|
|
1. MapReduce 与 HDFS 简介
什么是 Hadoop ?
Google 为自己的业务需要提出了编程模型 MapReduce 和分布式文件系统 Google File System,并发布了相关论文(可在 Google Research 的网站上获得:GFS、MapReduce)。Doug Cutting 和 Mike Cafarella 在开发搜索引擎 Nutch 时对这两篇论文进行了自己的实现,即同名的 MapReduce 和 HDFS,合起来就是 Hadoop。
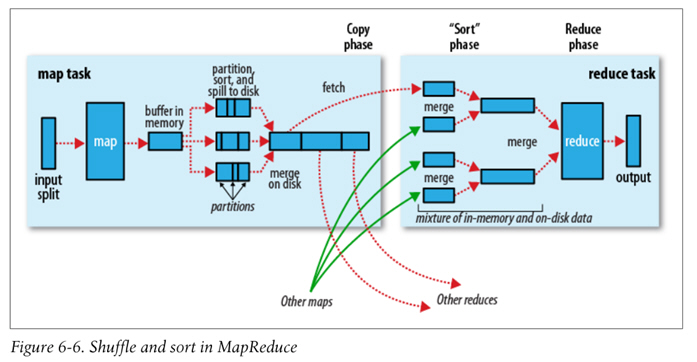
MapReduce 的 Data Flow 如下图所示,原始数据经过 mapper 处理,再进行 partition 和 sort,到达 reducer,输出最后结果。
2. Hadoop Streaming 原理
Hadoop 本身是用 Java 开发的,程序也需要用 Java 编写,但是通过 Hadoop Streaming,我们可以使用任意语言来编写程序,让 Hadoop 运行。
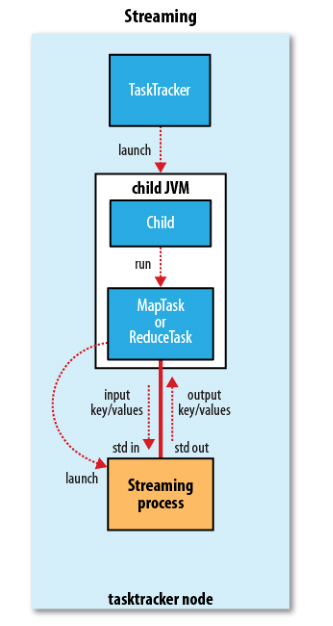
Hadoop Streaming 就是通过将其他语言编写的 mapper 和 reducer 通过参数传给一个事先写好的 Java 程序(Hadoop 自带的 *-streaming.jar),这个 Java 程序会负责创建 MR 作业,另开一个进程来运行 mapper,将得到的输入通过 stdin 传给它,再将 mapper 处理后输出到 stdout 的数据交给 Hadoop,经过 partition 和 sort 之后,再另开进程运行 reducer,同样通过 stdin/stdout 得到最终结果。因此,我们只需要在其他语言编写的程序中,通过 stdin 接收数据,再将处理过的数据输出到 stdout,Hadoop Streaming 就能通过这个 Java 的 wrapper 帮我们解决中间繁琐的步骤,运行分布式程序。
原理上只要是能够处理 stdio 的语言都能用来写 mapper 和 reducer,也可以指定 mapper 或 reducer 为 Linux 下的程序(如 awk、grep、cat)或者按照一定格式写好的 java> 1. Hadoop Streaming 的优缺点
优点:
1. 可以使用自己喜欢的语言来编写 MapReduce 程序(不必非得使用 Java)
2. 不需要像写 Java 的 MR 程序那样 import 一大堆裤,在代码里做很多配置,很多东西都抽象到了 stdio 上,代码量显著减少。
3. 因为没有库的依赖,调试方便,并且可以脱离 Hadoop 先在本地用管道模拟调试。
缺点:
1. 只能通过命令行参数来控制 MapReduce 框架,不像 Java 的程序那样可以在代码里使用 API,控制力比较弱。
2. 因为中间隔着一层处理,效率会比较慢。
3. 所以 Hadoop Streaming 比较适合做一些简单的任务,比如用 Python 写只有一两百行的脚本。如果项目比较复杂,或者需要进行比较细致的优化,使用 Streaming 就容易出现一些束手束脚的地方。
2. 用 Python 编写简单的 Hadoop Streaming 程序
使用 Python 编写 Hadoop Streaming 程序有几点需要注意:
1. 在能使用 iterator 的情况下,尽量使用 iterator,避免将 stdin 的输入大量储存在内存里,否则会严重降低性能。
2. Streaming 不会帮你分割 key 和 value 传进来,传进来的只是一个个字符串而已,需要你自己在代码里手动调用 split()。
3. 从 stdin 得到的每一行数据末尾似乎会有 '\n' ,保险起见一般都需要用 rstrip() 来去掉。
4. 在想获得 key-value list 而不是一个个处理 key-value pair 时,可以使用 groupby 配合 itemgetter 将 key 相同的 key-value pair 组成一个个 group,得到类似 Java 编写的 reduce 可以直接获取一个 Text 类型的 key 和一个 iterable 作为 value 的效果。注意 itemgetter 的效率比 lambda 表达式的效率要高,所以用 itemgetter 比较好。
编写 Hadoop Streaming 程序的基本模版:
#!/usr/bin/env python
#
-*- coding: utf-8 -*-
"""
Some description here...
"""
import sys
from operator import itemgetter
from itertools import groupby
def read_input(file):
"""Read input and split."""
for line in file:
yield line.rstrip().split('\t')
def main():
data = read_input(sys.stdin)
for key, kviter in groupby(data, itemgetter(0)):
# some code here..
if __name__ == "__main__":
main()
如果对输入输出格式有不同于默认的控制,主要会在 read_input() 里调整。
3. 本地调试
本地调试用于 Hadoop Streaming 的 Python 程序的基本模式是:
$ cat <input path> | python <path to mapper script> | sort -t $'\t' -k1,1 | python <path to reducer script> > <output path>
这里有几点需要注意:
1. Hadoop 默认按照 tab 来分割 key 和 value,以第一个分割出的部分为 key,按 key 进行排序,因此这里使用 sort -t $'\t' -k1,1 来模拟。如果有其他需求,在交给 Hadoop Streaming 执行时可以通过命令行参数设置,本地调试也可以进行相应的调整,主要是调整 sort 的参数。
2. 如果在 Python 脚本里加上了 shebang,并且为它们添加了执行权限,也可以用类似于 ./mapper.py (会根据 shebang 自动调用指定的解释器来执行文件)来代替 python mapper.py。
4. 在集群上运行与监控
1. 察看文档
首先需要知道用于 Streaming 的 Java 程序在哪里。在 1.0.x 的版本中,应该都在 $HADOOP_HOME/contrib/streaming/ 下:
$HADOOP_HOME/contrib/streaming/hadoop-streaming-1.0.4.jar
通过执行 Hadoop 命令
hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-streaming-1.0.4.jar -info
就会看到一系列 Streaming 自带的帮助,带有各种参数的说明和使用样例。
5. 运行命令
用 Hadoop Streaming 执行 Python 程序的一般步骤是:
1. 将输入文件放到 HDFS 上,建议使用 copyFromLocal 而不是 put 命令。参见Difference between hadoop fs -put and hadoop fs -copyFromLocal
1. 一般可以新建一个文件夹用于存放输入文件,假设叫 input
$ hadoop fs -mkdir input
然后用
$ hadoop fs -ls
查看目录,可以看到出现了一个 /user/hadoop/input 文件夹。/user/hadoop 是默认的用户文件夹,相当于本地文件系统中的 /home/hadoop。
2. 再使用
$ hadoop fs -copyFromLocal <PATH TO LOCAL FILE(s)> input/
将本地文件放到 input 文件夹下。
2. 开始 MapReduce 作业,假设你现在正在放有 mapper 和 reducer 两个脚本的目录下,而且它们刚好就叫 mapper.py 和 reducer.py,在不需要做其他配置的情况下,执行
$ hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-streaming-1.0.4.jar \
-mapper mapper.py \
-file mapper.py \
-reducer reducer.py \
-file reducer.py \
-input input/* \
-output output
第一行是告诉 Hadoop 运行 Streaming 的 Java 程序,接下来的是参数:
这里的 mapper.py 和 reducer.py 是 mapper 所对应 python 程序的路径。为了让 Hadoop 将程序分发给其他机器,需要再加一个 -file 参数用于指明要分发的程序放在哪里。
注意这样写的前提是这个 Python 程序里有 Shebang 而且添加了执行权限。如果没有的话可以改成
-mapper 'python mapper.py'
加上解释器命令,用引号扩住(注意在参数中传入解释器命令,不再是用`符扩住,而是'符)。准确来说,mapper 后面跟的骑士应该是一个命令而不是文件名。
假如你执行的程序不放在当前目录下,比如说在当前目录的 src 文件夹下,可以这样写
-mapper 'python mapper.py' -file src/mapper.py \
-reducer 'python reducer.py' -file src/reducer.py \
也就是说,-mapper 和 -reducer 后面跟的文件名不需要带上路径,而 -file 后的参数需要。注意如果你在 mapper 后的命令用了引号,加上路径名反而会报错说找不到这个程序。(因为 -file 选项会将对应的本地参数文件上传至 Hadoop Streaming 的工作路径下,所以再执行 -mapper 对应的参数命令能直接找到对应的文件。
-input 和 -output 后面跟的是 HDFS 上的路径名,这里的 input/* 指的是"input 文件夹下的所有文件",注意 -output 后面跟着的需要是一个不存在于 HDFS 上的路径,在产生输出的时候 Hadoop 会帮你创建这个文件夹,如果已经存在的话就会产生冲突。(因此每次执行 Hadoop Streaming 前可以通过脚本命令 hadoop fs -rmr 清除输出路径)。
有时候 Shebang 不一定能用,尤其是在执行环境比较复杂的时候,最保险的做法是:
$ hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-streaming-1.0.4.jar \
-mapper 'python mapper.py' -file mapper.py \
-reducer 'python reducer.py' -file reducer.py \
-input input/* -output output
这样写还有一个好处,就是可以在引号里写上提供给 python 程序的命令行参数,甚至做目录的变更以及环境变量的初始化等一系列 shell 命令。
由于 mapper 和 reducer 参数跟的实际上是命令,所以如果每台机器上 python 的环境配置不一样的话,会用每台机器自己的配置去执行 python 程序。
6. 得到结果
成功执行完这个任务之后,使用 output 参数在 HDFS 上指定的输出文件夹里就会多出几个文件:一个空白文件 _SUCCESS,表面 job 运行成功,这个文件可以让其他程序只要查看一下 HDFS 就能判断这次 job 是否运行成功,从而进行相关处理。
一个 _logs 文件夹,装着任务日志。
part-00000,.....,part-xxxxx 文件,有多少个 reducer 后面的数字就会有多大,对应每个 reducer 的输出结果。
假如你的输出很少,比如是一个只有几行的计数,你可以用
$ hadoop fs -cat <PATH ON HDFS>
直接将输出打印到终端查看。
假如你的输出很多,则需要拷贝到本地文件系统来查看。可以使用 copyToLocal 来获取整个文件夹。如果你不需要 _SUCCESS 和 _logs,并且想要将所有 reducer 的输出合并,可以使用 getmerge 命令。
$ hadoop fs -getmerge output ./
上述命令将 output 下的 part-xxxxx 合并,放到当前目录的一个叫 output 的文件里。
7. 如何串联多趟 MapReduce
如果有多次任务要执行,下一步需要用上一步的任务做输入,解决办法很简单。假设上一步在 HDFS 的输出文件夹是 output1,那么在下一步的运行命令中,指明
-input output1/part-*
即指定上一次的所有输出为本次任务的输入即可。
8. 使用额外的文件
假如 MapReduce 的 job 除了输入以外还需要一些额外的文件,有两种选择:
1. 大文件
所谓的大文件就是大小大于设置的 local.cache.size 的文件,默认是10GB。这个时候可以用 -file 来分发。除此之外代码本身也可以用 file 来分发。
格式:假如我要加多一个 sideData.txt 给 python 脚本使用:
$ hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input inputDir \
-output outputDir \
-mapper mapper.py \
-file mapper.py \
-reducer reducer.py \
-file reducer.py \
-file sideData.txt
这样 -file 选项的参数文件都会被上传至 MapReduce 的工作目录下,所以 mapper 和 reducer 代码都可以通过文件名直接访问到文件。在 python 脚本中,只要把这个文件当成自己同一目录下的本地文件来打开就可以了。比如:
f = open('sideData.txt')
注意这个 file 是只读的,不可以写。
2. 小文件
如果是比较小的文件,想要提高读写速度可以将它放在 distributed cache 里(也就是每台机器都有自己的一份 copy,不需要网络 IO 就可以拿到数据)。这里要用到的参数是 -cachefile,写法和用法与上一个一样,就是将 -file 改成 -cachefile 而已。
3. 如果上传目录或者多个目录时使用 -files 选项
-files dir1,dir2 #多个目录用','隔开,且不能有空格
上传目录后,可以直接访问当前目录
4. 上传 HDFS 上的文件或者目录
只能 -files 命令上传 HDFS 路径下的文件或目录,然后就可以像访问本地文件一样访问 HDFS 文件。
比如:
hdfs_file="hdfs://webboss-10-166-133-95:9100/user/hive/conf/part-00000"
input
=/user/hive/input/*
output=/user/hive/output
mapper_script=mapper.py
reducer_script=reducer.py
map_file=./mapper.py
reduce_file=./reducer.py
hadoop fs -rmr $output
hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-0.20.2-streaming.jar \
-D mapred.reduce.tasks=0 \
-files $hdfs_file \
-input $input \
-output $output \
-mapper $mapper_script \
-file $map_file \
-reducer $reducer_script \
-file $reduce_file
然后 map 脚本中就可以直接读取名为 part-00000 的文件。详情参考:http://www.cnblogs.com/zhengrunjian/p/4536572.html
9. 控制 partitioner
partitioning 指的是数据经过 mapper 处理后,被分发到 reducer 上的过程。partitioner 控制的,就是“怎样的 mapper 输出会被分发到哪一个 reducer 上”。
Hadoop 有几个自带的 partitoner,解释可以看这里。默认的是 HashPartitioner,也就是把第一个 '\t' 前的 key 做 hash 之后用于分配 partition。写 Hadoop Streaming 程序是可以选择其他 partitioner 的,你可以选择自带的其他几种里的一种,也可以自己写一个继承 Partitioner 的 java 类然后编译成 jar,在运行参数里指定为你用的 partitioner。
官方自带的 partionner 里最常用的是 KeyFieldBasedPartitioner。它会按照 key 的一部分来做 partition,而不是用整个 key 来做 partition。
在学会用 KeyFieldBasedPartitioner 之前,必然要先学怎么控制 key-value 的分割。分割 key 的步骤可以分成两步,用 python 来描述一下大约是
fields = output.split(separator)
key
= fields[:numKeyfields]
1. 选择用什么符号来分割 key,也就是选择 separator
map.output.key.field.separator 可以指定用于分割 key 的符号。比如指定为一点的话,就要加上参数。
-D stream.map.output.field.separator=.
假设你的 mapper 输出是
11.22.33.44
这时会用 '.' 进行分割,看准 [11, 22, 33, 44] 这里的其中一个或几个作为 key。
2. 选择 key 的范围,也就是选择 numKeyfields
控制 key 的范围的参数是这个,假设要设置被分割出的前 2 个元素为 key:
-D stream.num.map.output.key.fields=2
那么 key 就是上面的 1122。值得注意的是假如这个数字设置到覆盖整个输出,在这个例子里是4的话,那么整一行都会变成 key。
上面分割出 key 之后,KeyFieldBasedPartitioner 还需要知道你想要用 key 里的哪部分作为 partition 的依据。它进行配置的过程可以看源代码来理解。
假设在上一步我们通过使用
-D stream.map.output.field.separator=. \
-D stream.num.map.output.key.fields=4
将 11.22.33.44 的整个字符串都设置成了 key,下一步就是在这个 key 的内部再进行一次分割。map.output.key.field.separator 可以用来设置第二次分割用的分割符,mapred.text.key.partitioner.options 可以接受参数来划分被分割出来的 partition key,比如:
-D map.output.key.field.separator=. \
-D mapred.text.key.partitioner.options=-k1,2
指的就是在 key 的内部里,将第1到第2个被点分割的元素作为 partition key,这个例子里也就是 1122。这里的值 -ki,j 表示从 i 到 j 个元素(inclusive)会作为 partition key。如果终点省略不写,像 -ki 的话,那么 i 和 i 之后的元素都会作为 partition key。
partition key 相同的输出会保证分到同一个 reducer 上,也就是所有 11.22.xx.xx 的输出都会到同一个 partitioner,11.22 换成其他各种组合也是一样。
实例说明一下,就是这样的:
1. mapper 的输出是
11.12.1.2
11.14.2.3
11.11.4.1
11.12.1.1
11.14.2.2
2. 指定前 4 个元素做 key,key 里的前两个元素做 partition key,分成 3 个 partition 的话,就会被分成
11.11.4.1
-----------
11.12.1.2
11.12.1.1
-----------
11.14.2.3
11.14.2.2
3. 下一步 reducer 会对自己得到的每个 partition 内进行排序,结果就是
11.11.4.1
-----------
11.12.1.1
11.12.1.2
-----------
11.14.2.2
11.14.2.3
Streaming 命令格式如下:
$ hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-D stream.map.output.field.separator=. \
-D stream.num.map.output.key.fields=4 \
-D map.output.key.field.separator=4 \
-D mapred.text.key.partitioner.options=-k1,2 \
-input inputDir \
-output outputDir \
-mapper mapper.py -file mapper.py \
-reducer reducer.py -file reducer.py \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
注意:
Hadoop 执行命令时的选项是有顺序的,顺序是 bin/hadoop command [genericOptions] [commandOptions].
对于 Streaming,-D 属于 genericOptions,即 hadoop 的通用选项,所以必须写在前面。
Streaming 的所有选项可参考:
hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-0.20.2-streaming.jar -info
3. 控制 comparator 与自定义排序
上面说到 mapper 的输出被 partition 到各个 reducer 之后,会有一步排序。这个排序的标准也是可以通过设置 comparator 控制的。和上面一样,要先设置分割出 key 用的分割符、key 的范围,key 内部分隔用的分割符
-D stream.map.output.field.separator=. \
-D stream.num.map.output.key.fields=4 \
-D map.output.key.field.separator=.
这里要控制的就是 key 内部的哪些元素用来做排序依据,是排字典序还是数字序,倒叙还是正序。用来控制的参数是 mapred.text.key.comparator.options,接受的值格式类似于 unix sort。比如我要按第二个元素的数字序(默认字典序)+倒序来排元素的话,就用 -D mapred.text.key.comparator.options=-k2,2nr
n表示数字序,r表示倒序。这样一来
11.12.1.2
11.14.2.3
11.11.4.1
11.12.1.1
11.14.2.2
就会被排成
11.14.2.3
11.14.2.2
11.12.1.2
11.12.1.1
11.11.4.1
参考:http://www.uml.org.cn/sjjm/201512111.asp |
|
|
 QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2017-12-17 09:39:25
发表于 2017-12-17 09:39:25
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡