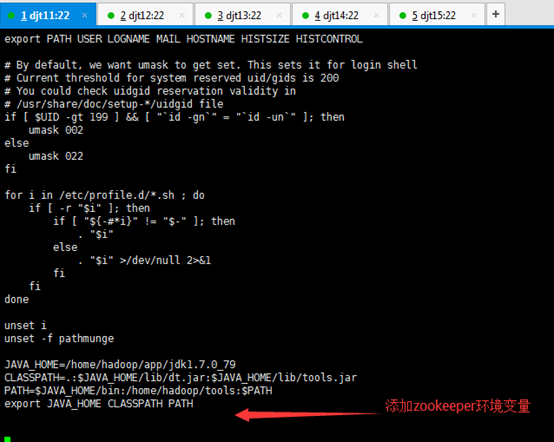
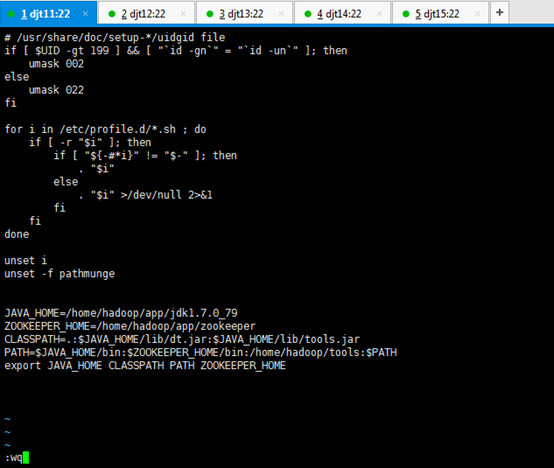
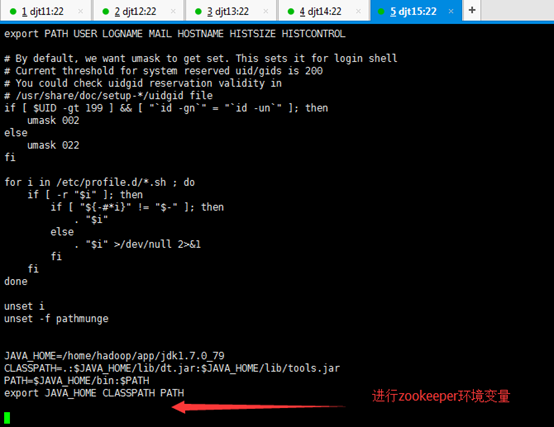
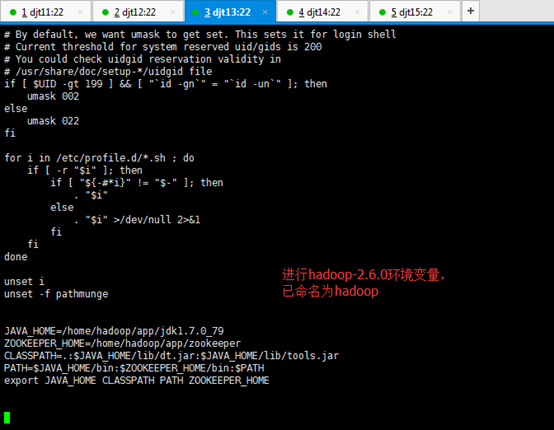
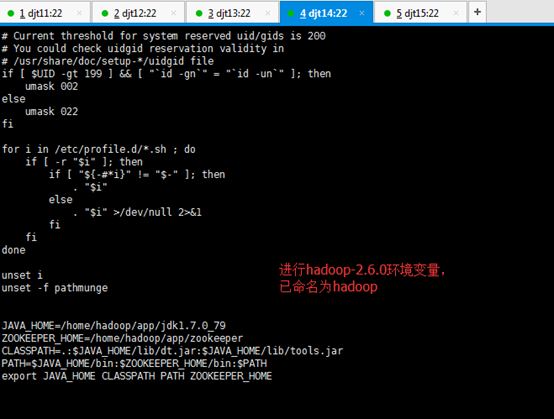
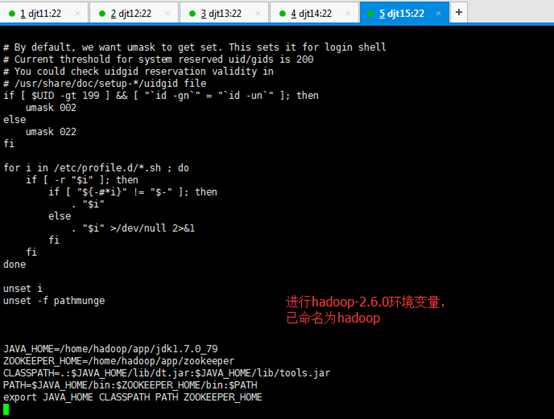
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:/home/hadoop/tools:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME
[iyunv@djt11 app]# source /etc/profile
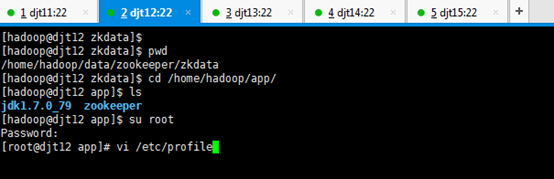
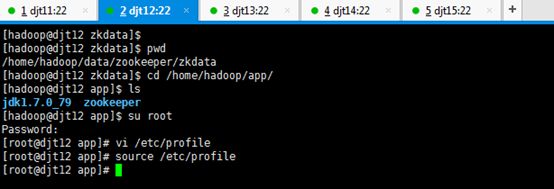
[hadoop@djt12 zkdata]$ pwd
[hadoop@djt12 zkdata]$ cd /home/hadoop/app/
[hadoop@djt12 app]$ ls
[hadoop@djt12 app]$ su root
[iyunv@djt12 app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME
[iyunv@djt12 app]# source /etc/profile
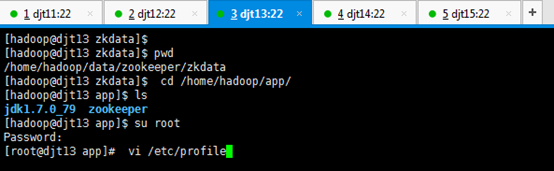
[hadoop@djt13 zkdata]$ pwd
[hadoop@djt13 zkdata]$ cd /home/hadoop/app/
[hadoop@djt13 app]$ ls
[hadoop@djt13 app]$ su root
[iyunv@djt13 app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME
[iyunv@djt13 app]# source /etc/profile
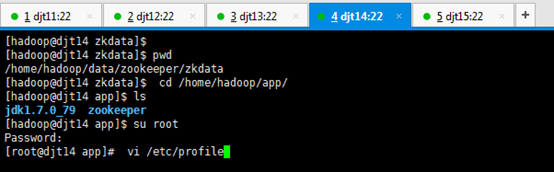
[hadoop@djt14 zkdata]$ pwd
[hadoop@djt14 zkdata]$ cd /home/hadoop/app/
[hadoop@djt14 app]$ ls
[hadoop@djt14 app]$ su root
[iyunv@djt14 app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME
[iyunv@djt14 app]# source /etc/profile
[hadoop@djt15 zkdata]$ pwd
[hadoop@djt15 zkdata]$ cd /home/hadoop/app/
[hadoop@djt15 app]$ ls
[hadoop@djt15 app]$ su root
[iyunv@djt15 app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME
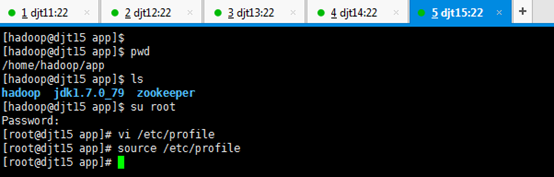
[iyunv@djt15 app]# source /etc/profile
7、在djt11节点上面启动Zookeeper。
在djt11节点上面启动与Zookeeper
[hadoop @djt11 app]# pwd
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ cd zookeeper/
[hadoop@djt11 zookeeper]$ pwd
[hadoop@djt11 zookeeper]$ ls
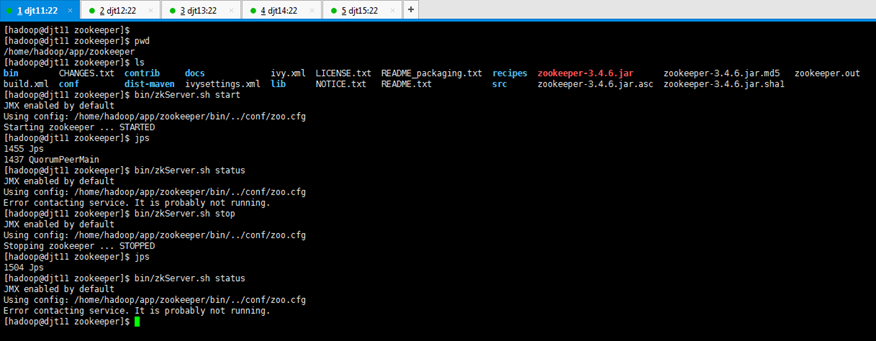
[hadoop@djt11 zookeeper]$ bin/zkServer.sh start
//启动Zookeeper
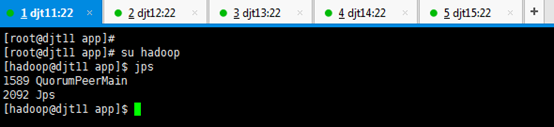
[hadoop@djt11 zookeeper]$ jps
[hadoop@djt11 zookeeper]$ bin/zkServer.sh status
//查看Zookeeper运行状态
[hadoop@djt11 zookeeper]$ bin/zkServer.sh stop
//启动Zookeeper
[hadoop@djt11 zookeeper]$ jps
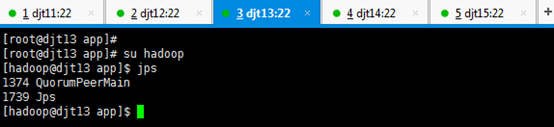
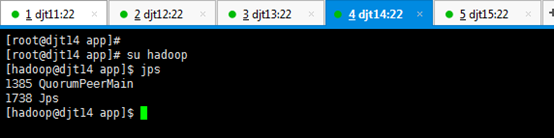
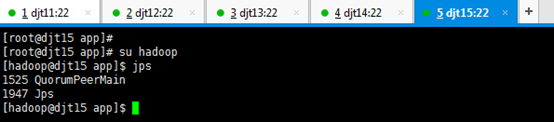
由此可知,QuorumPeerMain是zookeeper的进程。
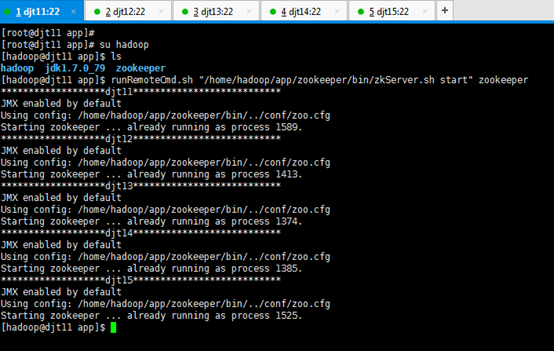
8、使用runRemoteCmd.sh 脚本,启动所有节点上面的Zookeeper。
启动所有节点djt11,djt12,djt13,djt14,djt15上的zookeepr
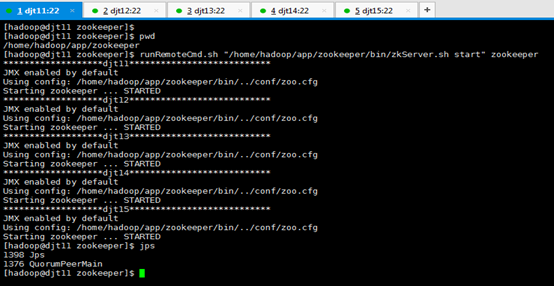
[hadoop@djt11 zookeeper]$ pwd
[hadoop@djt11 zookeeper]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
[iyunv@djt12 app]# ls
[iyunv@djt12 app]# su hadoop
[hadoop@djt12 app]$ cd
[hadoop@djt12 ~]$ ls
[hadoop@djt12 ~]$ cd data/
[hadoop@djt12 data]$ ls
[hadoop@djt12 data]$ cd zookeeper/
[hadoop@djt12 zookeeper]$ ls
[hadoop@djt12 zookeeper]$ cd zkdata
[hadoop@djt12 zkdata]$ ls
[hadoop@djt12 zkdata]$ jps
由此可知,QuorumPeerMain是zookeeper的进程。
[iyunv@djt13 app]# ls
[iyunv@djt13 app]# su hadoop
[hadoop@djt13 app]$ cd
[hadoop@djt13 ~]$ ls
[hadoop@djt13 ~]$ cd data/
[hadoop@djt13 data]$ ls
[hadoop@djt13 data]$ cd zookeeper/
[hadoop@djt13 zookeeper]$ ls
[hadoop@djt13 zookeeper]$ cd zkdata
[hadoop@djt13 zkdata]$ ls
[hadoop@djt13 zkdata]$ jps
由此可知,QuorumPeerMain是zookeeper的进程。
[iyunv@djt14 app]# ls
[iyunv@djt14 app]# su hadoop
[hadoop@djt14 app]$ cd
[hadoop@djt14 ~]$ ls
[hadoop@djt14 ~]$ cd data/
[hadoop@djt14 data]$ ls
[hadoop@djt14 data]$ cd zookeeper/
[hadoop@djt14 zookeeper]$ ls
[hadoop@djt14 zookeeper]$ cd zkdata
[hadoop@djt14 zkdata]$ ls
[hadoop@djt14 zkdata]$ jps
由此可知,QuorumPeerMain是zookeeper的进程。
[iyunv@djt15 app]# ls
[iyunv@djt15 app]# su hadoop
[hadoop@djt15 app]$ cd
[hadoop@djt15 ~]$ ls
[hadoop@djt15 ~]$ cd data/
[hadoop@djt15 data]$ ls
[hadoop@djt15 data]$ cd zookeeper/
[hadoop@djt15 zookeeper]$ ls
[hadoop@djt15 zookeeper]$ cd zkdata
[hadoop@djt15 zkdata]$ ls
[hadoop@djt15 zkdata]$ jps
由此可知,QuorumPeerMain是zookeeper的进程。
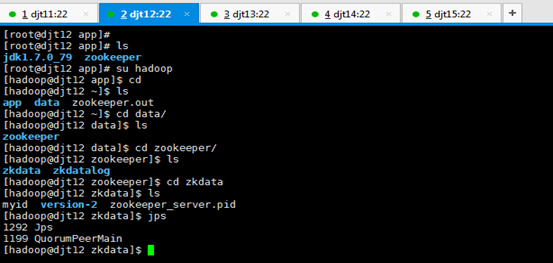
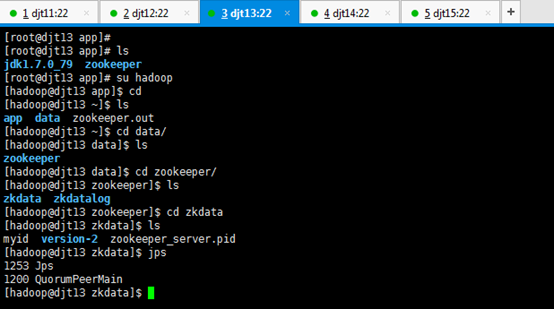
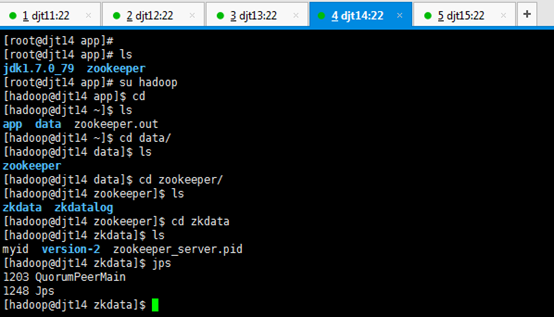
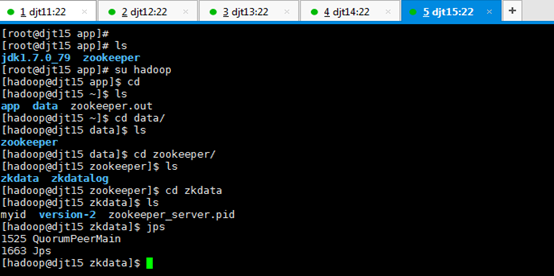
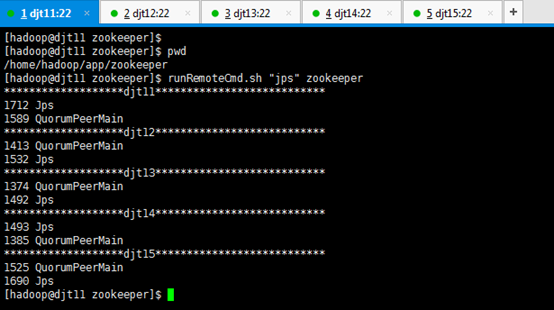
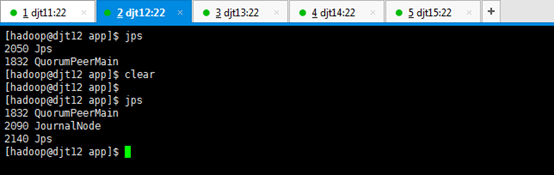
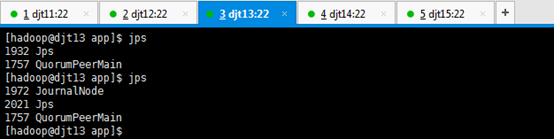
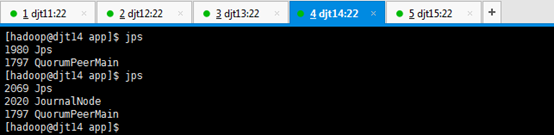
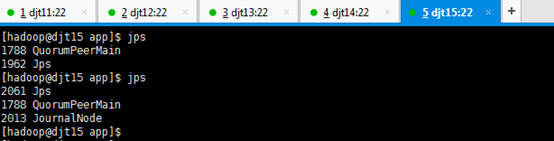
9、查看所有节点上面的QuorumPeerMain进程是否启动。
查看所有节点上面的QuorumPeerMain进程是否启动,即是各节点上的zookeeper进程。
[hadoop@djt11 zookeeper]$ pwd
[hadoop@djt11 zookeeper]$ runRemoteCmd.sh "jps" zookeeper
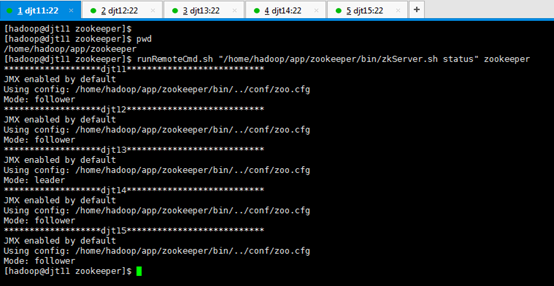
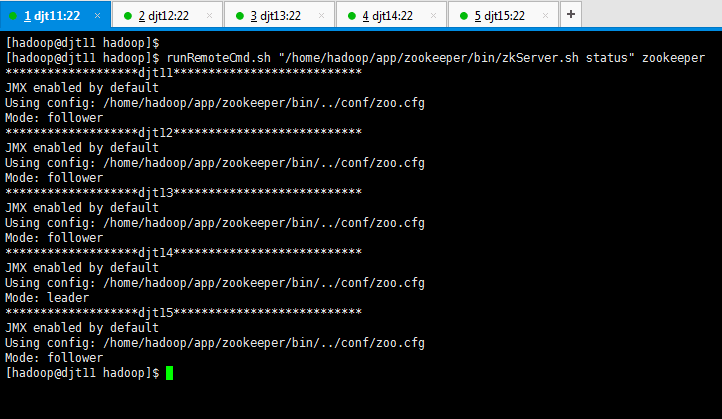
10、查看所有Zookeeper节点状态。
[hadoop@djt11 zookeeper]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh status" zookeeper
10 、搭建一个5节点的hadoop分布式小集群--预备工作(对djt11、djt12、djt13、djt14、djt15 集群安装前的hadoop集群环境搭建)继续
hadoop集群环境搭建
1 HDFS安装配置
1、将下载好的apache hadoop-2.6.0.tar.gz安装包,上传至djt11节点下的/home/hadoop/app目录下。
[hadoop@djt11 zookeeper]$ pwd
[hadoop@djt11 zookeeper]$ cd ..
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ pwd
[hadoop@djt11 app]$ tar zxvf hadoop-2.6.0.tar.gz
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ rm hadoop-2.6.0.tar.gz
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ mv hadoop-2.6.0 hadoop
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$
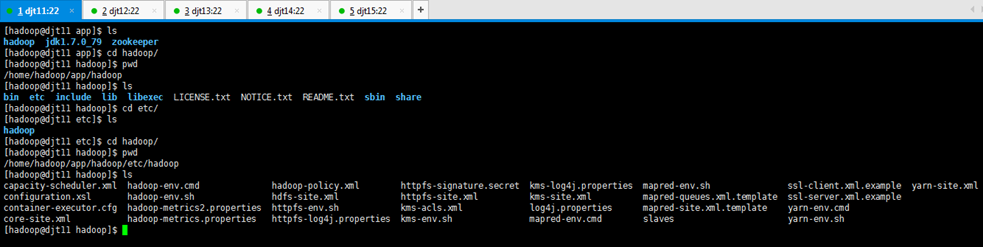
2、切换到/home/hadoop/app/hadoop/etc/hadoop/目录下,修改配置文件。
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ cd hadoop/
[hadoop@djt11 hadoop]$ pwd
[hadoop@djt11 hadoop]$ ls
[hadoop@djt11 hadoop]$ cd etc/
[hadoop@djt11 etc]$ cd hadoop/
或者
[hadoop@djt11 app]$ cd /home/hadoop/app/hadoop/etc/hadoop/
配置HDFS
1、配置hadoop-env.sh

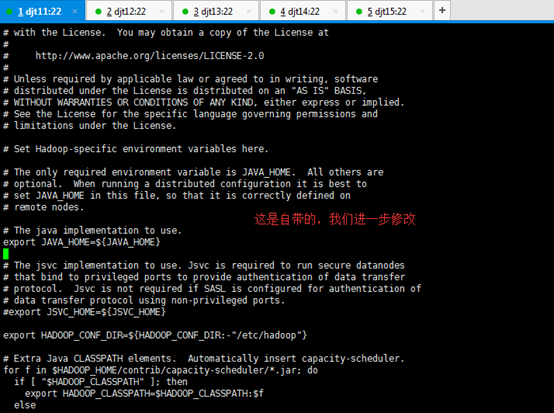
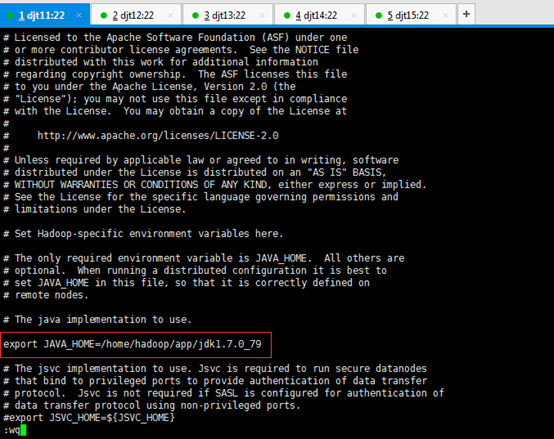
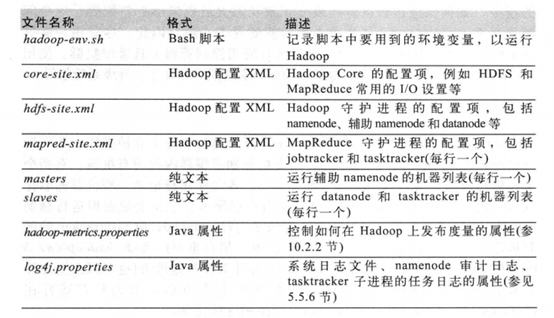
[hadoop@djt11 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
或者,自己直接先创建,学会自己动手,结合自带的脚本进行修改,来提升动手能力。这个很重要!
然后,通过rz来上传。
2、配置core-site.xml

解读
[hadoop@djt11 hadoop]$ vi core-site.xml
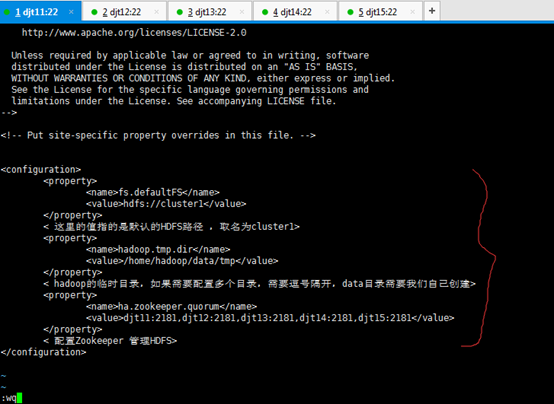
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
< 这里的值指的是默认的HDFS路径 ,取名为cluster1>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/tmp</value>
</property>
< hadoop的临时目录,如果需要配置多个目录,需要逗号隔开,data目录需要我们自己创建>
<property>
<name>ha.zookeeper.quorum</name>
<value>djt11:2181,djt12:2181,djt13:2181,djt14:2181,djt15:2181</value>
</property>
< 配置Zookeeper 管理HDFS>
</configuration>
请用下面这个
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name> <value>djt11:2181,djt12:2181,djt13:2181,djt14:2181,djt15:2181</value>
</property>
</configuration>
需要注意,不要带文字
2181是zookeeper是其默认端口。
或者,自己直接先创建,学会自己动手,结合自带的脚本进行修改,来提升动手能力。这个很重要!
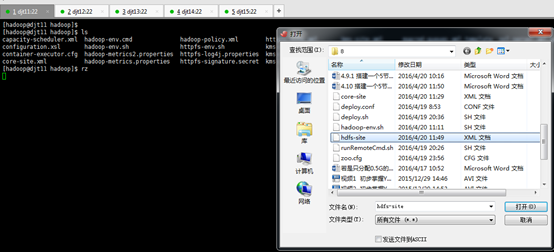
然后,通过rz来上传。
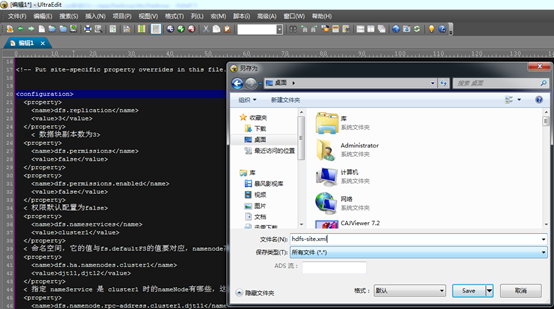
3、配置hdfs-site.xml

解读
[hadoop@djt11 hadoop]$ vi hdfs-site.xml
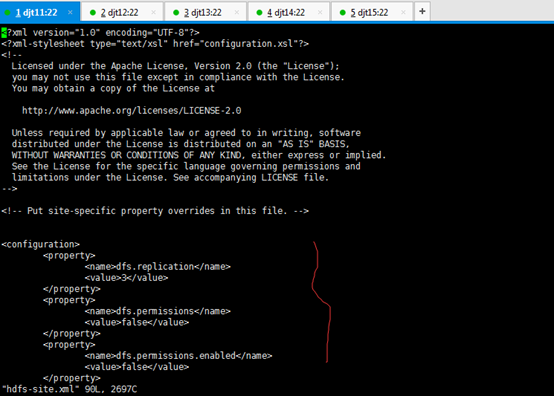
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
< 数据块副本数为3>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
< 权限默认配置为false>
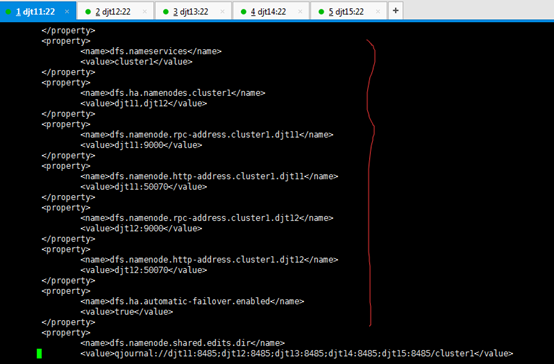
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
< 命名空间,它的值与fs.defaultFS的值要对应,namenode高可用之后有两个namenode,cluster1是对外提供的统一入口>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>djt11,djt12</value>
</property>
< 指定 nameService 是 cluster1 时的nameNode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可>
<property>
<name>dfs.namenode.rpc-address.cluster1.djt11</name>
<value>djt11:9000</value>
</property>
< djt11 rpc地址>
<property>
<name>dfs.namenode.http-address.cluster1.djt11</name>
<value>djt11:50070</value>
</property>
< djt11 http地址>
<property>
<name>dfs.namenode.rpc-address.cluster1.djt12</name>
<value>djt12:9000</value>
</property>
< djt12 rpc地址>
<property>
<name>dfs.namenode.http-address.cluster1.djt12</name>
<value>djt12:50070</value>
</property>
< djt12 http地址>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
< 启动故障自动恢复>
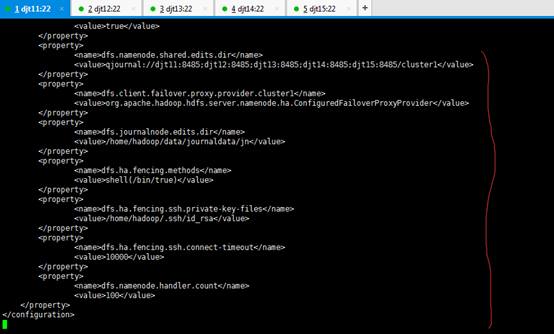
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://djt11:8485;djt12:8485;djt13:8485;djt14:8485;djt15:8485/cluster1</value>
</property>
< 指定journal>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
< 指定 cluster1 出故障时,哪个实现类负责执行故障切换>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journaldata/jn</value>
</property>
< 指定JournalNode集群在对nameNode的目录进行共享时,自己存储数据的磁盘路径 >
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
< 脑裂默认配置>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>
请用下面的这个,
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>djt11,djt12</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.djt11</name>
<value>djt11:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.djt11</name>
<value>djt11:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.djt12</name>
<value>djt12:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.djt12</name>
<value>djt12:50070</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://djt11:8485;djt12:8485;djt13:8485;djt14:8485;djt15:8485/cluster1</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journaldata/jn</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>
或者,自己直接先创建,学会自己动手,结合自带的脚本进行修改,来提升动手能力。这个很重要!
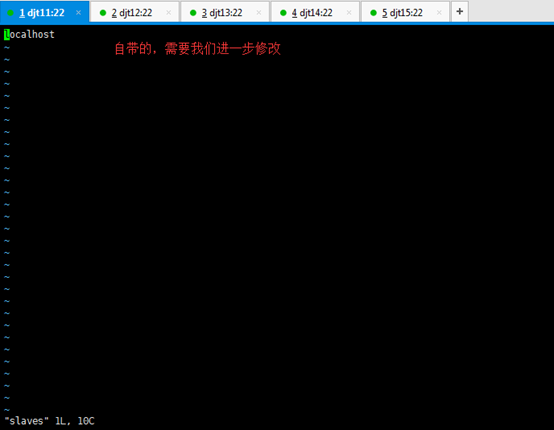
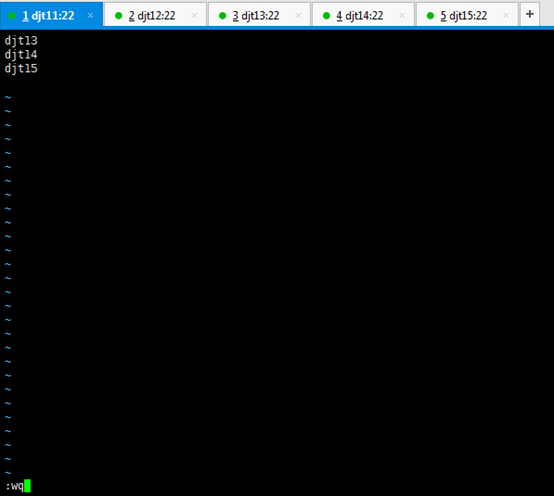
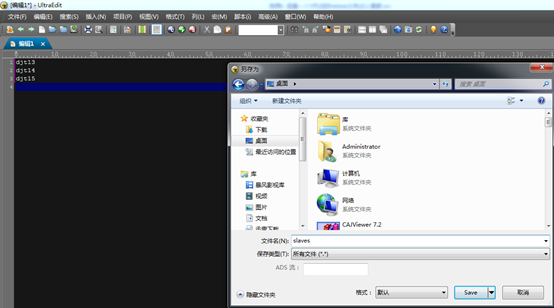
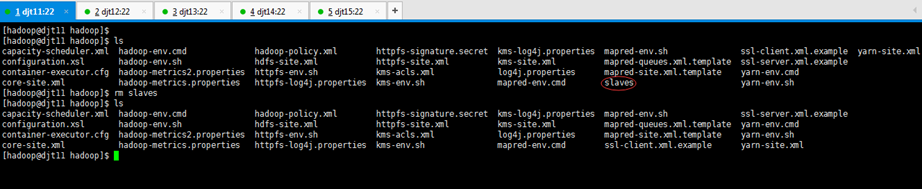
4、配置 slave
[hadoop@djt11 hadoop]$ vi slaves

djt13
djt14
djt15
djt11和djt12作为namenode。
djt13,djt14,djt15作为datanode。
或者,自己直接先创建,学会自己动手,结合自带的脚本进行修改,来提升动手能力。这个很重要!
5、向所有节点分发hadoop安装包。
会做4个同样的状态界面,需要一段时间,请耐心等待…
[hadoop@djt11 app]$ deploy.sh hadoop /home/hadoop/app/ slave
[hadoop@djt11 hadoop]$ pwd
[hadoop@djt11 hadoop]$ cd /home/hadoop/app/
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ deploy.sh hadoop /home/hadoop/app/ slave
发放完毕
[hadoop@djt12 zkdata]$jps
[hadoop@djt12 app]$ cd /home/hadoop/app/
[hadoop@djt12 app]$ ls
[hadoop@djt13 zkdata]$jps
[hadoop@djt13 app]$ cd /home/hadoop/app/
[hadoop@djt13 app]$ ls
[hadoop@djt14 zkdata]$jps
[hadoop@djt14 app]$ cd /home/hadoop/app/
[hadoop@djt14 app]$ ls
[hadoop@djt15 zkdata]$jps
[hadoop@djt15 app]$ cd /home/hadoop/app/
[hadoop@djt15 app]$ ls
5、设置hadoop安装包的环境变量。
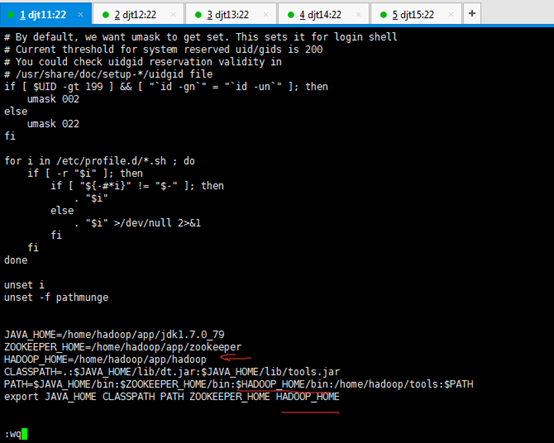
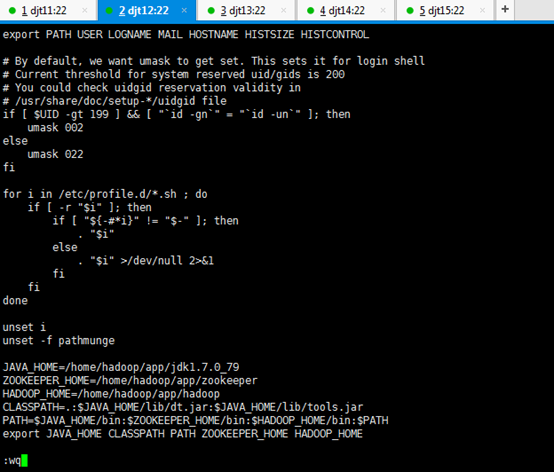
[iyunv@djt11 app]$ vi /etc/profile
[hadoop@djt11 app]$ su root
[iyunv@djt11 app]# vi /etc/profile
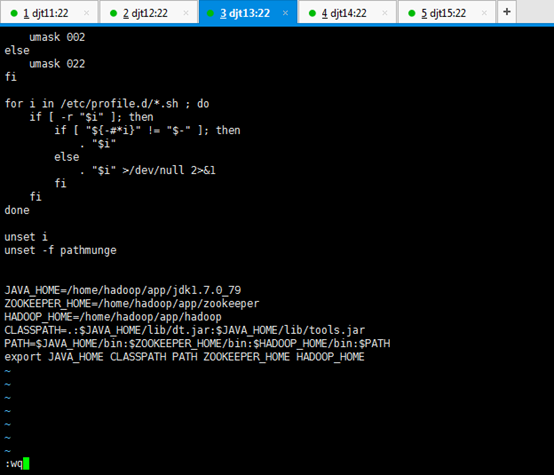
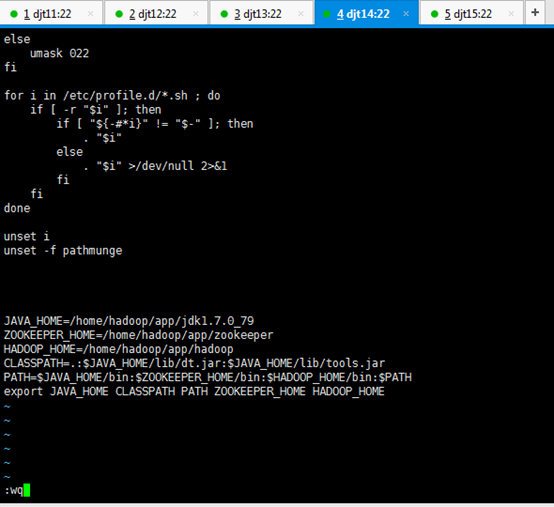
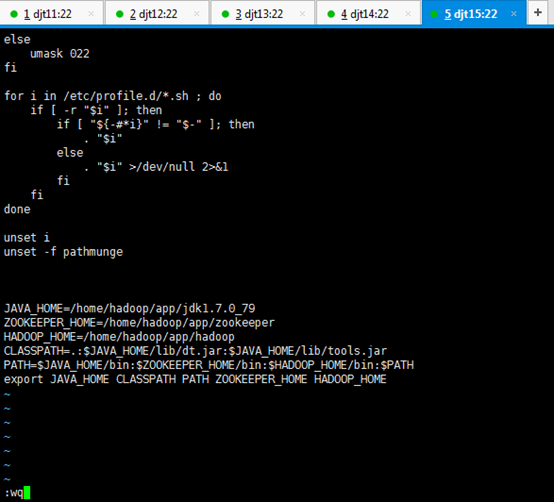
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
HADOOP_HOME=/home/hadoop/app/hadoop
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:/home/hadoop/tools:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME HADOOP_HOME
[iyunv@djt11 app]# source /etc/profile
[hadoop@djt12 app]$ pwd
[hadoop@djt12 app]$ ls
[hadoop@djt12 app]$ su root
[iyunv@djt12 app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
HADOOP_HOME=/home/hadoop/app/hadoop
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME HADOOP_HOME
[iyunv@djt12 app]# source /etc/profile
[hadoop@djt13 app]$ pwd
[hadoop@djt13 app]$ ls
[hadoop@djt13 app]$ su root
[iyunv@djt13 app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
HADOOP_HOME=/home/hadoop/app/hadoop
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME HADOOP_HOME
[iyunv@djt13 app]# source /etc/profile
[hadoop@djt14 app]$ pwd
[hadoop@djt14 app]$ ls
[hadoop@djt14 app]$ su root
[iyunv@djt14 app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
HADOOP_HOME=/home/hadoop/app/hadoop
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME HADOOP_HOME
[iyunv@djt14 app]# source /etc/profile
[hadoop@djt15 app]$ pwd
[hadoop@djt15 app]$ ls
[hadoop@djt15 app]$ su root
[iyunv@djt15 app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
HADOOP_HOME=/home/hadoop/app/hadoop
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME HADOOP_HOME
[iyunv@djt15 app]# source /etc/profile
hdfs配置完毕后启动顺序
1、启动所有Zookeeper
[hadoop@djt11 app]$
runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
[iyunv@djt11 app]# su hadoop
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh status" zookeeper
查看下各节点的zookeeper的启动状态
[iyunv@djt11 app]# su hadoop
[hadoop@djt11 app]$ jps
可以看出,QuorumPeerMain是zookeeper的进程。
[iyunv@djt12 app]# su hadoop
[hadoop@djt12 app]$ jps
可以看出,QuorumPeerMain是zookeeper的进程。
[iyunv@djt13 app]# su hadoop
[hadoop@djt13 app]$ jps
可以看出,QuorumPeerMain是zookeeper的进程。
[iyunv@djt14 app]# su hadoop
[hadoop@djt14 app]$ jps
可以看出,QuorumPeerMain是zookeeper的进程。
[iyunv@djt15 app]# su hadoop
[hadoop@djt15 app]$ jps
可以看出,QuorumPeerMain是zookeeper的进程。
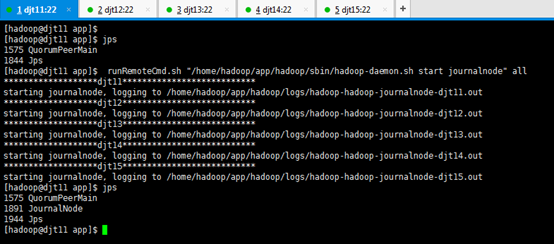
2、每个节点分别启动journalnode
查看djt11的journalnode进程
[hadoop@djt11 app]$
runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode" all
[hadoop@djt11 app]$ ls
[hadoop@djt11 app]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode" all
或者,sbin/hadoop-daemon.sh start journalnode
查看djt12的journalnode进程
查看djt13的journalnode进程
查看djt14的journalnode进程
查看djt15的journalnode进程
3、主节点执行
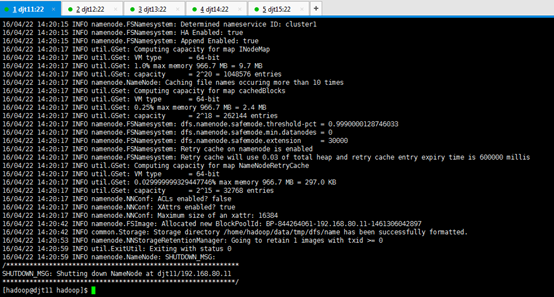
[hadoop@djt11 hadoop]$ bin/hdfs namenode -format //namenode 格式化
[hadoop@djt11 hadoop]$ jps
[hadoop@djt11 hadoop]$ bin/hdfs namenode -format
djt11的namenode格式化完毕
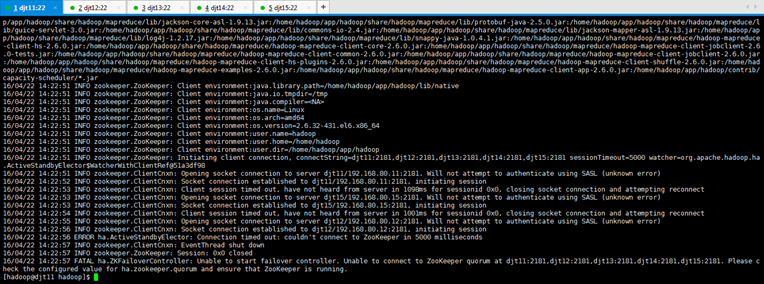
[hadoop@djt11 hadoop]$ bin/hdfs zkfc -formatZK //格式化高可用
格式化高可用完毕
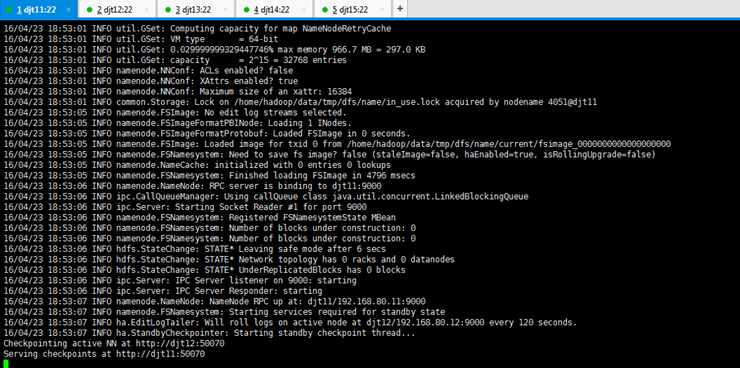
[hadoop@djt11 hadoop]$ bin/hdfs namenode //启动namenode
这里,别怕,它会一直停在这里,是正确的!!!因为要等待下一步的操作。
4、备节点执行
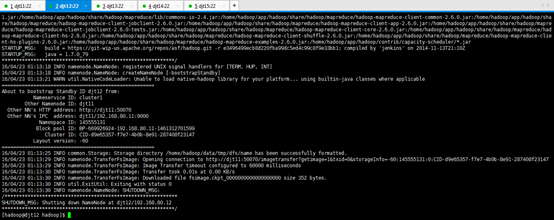
[hadoop@djt12 hadoop]$ bin/hdfs namenode -bootstrapStandby //同步主节点和备节点之间的元数据,也是namenode格式化
[hadoop@djt12 hadoop]$ bin/hdfs namenode -bootstrapStandby
djt12的namenode格式化完毕
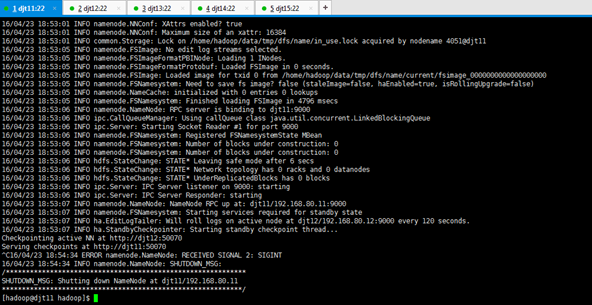
5、停掉hadoop,在djt11按下ctrl+c结束namenode
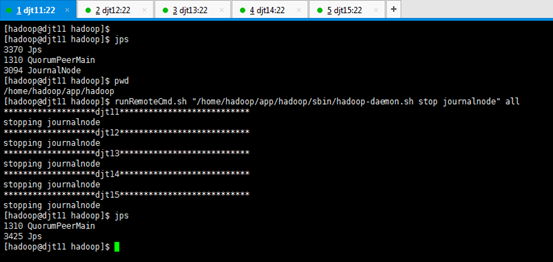
[hadoop@djt11 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode" all
//然后停掉各节点的journalnode
想说的是,为何,在还有QuorumPeerMain进程下,可以一键启动hdfs相关进程。
因为,hdfs与zookeeper是独立的。
6、一键启动hdfs相关进程
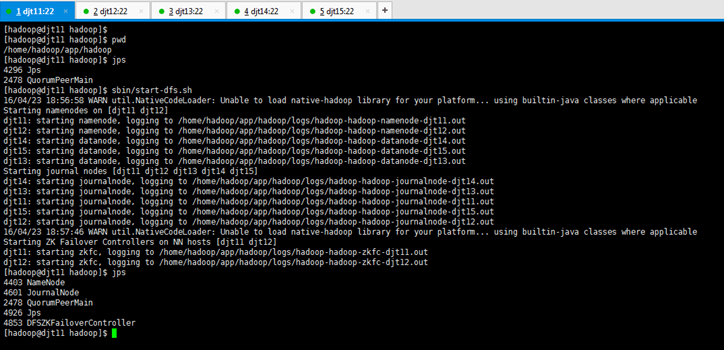
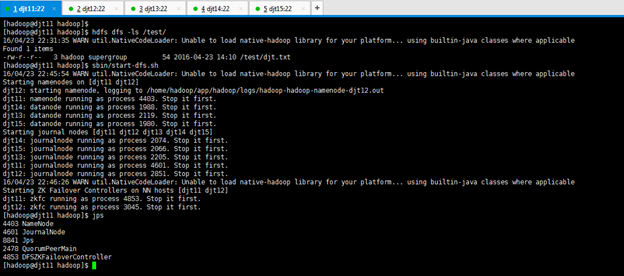
[hadoop@djt11 hadoop]$ sbin/start-dfs.sh
启动成功之后,关闭其中一个namenode ,然后在启动namenode 观察切换的状况。
[hadoop@djt11 hadoop]$ pwd
[hadoop@djt11 hadoop]$ jps
[hadoop@djt11 hadoop]$ sbin/start-dfs.sh
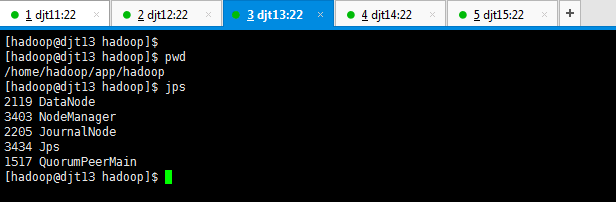
[hadoop@djt11 hadoop]$ jps
4853 DFSZKFailoverController
4601 JournalNode
4403 NameNode
这才是hdfs启动的进程。
2478 QuorumPeerMain
这才是zookeeper启动的进程。
4926 Jps
这本来就有的进程。
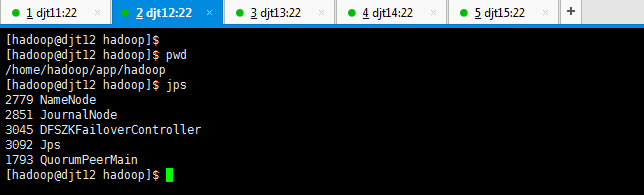
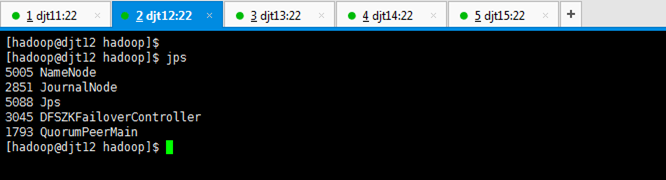
[hadoop@djt12 hadoop]$ pwd
[hadoop@djt12 hadoop]$ jps
3092 Jps
2851 JournalNode
2779 NameNode
3045 DFSZKFailoverController
1793 QuorumPeerMain
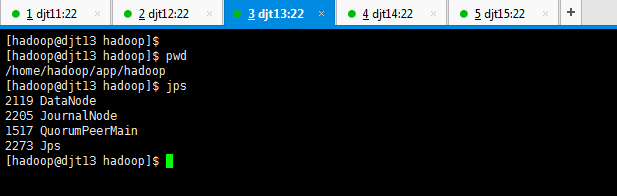
[hadoop@djt13 hadoop]$ pwd
[hadoop@djt13 hadoop]$ jps
2273 Jps
2205 JournalNode
2119 DataNode
2205 QuorumPeerMain
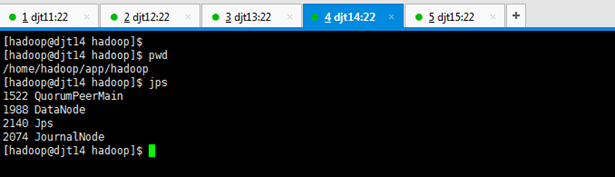
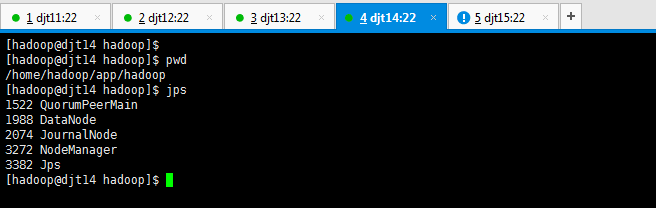
[hadoop@djt14 hadoop]$ pwd
[hadoop@djt14 hadoop]$ jps
2140 Jps
2074 JournalNode
1988 DataNode
1522 QuorumPeerMain
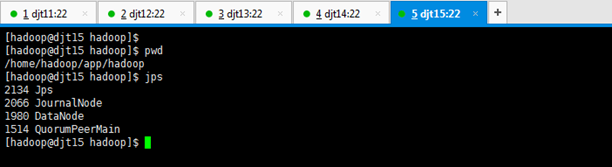
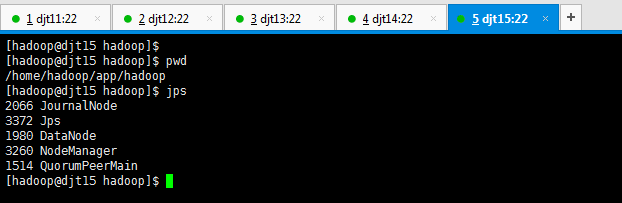
[hadoop@djt15 hadoop]$ pwd
[hadoop@djt15 hadoop]$ jps
2134 Jps
2066 JournalNode
1980 DataNode
1514 QuorumPeerMain
7、验证是否启动成功
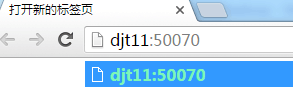
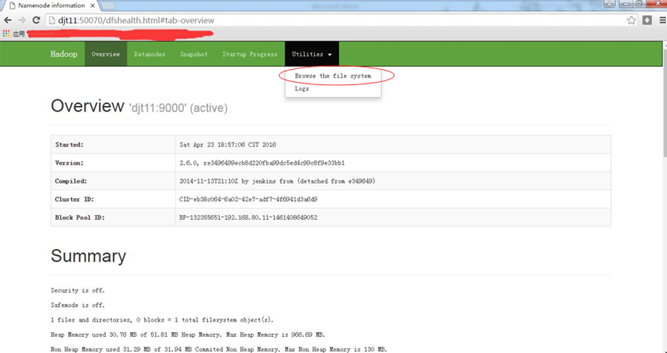
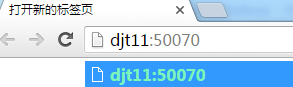
通过web界面查看namenode启动情况。
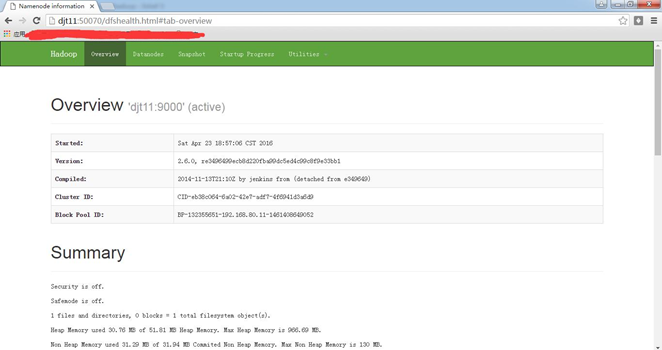
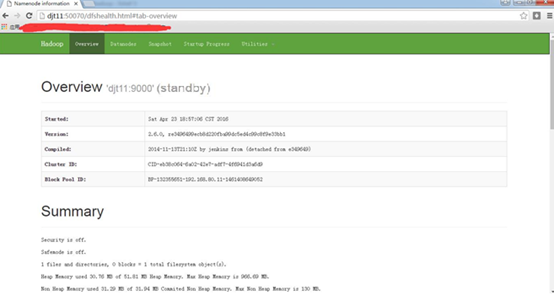
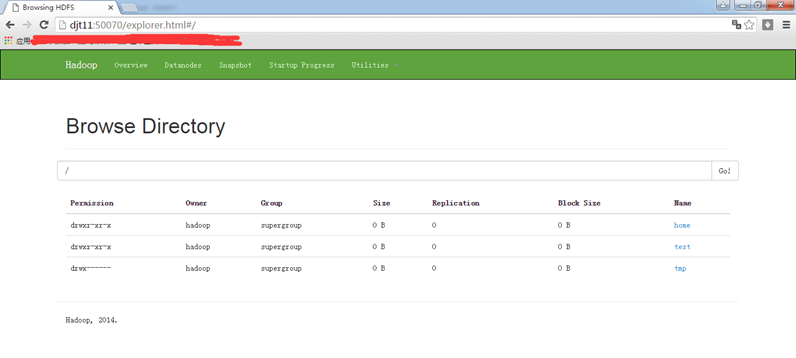
http://djt11:50070
http://djt11:50070/dfshealth.html#tab-overview
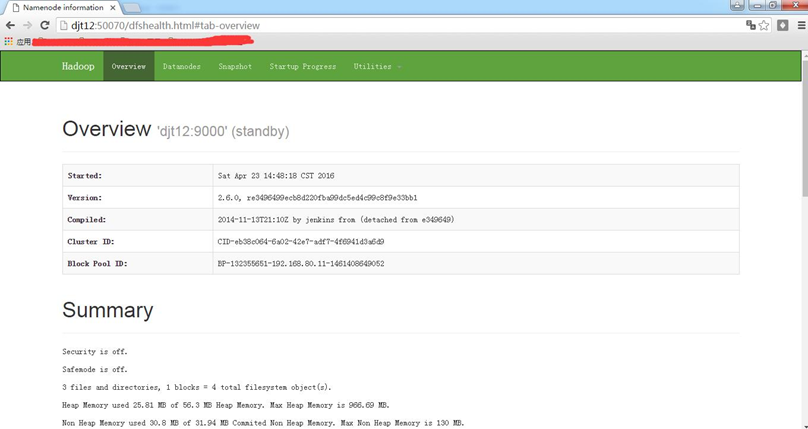
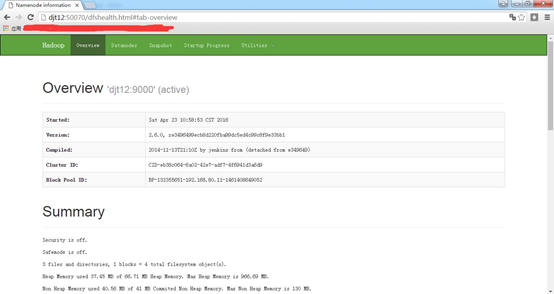
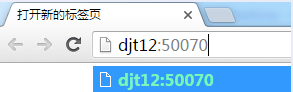
http://djt12:50070
http://djt12:50070/dfshealth.html#tab-overview
或者
上传文件至hdfs
[hadoop@djt11 hadoop]$ hdfs dfs –ls / //本地创建一个djt.txt文件
[hadoop@djt11 hadoop]$ vi djt.txt //本地创建一个djt.txt文件
hadoop dajiangtai
hadoop dajiangtai
hadoop dajiangtai
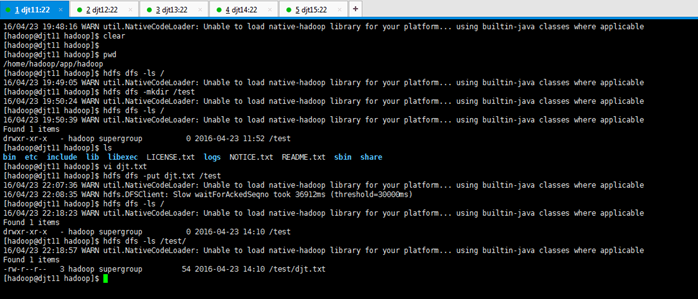
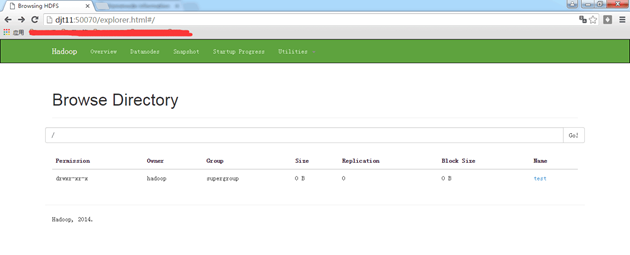
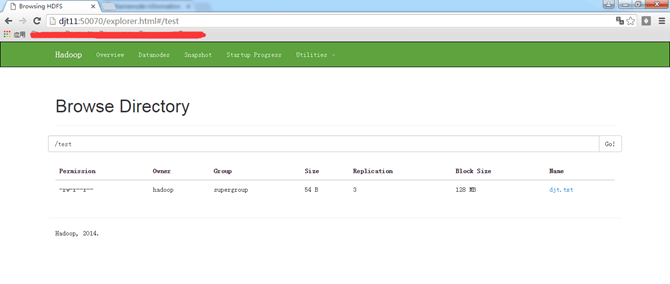
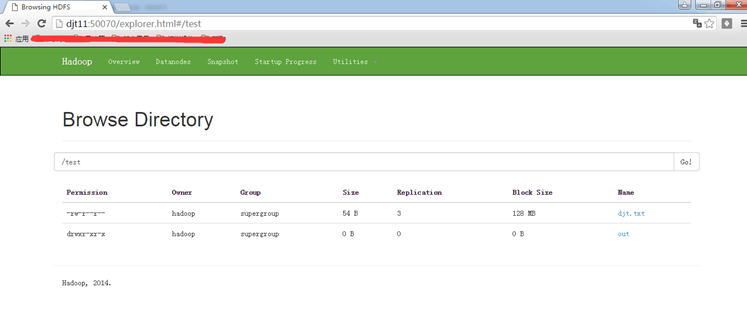
[hadoop@djt11 hadoop]$ hdfs dfs -mkdir /test //在hdfs上创建一个文件目录
[hadoop@djt11 hadoop]$ hdfs dfs -put djt.txt /test //向hdfs上传一个文件
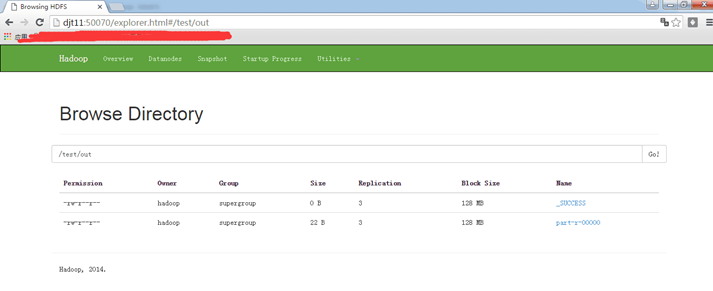
[hadoop@djt11 hadoop]$ hdfs dfs -ls /test //查看djt.txt是否上传成功
如果上面操作没有问题说明hdfs配置成功。
[hadoop@djt11 hadoop]$ hdfs dfs –ls /
[hadoop@djt11 hadoop]$ hdfs dfs -mkdir /test //在hdfs上创建一个文件目录
[hadoop@djt11 hadoop]$ hdfs dfs –ls /
[hadoop@djt11 hadoop]$ ls
[hadoop@djt11 hadoop]$ vi djt.txt //本地创建一个djt.txt文件
hadoop dajiangtai
hadoop dajiangtai
hadoop dajiangtai
[hadoop@djt11 hadoop]$ hdfs dfs -ls /test //查看djt.txt是否上传成功
如果上面操作没有问题说明hdfs配置成功。
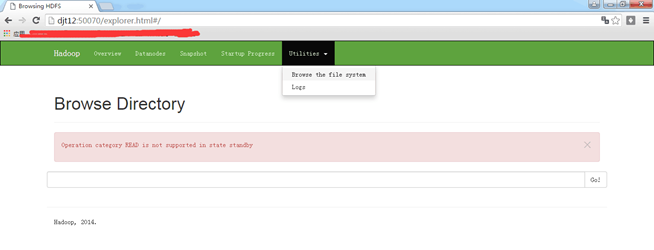
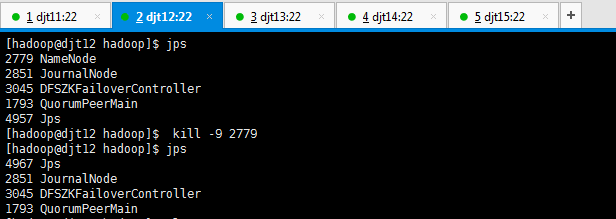
在这里,我想说的是,哪个是active,哪个是standby是随机的 。这是由选举决定的。
若,djt12是active,djt11是standby。则想变成,djt11是active,djt12是standby。
做法:把djt12的namenode 进程杀死。试试
再去,
即可,djt11是active,djt12是standby。
2 YARN安装配置
1、配置mapred-site.xml
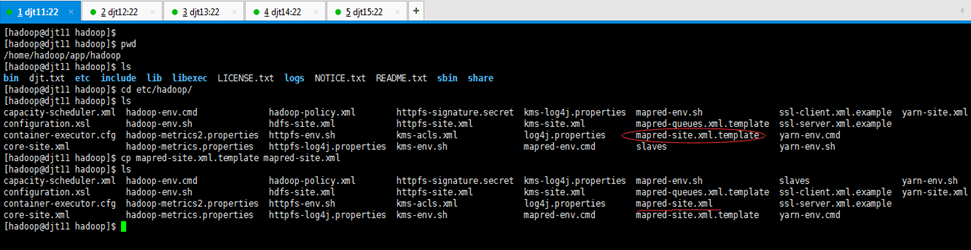
[hadoop@djt11 hadoop]$ pwd
[hadoop@djt11 hadoop]$ ls
[hadoop@djt11 hadoop]$ cd etc/hadoop/
[hadoop@djt11 hadoop]$ ls
[hadoop@djt11 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@djt11 hadoop]$ ls
解读
[hadoop@djt11 hadoop]$ vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<指定运行mapreduce的环境是Yarn,与hadoop1不同的地方>
</configuration>

[hadoop@djt11 hadoop]$ pwd
[hadoop@djt11 hadoop]$ vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2、配置yarn-site.xml
解读
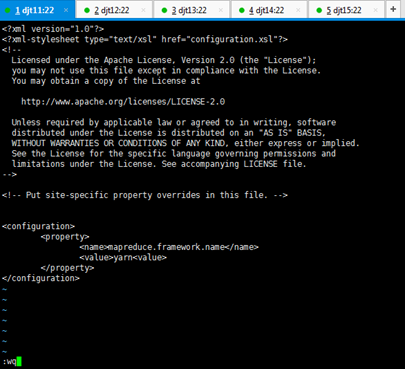
[hadoop@djt11 hadoop]$ vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
< 超时的周期>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
< 打开高可用>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<启动故障自动恢复>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
<给yarn cluster 取个名字yarn-rm-cluster>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<给ResourceManager 取个名字 rm1,rm2>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>djt11</value>
</property>
<配置ResourceManager rm1 hostname>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>djt12</value>
</property>
<配置ResourceManager rm2 hostname>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<启用resourcemanager 自动恢复>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>djt11:2181,djt12:2181,djt13:2181,djt14:2181,djt15:2181</value>
</property>
<配置Zookeeper地址>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>djt11:2181,djt12:2181,djt13:2181,djt14:2181,djt15:2181</value>
</property>
<配置Zookeeper地址>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>djt11:8032</value>
</property>
< rm1端口号>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>djt11:8034</value>
</property>
< rm1调度器的端口号>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>djt11:8088</value>
</property>
< rm1 webapp端口号>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>djt12:8032</value>
</property>
< rm2端口号>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>djt12:8034</value>
</property>
< rm2调度器的端口号>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>djt12:8088</value>
</property>
< rm2 webapp端口号>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<执行MapReduce需要配置的shuffle过程>
</configuration>
[hadoop@djt11 hadoop]$ pwd
[hadoop@djt11 hadoop]$ vi yarn-site.xml
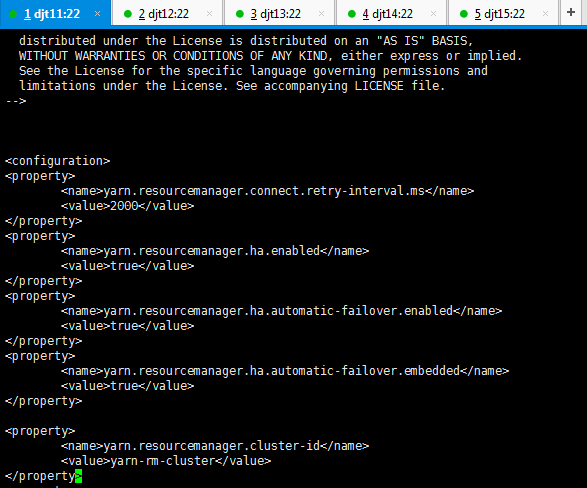
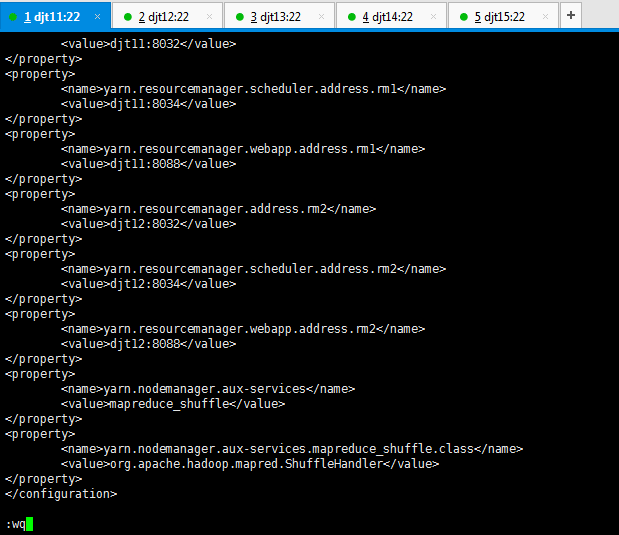
请用下面的这个,
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
<property>
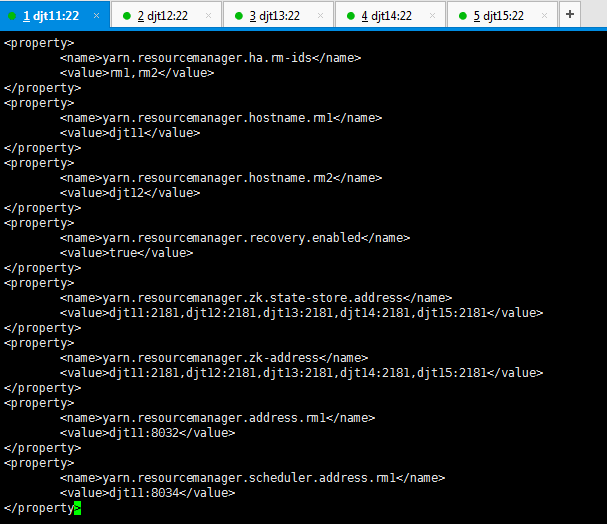
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>djt11</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>djt12</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>djt11:2181,djt12:2181,djt13:2181,djt14:2181,djt15:2181</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>djt11:2181,djt12:2181,djt13:2181,djt14:2181,djt15:2181</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>djt11:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>djt11:8034</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>djt11:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>djt12:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>djt12:8034</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>djt12:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
将djt11刚创好的mapred-site.xml和 yarn-site.xml 分发到djt12,djt13,djt14,djt15
[hadoop@djt11 hadoop]$ pwd
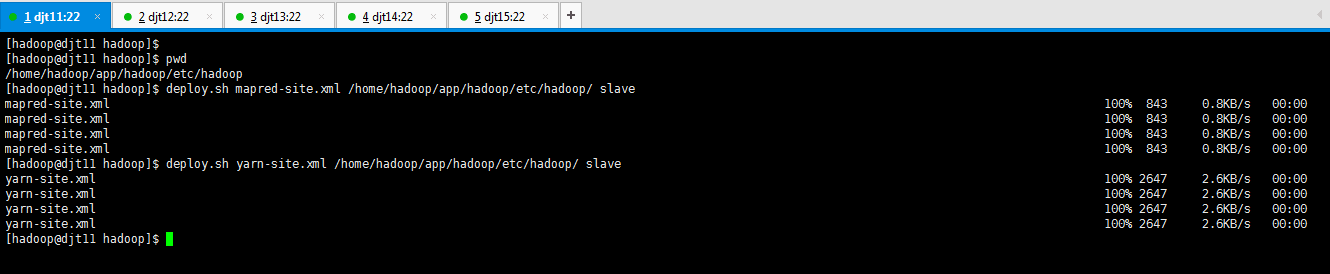
[hadoop@djt11 hadoop]$ deploy.sh mapred-site.xml /home/hadoop/app/hadoop/etc/hadoop/ slave
[hadoop@djt11 hadoop]$ deploy.sh yarn-site.xml /home/hadoop/app/hadoop/etc/hadoop/ slave
3、启动YARN
1、在djt11节点上执行。
[hadoop@djt11 hadoop]$ pwd
[hadoop@djt11 hadoop]$ cd ..
[hadoop@djt11 etc]$ cd ..
[hadoop@djt11 hadoop]$ pwd
[hadoop@djt11 hadoop]$ ls
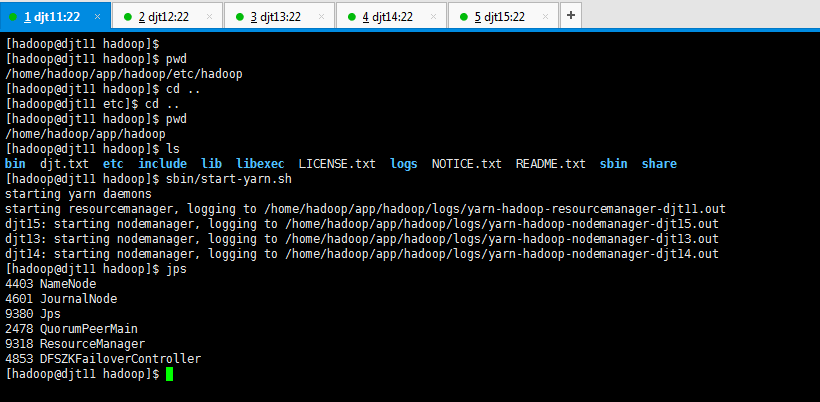
[hadoop@djt11 hadoop]$ sbin/start-yarn.sh
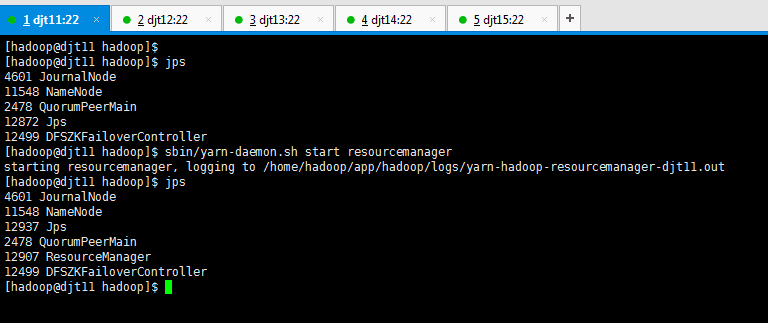
[hadoop@djt11 hadoop]$ jps
4403 NameNode
4601 JournalNode
9380 Jps
2478 QuorumPeerMain
9318 ResourceManager
4853 DFSZKFailoverController
[hadoop@djt11 hadoop]$
Yarn的进程是 ResourceManager
2、在djt12节点上面执行。
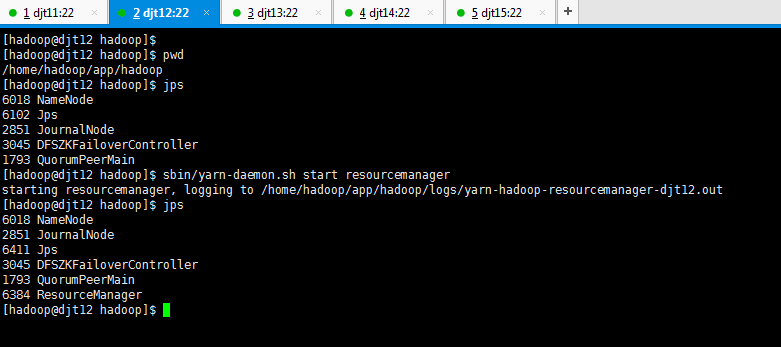
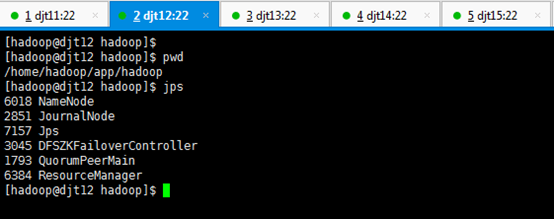
[hadoop@djt12 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
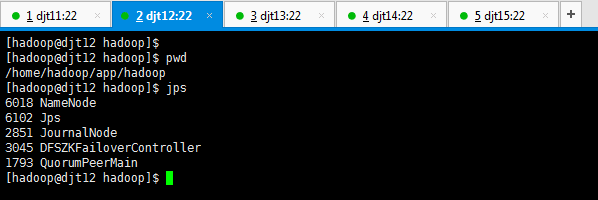
[hadoop@djt12 hadoop]$ jps
6018 NameNode
2851 JournalNode
6411 Jps
3045 DFSZKFailoverController
1793 QuorumPeerMain
6384 ResourceManager
[hadoop@djt12 hadoop]$
3、检查一下ResourceManager状态
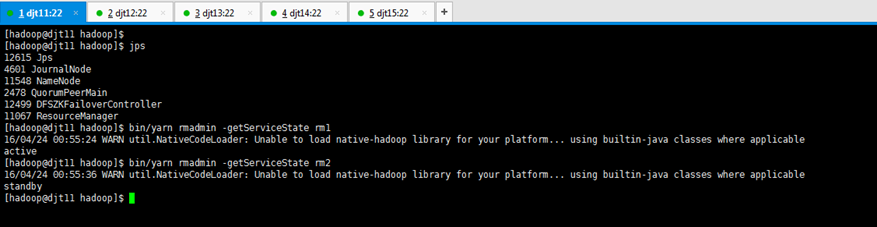
[hadoop@djt11 hadoop]$ bin/yarn rmadmin -getServiceState rm1
[hadoop@djt11 hadoop]$ bin/yarn rmadmin -getServiceState rm2
[hadoop@djt11 hadoop]$ jps
12615 Jps
4601 JournalNode
11548 NameNode
2478 QuorumPeerMain
12499 DFSZKFailoverController
11067 ResourceManager
[hadoop@djt11 hadoop]$ bin/yarn rmadmin -getServiceState rm1
[hadoop@djt11 hadoop]$ bin/yarn rmadmin -getServiceState rm2
[hadoop@djt11 hadoop]$
即djt11的ResourceManager,即rm1,是active,
djt11的ResourceManager,即rm2,是standby
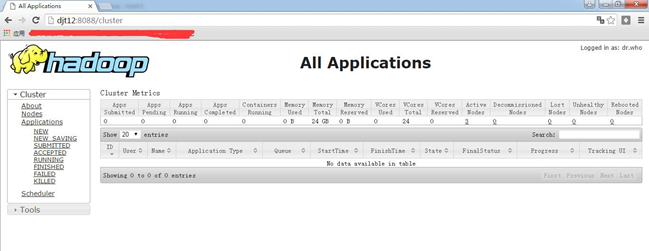
同时打开一下web界面。
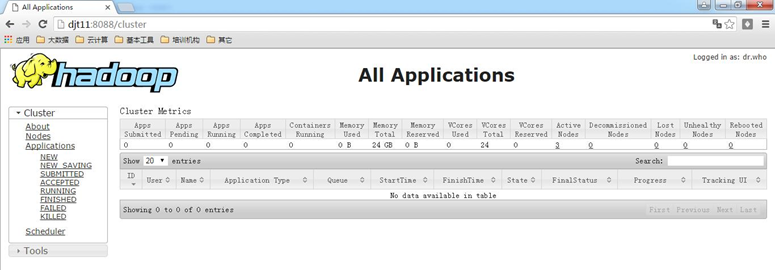
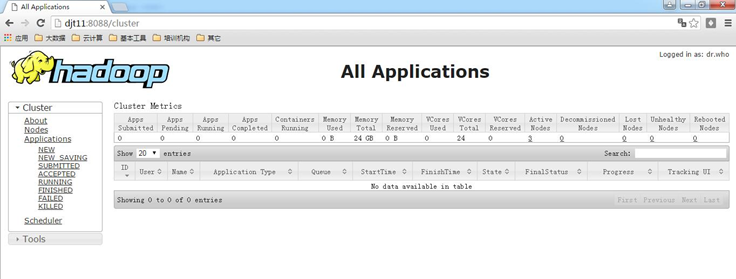
http://djt11:8088
http://djt12:8088
即djt11的ResourceManager,即rm1,是active,
djt11的ResourceManager,即rm2,是standby
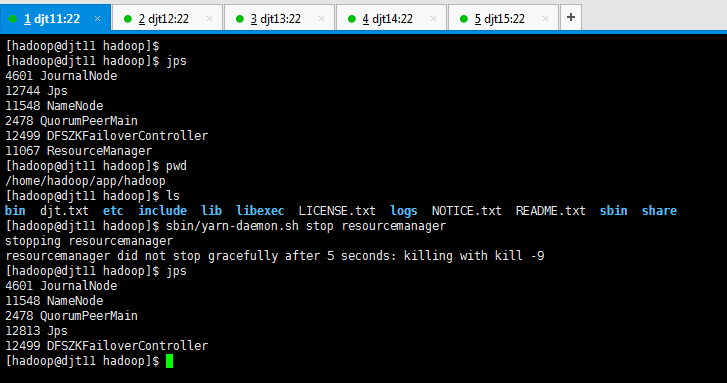
关闭其中一个resourcemanager,然后再启动,看看这个过程的web界面变化。
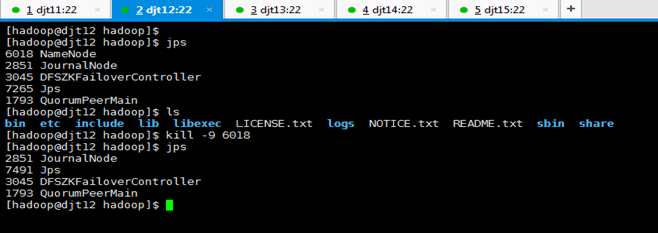
比如,我们将djt11的resourcemanager干掉,则
[hadoop@djt11 hadoop]$ sbin/yarn-daemon.sh stop resourcemanager
[hadoop@djt11 hadoop]$ jps
4601 JournalNode
12744 Jps
11548 NameNode
2478 QuorumPeerMain
12499 DFSZKFailoverController
11067 ResourceManager
[hadoop@djt11 hadoop]$ pwd
/home/hadoop/app/hadoop
[hadoop@djt11 hadoop]$ ls
[hadoop@djt11 hadoop]$ sbin/yarn-daemon.sh stop resourcemanager
stopping resourcemanager
resourcemanager did not stop gracefully after 5 seconds: killing with kill -9
[hadoop@djt11 hadoop]$ jps
4601 JournalNode
11548 NameNode
2478 QuorumPeerMain
12813 Jps
12499 DFSZKFailoverController
[hadoop@djt11 hadoop]$
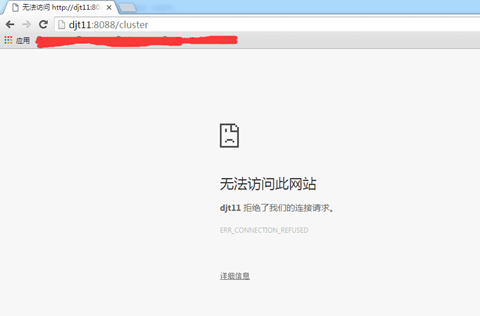
即,把djt11关掉,则djt12起来。
把djt12关掉,则djt11起来。
这里,我们为了后续方便,把djt11起来,djt12关掉。都无所谓啦!
4、Wordcount示例测试
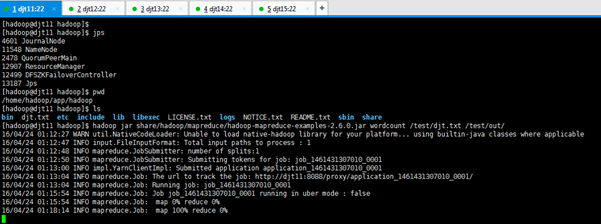
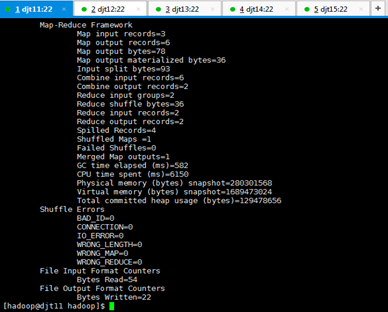
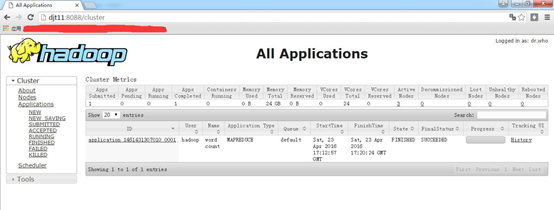
[hadoop@djt11 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /test/djt.txt /test/out/
此刻,需将djt12的namenode杀死,来启动djt11的avtive,djt12的standby。
如果上面执行没有异常,说明YARN安装成功。
! !! 至此,hadoop 5节点分布式集群搭建完毕!!!
那么,hadoop的5节点集群搭建完毕,我们使用zookeeper来管理hadoop集群,同时,实现了namenode热备和ResourceManager热备。
3、启动YARN
1、在djt11节点上执行。
[hadoop@djt11 hadoop]$ sbin/start-yarn.sh |
 QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2017-6-23 11:50:29
发表于 2017-6-23 11:50:29








































































































 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡