public static class TokenizerMapper extends Mapper{
private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one); }
}
}
public static class IntSumReducer extends Reducer { private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); conf.set("mapred.job.tracker", "192.168.80.32:9001");
String[] ars=new String[]{"input","newout"};
String[] otherArgs = new GenericOptionsParser(conf, ars).getRemainingArgs(); if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
备注:如果不加"conf.set("mapred.job.tracker", "192.168.80.32:9001");",将提示你的权限不够,其实照成这样的原因是刚才设置的"Map/Reduce Location"其中的配置不是完全起作用,而是在本地的磁盘上建立了文件,并尝试运行,显然是不行的。我们要让Eclipse提交作业到Hadoop集群上,所以我们这里手动添加Job运行地址。 运行WordCount程序
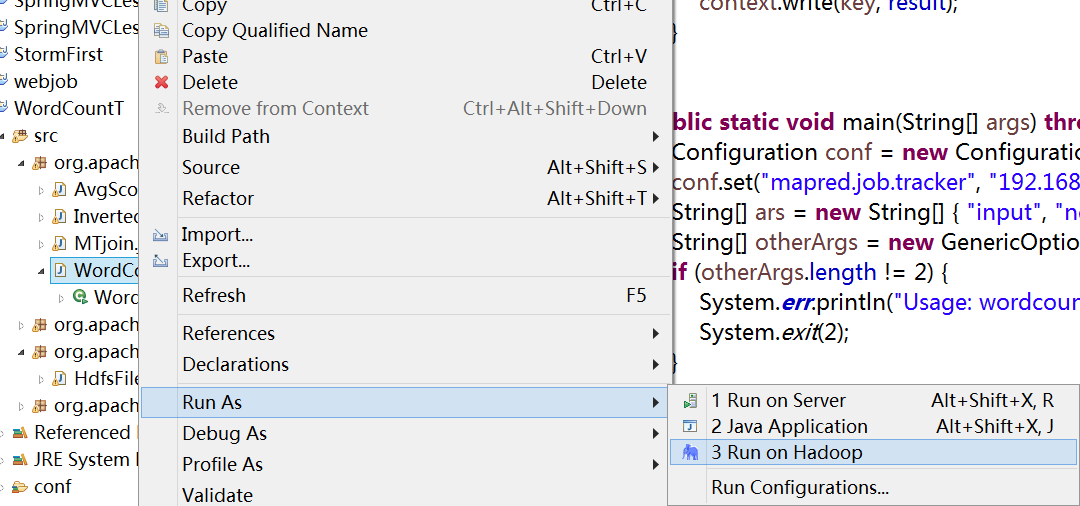
选择"Wordcount.java"程序,右击一次按照"Run AS Run on Hadoop"运行。然后会弹出如下图,按照下图进行操作。
在Console中可以看到输出日志。 查看WordCount运行结果
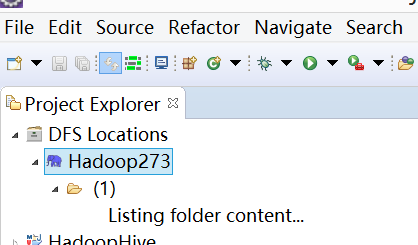
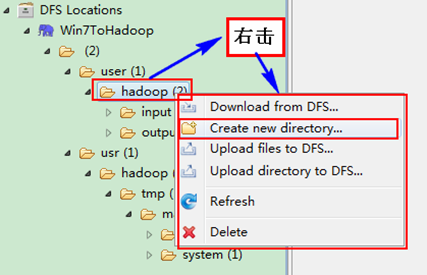
查看Eclipse软件左侧,右击"DFS Locations》Hadoop273》user》hadoop",点击刷新按钮"Refresh",我们刚才出现的文件夹"newoutput"会出现。记得"newoutput"文件夹是运行程序时自动创建的,如果已经存在相同的的文件夹,要么程序换个新的输出文件夹,要么删除HDFS上的那个重名文件夹,不然会出错。
打开"newoutput"文件夹,打开"part-r-00000"文件,可以看见执行后的结果。
还可以将项目导出成jar包,发送到Hadoop服务器上运行,就像运行自带的example一样。
到此为止,Eclipse开发环境设置已经完毕,并且成功运行Wordcount程序,下一步我们真正开始Hadoop之旅。 扩展
以下列出自己和参考园友列出的问题汇总: INFO hdfs.DFSClient: Exception in createBlockOutputStream java.net.NoRouteToHostException: 没有到主机的路由
在每个服务器上jps看下hadoop的进程有没启动,如果都启动了,则停掉主机和几个Slave的防火墙,如果再没有出现问题的话说明相关端口没有开放,在防火墙中加入相关端口。 "error: failure to login"问题
下面以网上找的"hadoop-0.20.203.0"为例,我在使用"V1.0"时也出现这样的情况,原因就是那个"hadoop-eclipse-plugin-1.0.0_V1.0.jar",是直接把源码编译而成,故而缺少相应的Jar包。具体情况如下
详细地址:http://blog.csdn.net/chengfei112233/article/details/7252404
在我实践尝试中,发现hadoop-0.20.203.0版本的该包如果直接复制到eclipse的插件目录中,在连接DFS时会出现错误,提示信息为: "error: failure to login"。
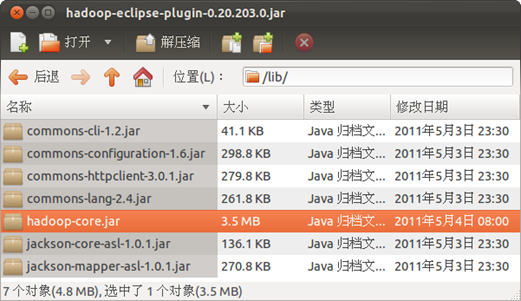
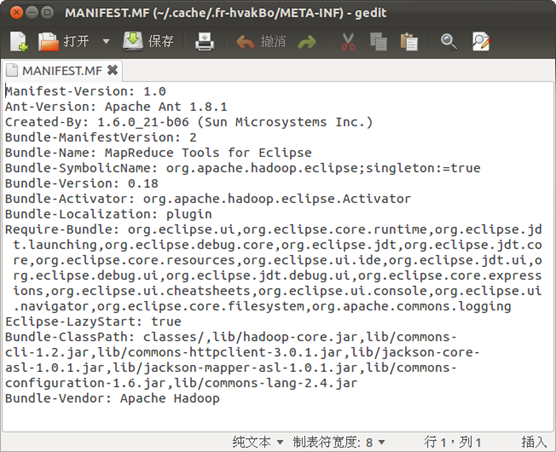
弹出的错误提示框内容为"An internal error occurred during: "Connecting to DFS hadoop".org/apache/commons/configuration/Configuration". 经过察看Eclipse的log,发现是缺少jar包导致的。进一步查找资料后,发现直接复制hadoop-eclipse-plugin-0.20.203.0.jar,该包中lib目录下缺少了jar包。
经过网上资料搜集,此处给出正确的安装方法:
首先要对hadoop-eclipse-plugin-0.20.203.0.jar进行修改。用归档管理器打开该包,发现只有commons-cli-1.2.jar 和hadoop-core.jar两个包。将hadoop/lib目录下的:
 QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2018-10-29 08:01:29
发表于 2018-10-29 08:01:29
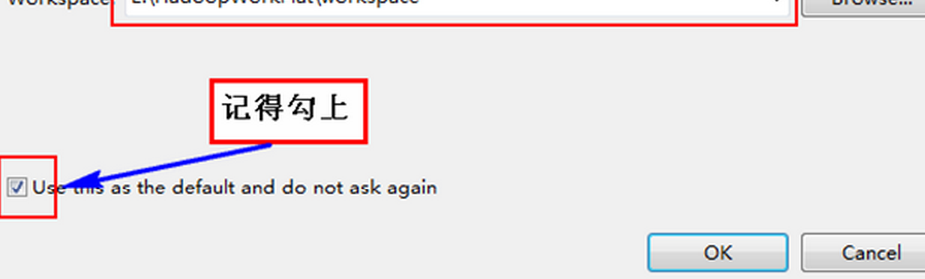
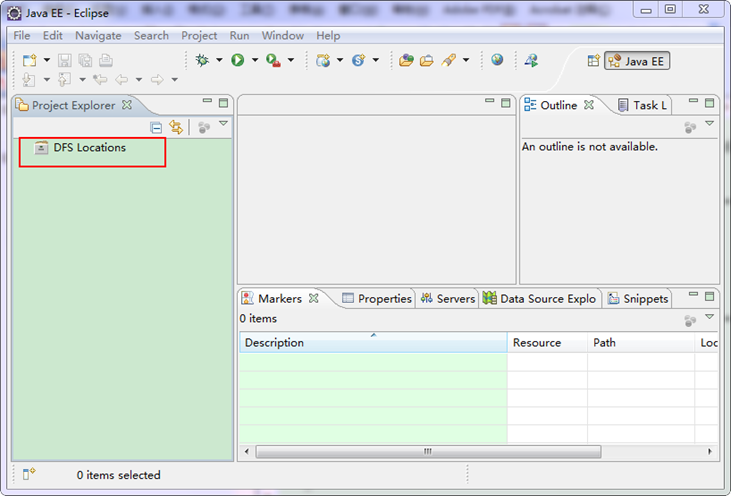
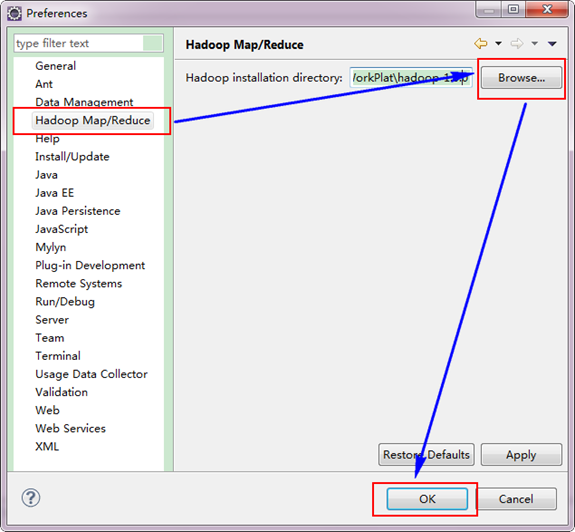
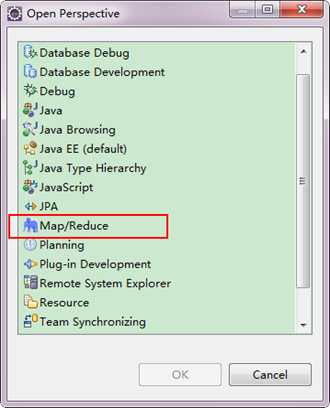
 "中的"
"中的" ",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。
",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。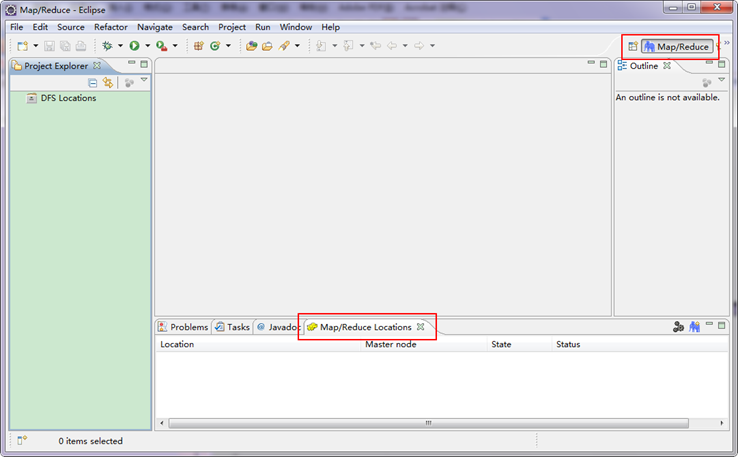

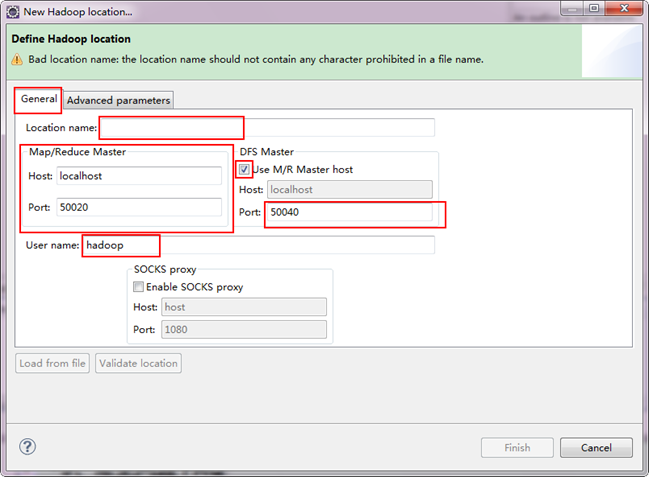
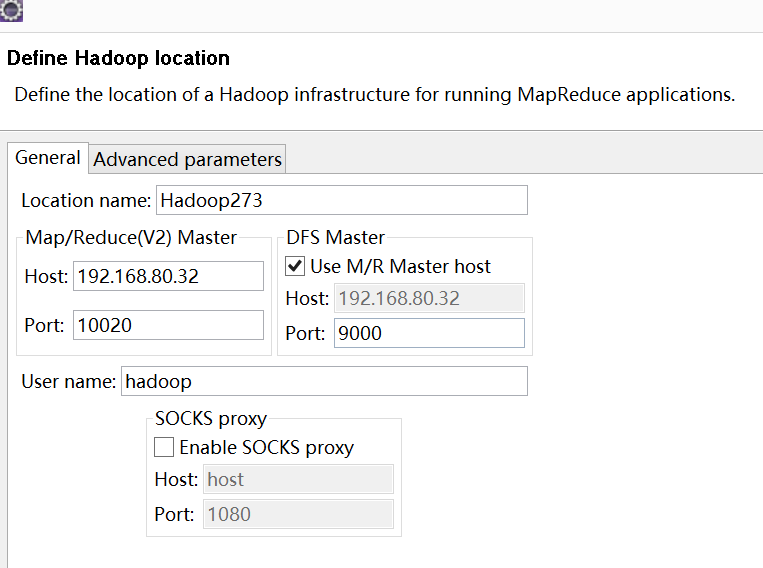
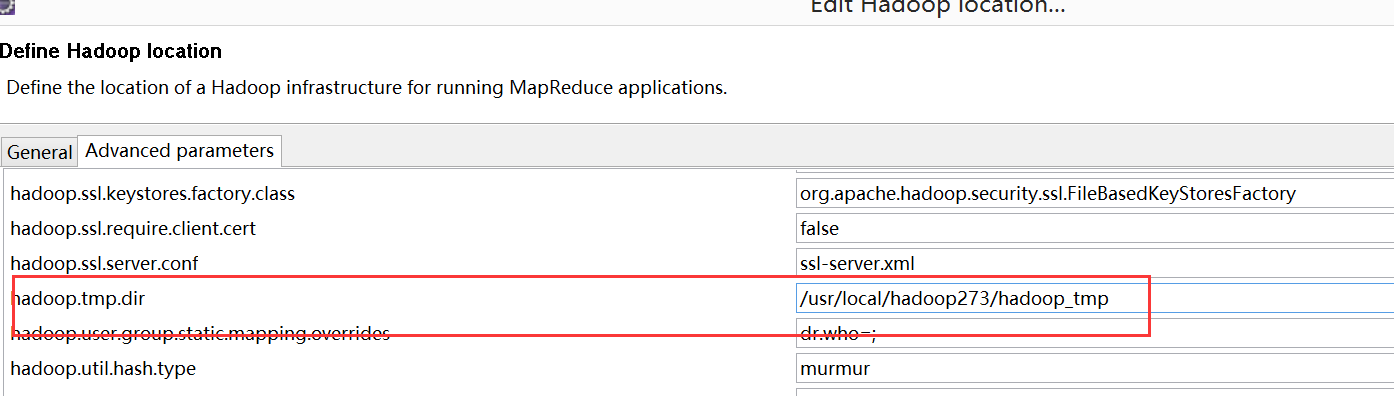


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡