前言a. 用NAT,还是桥接,还是only-host模式? 答: hostonly、桥接和NAT b. 用static的ip,还是dhcp的?c. 别认为快照和克隆不重要,小技巧,比别人灵活用,会很节省时间和大大减少错误。d. 重用起来脚本语言的编程,如paython或shell编程。e. 重要Vmare Tools增强工具,或者,rz上传、sz下载。f. 大多数人常用 Xmanager Enterprise *安装步骤 VMware workstation 11 的下载 VMWare Workstation 11的安装 VMware Workstation 11安装之后的一些配置 CentOS 6.5的安装详解 CentOS 6.5的安装详解 CentOS 6.5安装之后的网络配置 CentOS 6.5静态IP的设置(NAT和桥接都适用) CentOS 命令行界面与图形界面切换 网卡eth0、eth1...ethn谜团 Centos 6.5下的OPENJDK卸载和SUN的JDK安装、环境变量配置 VMware里Ubuntukylin-14.04-desktop的VMware Tools安装图文详解 CentOS常用命令、快照、克隆大揭秘 E:Package 'Vim' has no installation candidate问题解决 新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu) CentOS 6.5安装之后的网络配置 新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu) useradd -m -g 。否则,出现到时,用户建立出来了,但出现家目录没有哦。慎重!!!(重要的话,说三次)(回车) (回车) (回车) hadoop 50070 无法访问问题解决汇总 带你认识spark安装包的目录结构
运维网声明
1、欢迎大家加入本站运维交流群:群②:261659950 群⑤:202807635 群⑦870801961 群⑧679858003运维网
 QQ群⑧:
QQ群⑧:










 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2017-6-2 12:49:48
发表于 2017-6-2 12:49:48



















































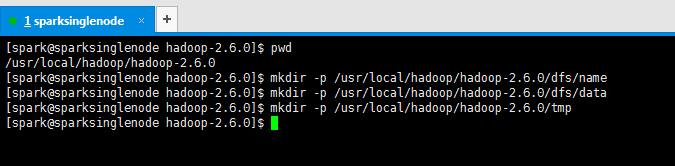
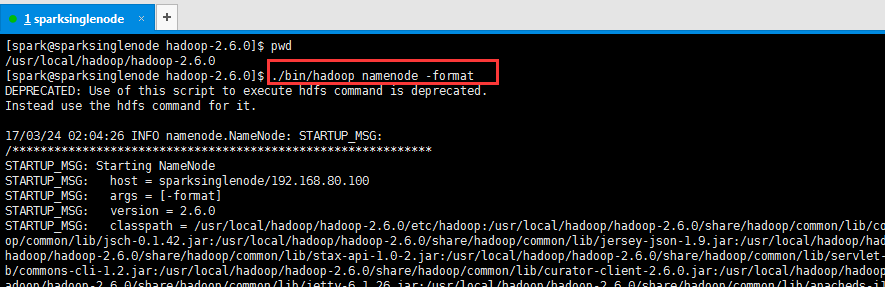

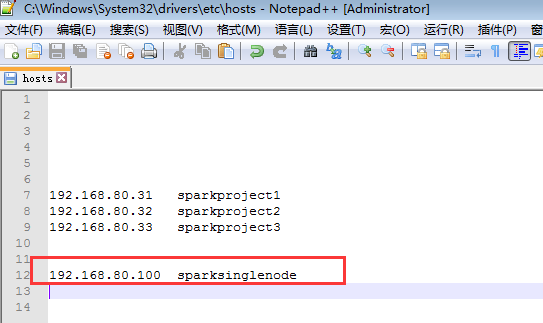
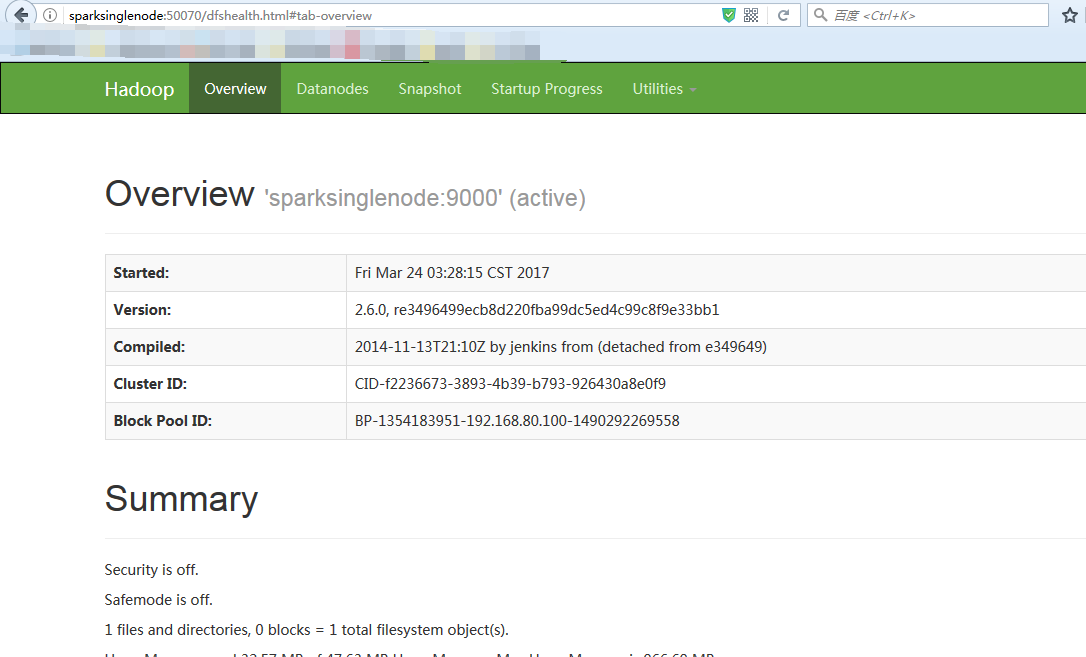
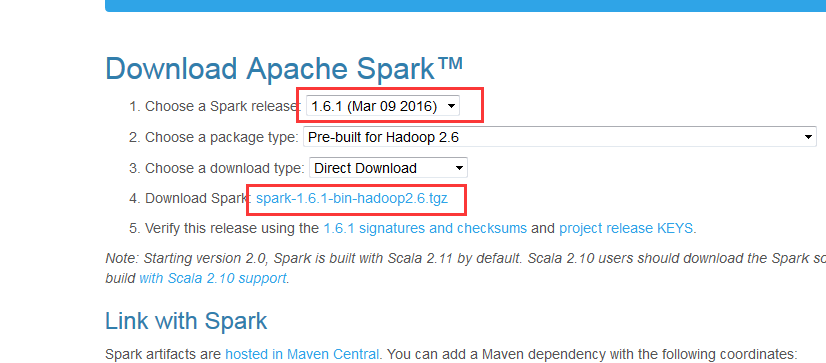

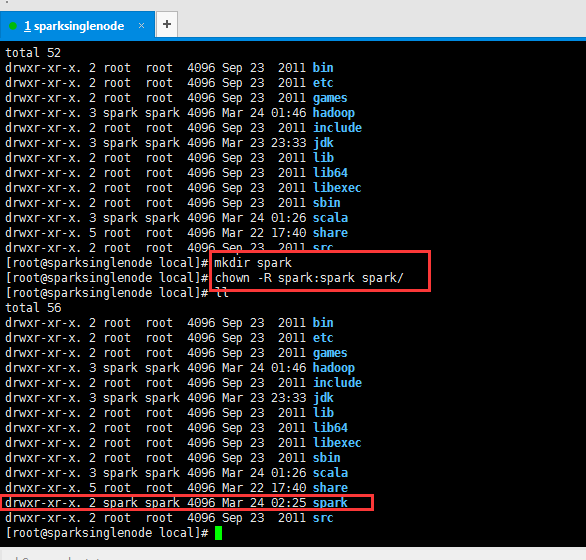
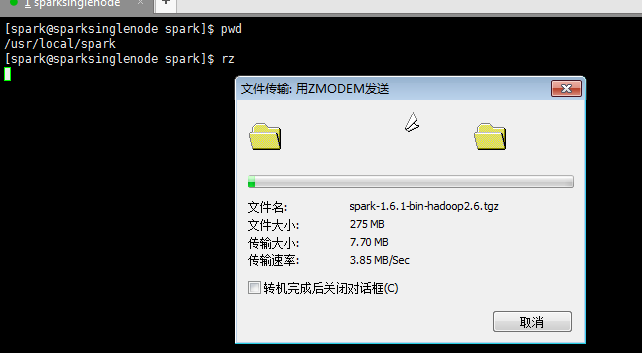
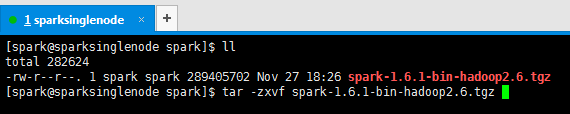
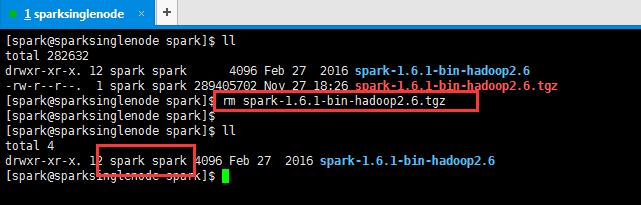
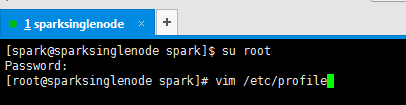




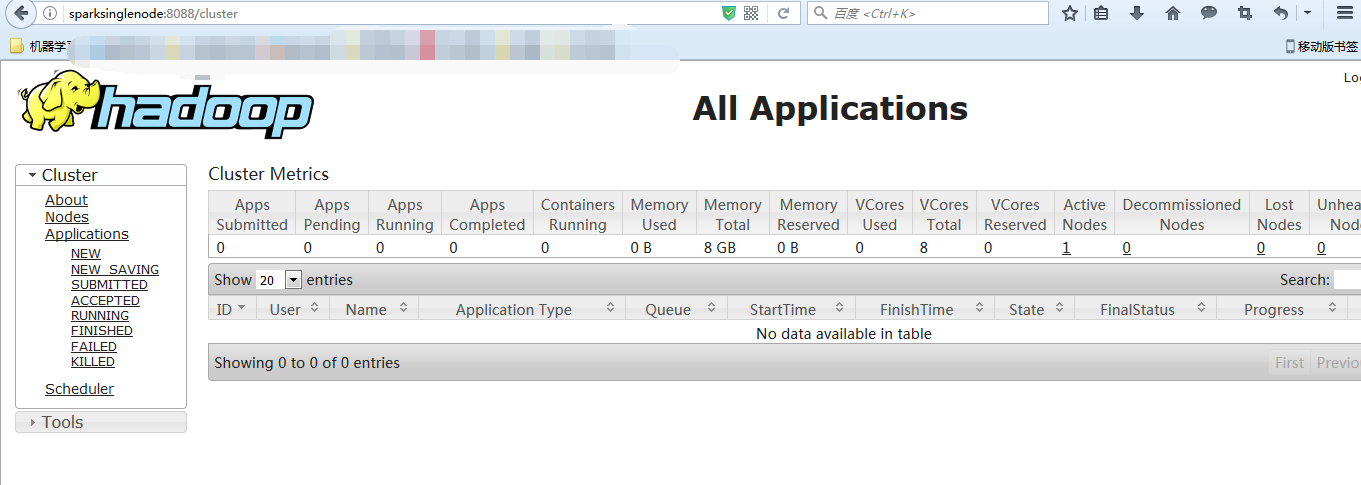
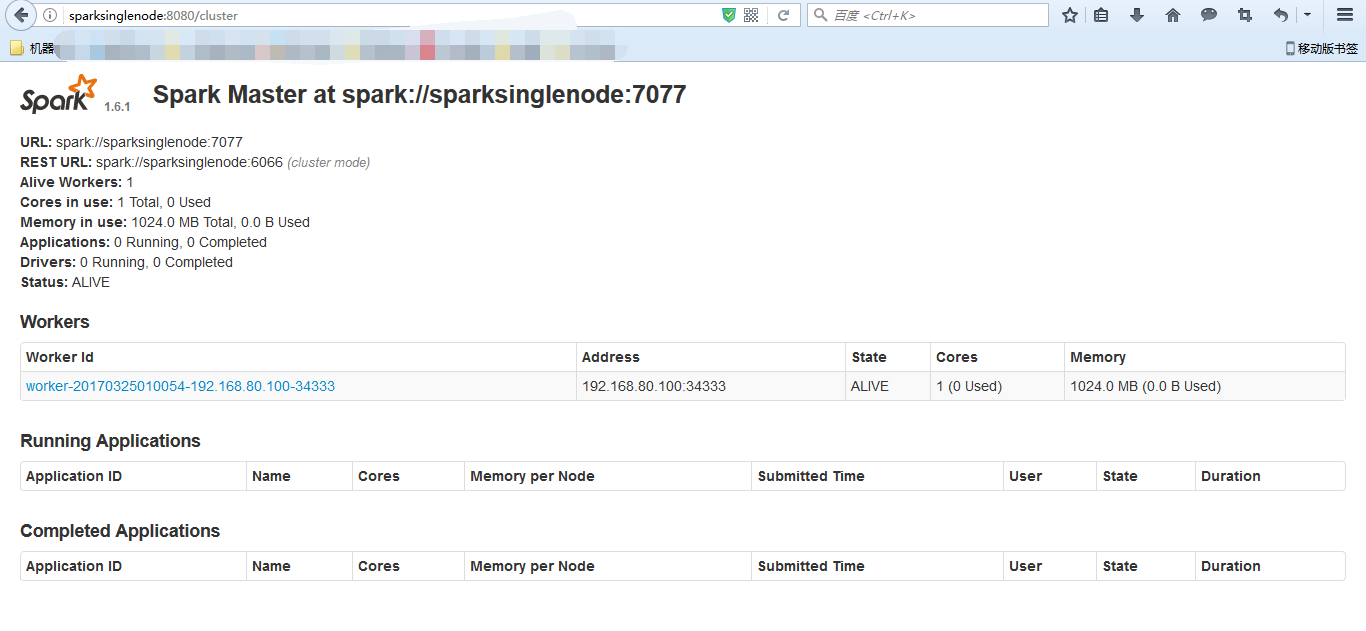
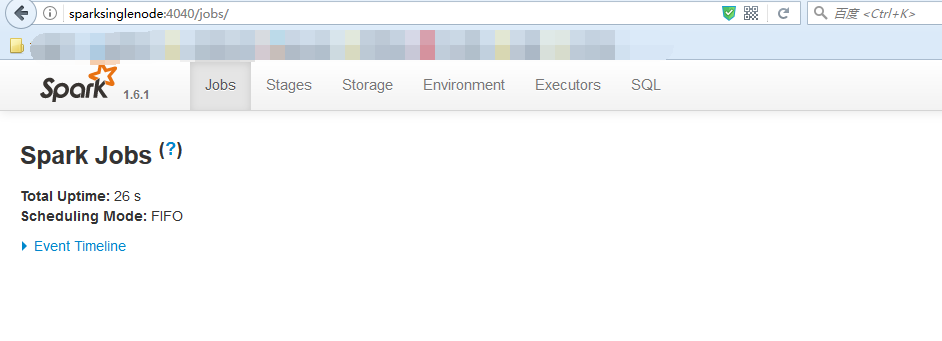
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡